






点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
红豆生南国,春来发几枝。
大家好,我是Python进阶者。
一、前言
前几天在Python最强王者交流群【钟爱一生】问了一个Python自动化办公的问题,问题如下:not well-formed (invalid token): line 3, column 74593各位老师,读取excel文件时,有这个报错,应该怎么解决?
代码如下:
import os
import pandas as pd
import tkinter as tk
from tkinter import filedialog
from tkinter import messagebox
from tkinter import ttk
import subprocess
import sys
from collections import deque
from openpyxl.utils.exceptions import InvalidFileException
def install_package(package):
subprocess.check_call([sys.executable, "-m", "pip", "install", package])
try:
import openpyxl
except ImportError:
install_package("openpyxl")
import openpyxl
def update_progress(progress):
progressbar["value"] = progress
root.update_idletasks()
def browse_file(entry_listbox):
file_paths = filedialog.askopenfilenames()
entry_listbox.delete(0, tk.END) # 删除所有条目
if len(file_paths) > 1:
merged_path = '...'.join(file_paths[:2]) + f' ({len(file_paths)} files)'
entry_listbox.insert(tk.END, merged_path) # 将选择的文件路径插入到Listbox中
else:
entry_listbox.insert(tk.END, file_paths[0]) # 只显示第一个选择的文件路径
# 设置Listbox的高度为1,无论选择了多少文件
entry_listbox.config(height=1)
# def execute():
# inventory_df_paths = inventory_df_entry.get(0, tk.END).strip().split("\n")
# transactions_df = transactions_df_entry.get(0, tk.END)
# output_file_path = output_entry.get(0, tk.END)
#
# if not inventory_df_paths or not transactions_df or not output_file_path:
# messagebox.showwarning("警告", "请提供所有必要的文件和文件夹路径!")
# else:
# # 读取所有库存现有量文件的数据
# inventory_dfs = []
# for inventory_df_path in inventory_df_paths:
# inventory_df = pd.read_excel(inventory_df_path, parse_dates=['生产日期'])
# inventory_dfs.append(inventory_df)
def execute():
inventory_df_paths = inventory_df_entry.get(0, tk.END)
inventory_df_paths = [path.strip() for path in inventory_df_paths]
transactions_df = transactions_df_entry.get(0, tk.END)
output_file_path = output_entry.get(0, tk.END)
selected_paths = inventory_df_entry.get(0, tk.END) # 获取选定的文件路径元组
inventory_df_paths = []
for path in selected_paths:
path = path.strip()
print(f"正在读取文件:{path}")
try:
pd.ExcelFile = pd.ExcelFile.__module__ + ".openpyxl" #添加此语句,使pandas默认采用openpyxl作为Excel解析
df = pd.read_excel(path, parse_dates=['生产日期'], engine="openpyxl")
inventory_df_paths.append(df)
print("读取成功")
except Exception as e:
print(f"读取文件时出现错误:{str(e)}")
transactions_df = transactions_df_entry.get(0, tk.END)
output_file_path = output_entry.get(0, tk.END)
if not inventory_df_paths or not transactions_df or not output_file_path:
messagebox.showwarning("警告", "请提供所有必要的文件和文件夹路径!")
else:
progressbar["value"] = 0 # 将进度条重置为0
root.update_idletasks()
check_fifo_rules(inventory_df_paths, transactions_df, output_file_path)
# 合并所有库存现有量数据为一个 DataFrame
inventory_df = pd.concat(inventory_df_paths)
# 函数:检查FIFO规则
def check_fifo_rules(inventory_df, transactions_df, output_file_path):
try:
# 确保操作日期和生产日期仅包含日期部分
transactions_df['操作时间'] = transactions_df['操作时间'].dt.date
transactions_df['生产日期'] = transactions_df['生产日期'].dt.date
# 初始化检查列
transactions_df['出入库FIFO'] = True
transactions_df['库存FIFO'] = True
# Step 1: 检查出入库表中的FIFO规则
for (material, warehouse), group in transactions_df.groupby(['物料编码', '仓库编码']):
group = group[group['操作代码'] == '出库'].sort_values(by=['操作时间', '生产日期'])
sliding_window = []
indices_to_update_false = set()
indices_to_update_true = set()
for i, row in group.iterrows():
row_operation_date = row['操作时间']
row_production_date = row['生产日期']
for j in range(1, len(sliding_window)):
prev_record = sliding_window[-j]
second_prev_record = sliding_window[-j - 1] if j < len(sliding_window) else None
if not pd.isnull(row_production_date) and second_prev_record is not None:
if row_production_date == prev_record['生产日期'] == second_prev_record['生产日期']:
indices_to_update_true.update({i, prev_record['index'], second_prev_record['index']})
if (row_operation_date == prev_record['操作时间'] > second_prev_record['操作时间'] and
row_production_date == prev_record['生产日期'] < second_prev_record['生产日期']):
indices_to_update_false.update({i, prev_record['index'], second_prev_record['index']})
if sliding_window:
previous_record = sliding_window[-1]
if row_operation_date > previous_record['操作时间']:
if not pd.isnull(row_production_date) and not pd.isnull(
previous_record['生产日期']) and row_production_date < previous_record['生产日期']:
indices_to_update_false.update({i, previous_record['index']})
if row_operation_date == previous_record['操作时间']:
if row_production_date == previous_record['生产日期']:
for k in range(len(sliding_window) - 1):
prev_record = sliding_window[-k - 2]
if not pd.isnull(row_production_date) and not pd.isnull(prev_record['生产日期']):
if row_production_date < prev_record['生产日期']:
indices_to_update_false.update({i, previous_record['index']})
if row_operation_date != previous_record['操作时间']:
if row_production_date == previous_record['生产日期']:
for k in range(len(sliding_window) - 1):
prev_record = sliding_window[-k - 2]
if not pd.isnull(row_production_date) and not pd.isnull(prev_record['生产日期']):
if row_production_date == prev_record['生产日期']:
indices_to_update_true.update({i, previous_record['index']})
sliding_window.append({
'index': i,
'操作时间': row_operation_date,
'生产日期': row_production_date
})
if len(sliding_window) > 3:
sliding_window.pop(0)
transactions_df.loc[indices_to_update_false, '出入库FIFO'] = False
transactions_df.loc[indices_to_update_true, '出入库FIFO'] = True
# Step 2: 检查出库记录与库存表中的FIFO规则
for (material, warehouse), group in transactions_df.groupby(['物料编码', '仓库编码']):
fifo_queue = inventory_df[(inventory_df['物料编码'] == material) & (inventory_df['仓库编码'] == warehouse)]
fifo_queue = fifo_queue.sort_values(by='生产日期')
earliest_production_date = fifo_queue['生产日期'].min()
for i, row in group[group['操作代码'] == '出库'].sort_values(by='操作时间').iterrows():
if not pd.isnull(earliest_production_date) and not pd.isnull(row['生产日期']) and row[
'生产日期'] > earliest_production_date:
transactions_df.loc[i, '库存FIFO'] = False
# 合并两个检查结果
transactions_df['是否符合FIFO'] = transactions_df['出入库FIFO'] & transactions_df['库存FIFO']
# 标红不符合FIFO规则的记录
def highlight_rule(val):
return 'background-color: red' if not val else ''
styled_transactions_df = transactions_df.style.applymap(highlight_rule, subset=['是否符合FIFO'])
# 函数:保存标红后的表格为Excel文件
def save_to_excel(filename, transactions_df):
styled_transactions_df = transactions_df.style.apply(lambda x: [highlight_rule(v) for v in x],
subset=['是否符合FIFO'])
output_folder = os.path.dirname(output_file_path)
if not os.path.exists(output_folder):
os.makedirs(output_folder)
styled_transactions_df.to_excel(output_file_path, index=True)
update_progress(100) # 设置进度条为100
messagebox.showinfo("完成", "核对完成,祝工作顺利!")
except Exception as e:
messagebox.showerror("错误", f"发生错误:{str(e)}")
# def browse_file(entry_var):
# file_path = filedialog.askopenfilename()
# entry_var.delete(0, tk.END) # 清空Text控件内容
# entry_var.insert(tk.END, file_path) # 将选择的文件路径插入到Text控件中
def browse_output_file(entry_var):
file_path = filedialog.asksaveasfilename(defaultextension=".xlsx", filetypes=[("Excel files", "*.xlsx"), ("Excel files", "*.xls")])
entry_var.delete(0, tk.END) # 清空Text控件内容
entry_var.insert(tk.END, file_path) # 将选择的文件路径插入到Text控件中
# def execute():
# inventory_df = inventory_df_entry.get(0, tk.END)
# transactions_df = transactions_df_entry.get(0, tk.END)
# output_file_path = output_entry.get(0, tk.END)
#
# if not inventory_df or not transactions_df or not output_file_path:
# messagebox.showwarning("警告", "请提供所有必要的文件和文件夹路径!")
# else:
# progressbar["value"] = 0 # 将进度条重置为0
# root.update_idletasks()
# check_fifo_rules(inventory_df, transactions_df, output_file_path)
# 创建主窗口
root = tk.Tk()
root.title("先进先出对比工具")
# 创建UI组件
inventory_df_label = tk.Label(root, text="选择库存现有量文件:")
inventory_df_entry = tk.Listbox(root, selectmode=tk.MULTIPLE, width=40, height=1)
inventory_df_button = tk.Button(root, text="浏览", command=lambda: browse_file(inventory_df_entry))
transactions_df_label = tk.Label(root, text="选择出入库文件:")
transactions_df_entry = tk.Listbox(root, selectmode=tk.MULTIPLE, width=40, height=1)
transactions_df_button = tk.Button(root, text="浏览", command=lambda: browse_file(transactions_df_entry))
output_label = tk.Label(root, text="选择输出文件:")
output_entry = tk.Listbox(root, selectmode=tk.MULTIPLE, width=40, height=1)
output_button = tk.Button(root, text="浏览", command=lambda: browse_output_file(output_entry))
execute_button = tk.Button(root, text="开始执行", command=execute)
progressbar = ttk.Progressbar(root, mode="determinate")
# 布局UI组件
inventory_df_label.grid(row=1, column=0, padx=10, pady=10, sticky=tk.W)
inventory_df_entry.grid(row=1, column=1, padx=10, pady=10)
inventory_df_button.grid(row=1, column=2, padx=10, pady=10)
transactions_df_label.grid(row=0, column=0, padx=10, pady=10, sticky=tk.W)
transactions_df_entry.grid(row=0, column=1, padx=10, pady=10)
transactions_df_button.grid(row=0, column=2, padx=10, pady=10)
output_label.grid(row=2, column=0, padx=10, pady=10, sticky=tk.W)
output_entry.grid(row=2, column=1, padx=10, pady=10)
output_button.grid(row=2, column=2, padx=10, pady=10)
execute_button.grid(row=3, column=0, columnspan=3, pady=20)
progressbar.grid(row=4, column=0, columnspan=3, padx=10, pady=10, sticky=tk.W+tk.E)
# 运行主循环
root.mainloop()二、实现过程
这里【莫生气】给了个思路如下:第三行看看有点问题,是表格报错还是 Python 报错,这看不出来。
后来【隔壁😼山楂】补充道:这个文件用pd.read_excel是可以直接读取的,不知道你这个报错是怎么出现的,麻烦发下截图@钟爱一生 。下面这个python代码需要其他的文件,不知道该怎么操作。
【钟爱一生】:很有意思,我只要第三行任何一个单元格复制粘贴为值,数据就能导进去,如果不做这一步就会报错。
【隔壁😼山楂 】:那可能是源文件有点小问题。
【钟爱一生】:或者我删除任一行,也能导进去,数据是公司系统里导出来的。
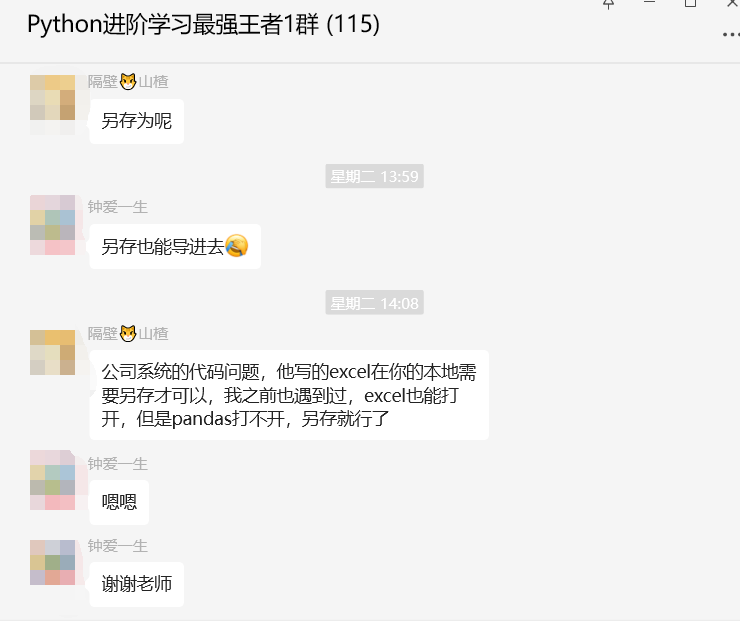
【隔壁😼山楂 】:另存为呢?
【钟爱一生】:另存也能导进去。
【隔壁😼山楂 】:公司系统的代码问题,他写的excel在你的本地需要另存才可以,我之前也遇到过,excel也能打开,但是pandas打不开,另存就行了。
【钟爱一生】:嗯嗯,谢谢老师。
顺利地解决了粉丝的问题。
如果你也有类似这种Python相关的小问题,欢迎随时来交流群学习交流哦,有问必答!
三、总结
大家好,我是Python进阶者。这篇文章主要盘点了一个Python自动化办公的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【钟爱一生】提出的问题,感谢【隔壁😼山楂】给出的思路,感谢【莫生气】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

大家在学习过程中如果有遇到问题,欢迎随时联系我解决(Python进阶者微信:2584914241),应粉丝要求,我创建了一些ChatGPT机器人交流群和高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。

------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~

















 27万+
27万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









