







 本文将介绍XPath在Python中的实战应用,通过pycharm执行代码,详细讲解如何使用XPath表达式有效地从网页中提取信息,帮助你掌握这一核心技术。
本文将介绍XPath在Python中的实战应用,通过pycharm执行代码,详细讲解如何使用XPath表达式有效地从网页中提取信息,帮助你掌握这一核心技术。
1、什么是Xpath
下面是度娘给出的解释:

2、Xpath常用语法
/ :一层一层地找
// :寻找当前页面所有的标签
text() :提取文本信息
@ :提取属性的内容
// :寻找当前页面所有的标签
text() :提取文本信息
@ :提取属性的内容
3、用xpath提取有道精品课网页里的app信息和下载网站(前提是要安装lxml库)
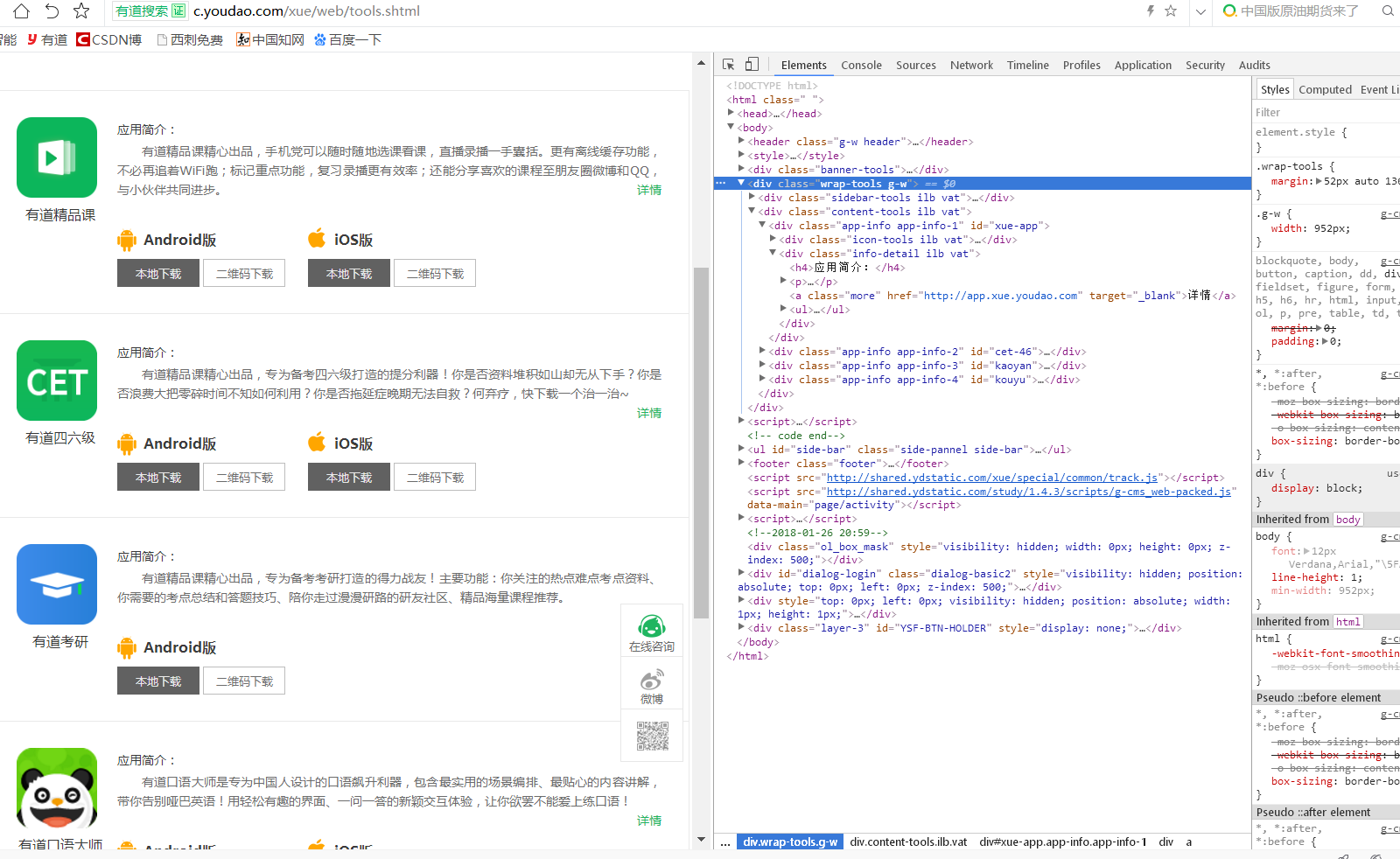
打开有道精品课网页,审查元素进行分析如下图
import urllib.request #urlopen
from lxml import etree #xpath
yuanma=urllib.request.urlopen("http://c.youdao.com/xue/web/tools.shtml")
html=yuanma.read()
selector = etree.HTML(html)
#提取四个app的应用信息
content = selector.xpath('//div[@class="content-tools ilb vat"] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1053
1053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









