







学习Pandas.DataFrame(2)
load csv(comma seperated variable) files to DataFrame and vice versa
upload csv files
read/write csv files
-
load data into jupyter notebook, create a new folder and then upload the csv files into it. (CSV = comma seperated variable) 文件格式如下:
Name,City,Country # first line is column names Seattle-Tacoma,Seattle,USA Dulles,Washington,USA Heathrow,London,United Kingdom Schiphol,Amsterdam,Netherlands Changi,Singapore,Singapore Pearson,Toronto,Canada Narita,Tokyo,Japan
-
Normal csv files:
dataframe = pd.read_csv(‘Folder/name.csv’)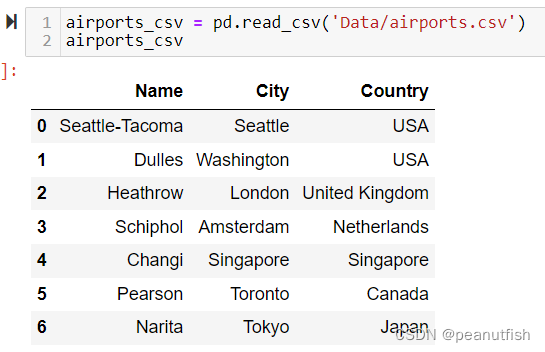
-
csv files had bad lines:
dataframe = pd.read_csv(‘Folder/name.csv’, on_bad_lines='skip')注意
error_bad_lines=False这个参数在pandas 1.3后就不用了第四行多了一个comma,直接读取会报错,加了
on_bad_lines='skip'后这一行就不会读取,另外如果有空值的地方会直接显示为
NaN
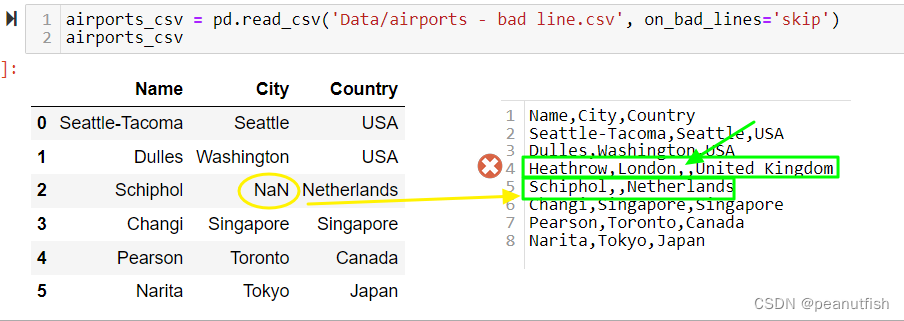
-
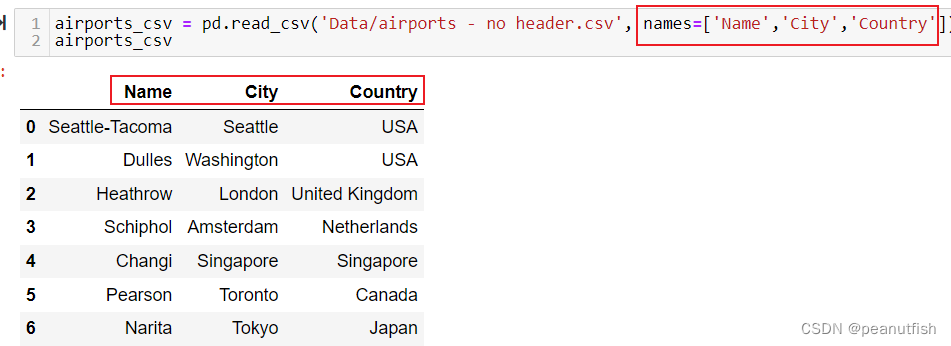
csv fiels do not have column headers:
dataframe = pd.read_csv(‘Folder/name.csv’, header=None)(column name变为0,1,2…)dataframe = pd.read_csv(‘Folder/name.csv’, header=None,Name=['name1','name2','name3'...])(Name参数指定column name)

-
将DataFrame 导出为csv files
dataframe.to_csv(‘NewName.csv’)– 默认会把行号也导入进去dataframe.to_csv(‘NewName.csv’, index=False)– 不导入行号

TO BE CONTINUED…















 1128
1128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









