







 本文深入解析搜索引擎中倒排索引的构建过程与工作原理,包括文档集合、单词编号、倒排列表等核心概念,以及如何通过倒排索引提高搜索效率。
本文深入解析搜索引擎中倒排索引的构建过程与工作原理,包括文档集合、单词编号、倒排列表等核心概念,以及如何通过倒排索引提高搜索效率。
0.召回相关的概念
召回(Recall):在搜索排序系统中,需要首先从全集商品中,选择一部分商品,用来展示给用户,这个选择的过程称之为召回。
文档(Document):一般搜索引擎的处理对象是互联网网页,而文档这个概念要更宽泛些,代表以文本形式存在的存储对象,相比网页来说,涵盖更多种形式,比如Word,PDF,html,XML等不同格式的文件都可以称之为文档。再比如一封邮件,一条短信,一条微博也可以称之为文档。在本书后续内容,很多情况下会使用文档来表征文本信息。
文档集合(Document Collection):由若干文档构成的集合称之为文档集合。比如海量的互联网网页或者说大量的电子邮件都是文档集合的具体例子。
文档编号(Document ID):在搜索引擎内部,会将文档集合内每个文档赋予一个唯一的内部编号,以此编号来作为这个文档的唯一标识,这样方便内部处理,每个文档的内部编号即称之为“文档编号”,后文有时会用DocID来便捷地代表文档编号。
单词编号(Word ID):与文档编号类似,搜索引擎内部以唯一的编号来表征某个单词,单词编号可以作为某个单词的唯一表征。
倒排索引(Inverted Index):倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
单词词典(Lexicon):搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
1.先看为什么要建立倒排索引
举个例子,当用户在主页上搜索关键词“华为手机”时,假设只存在正向索引(forward index),那么就需要扫描索引库中的所有文档,找出所有包含关键词“华为手机”的文档,再根据打分模型进行打分,排出名次后呈现给用户。因为互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。
所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
2.怎么建立倒排索引
1)创建文档列表:
首先对原始文档数据进行编号(DocID),形成列表,就是一个文档列表
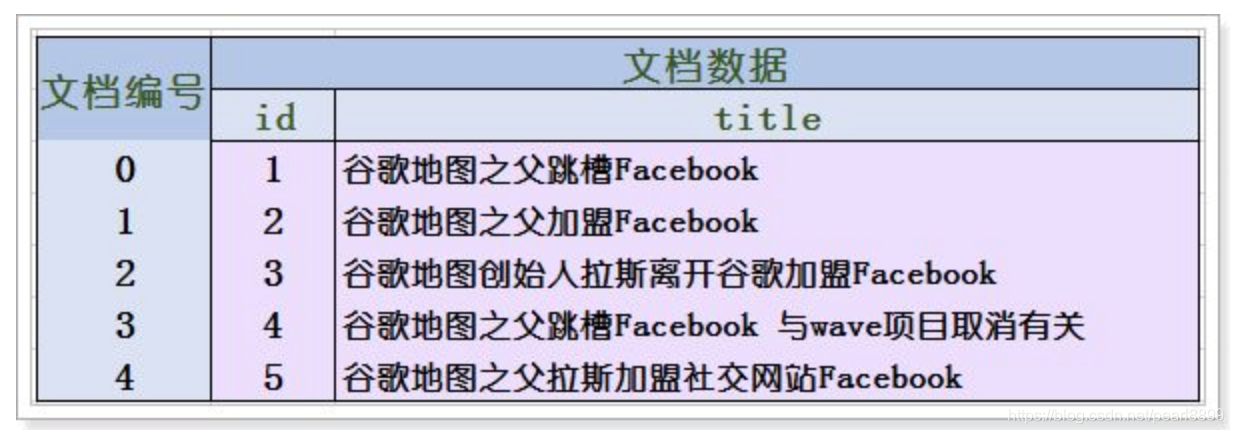
2)创建倒排索引列表
对文档中数据进行分词,得到词条。对词条进行编号,以词条创建索引。然后记录下包含该词条的所有文档编号(及其它信息)。
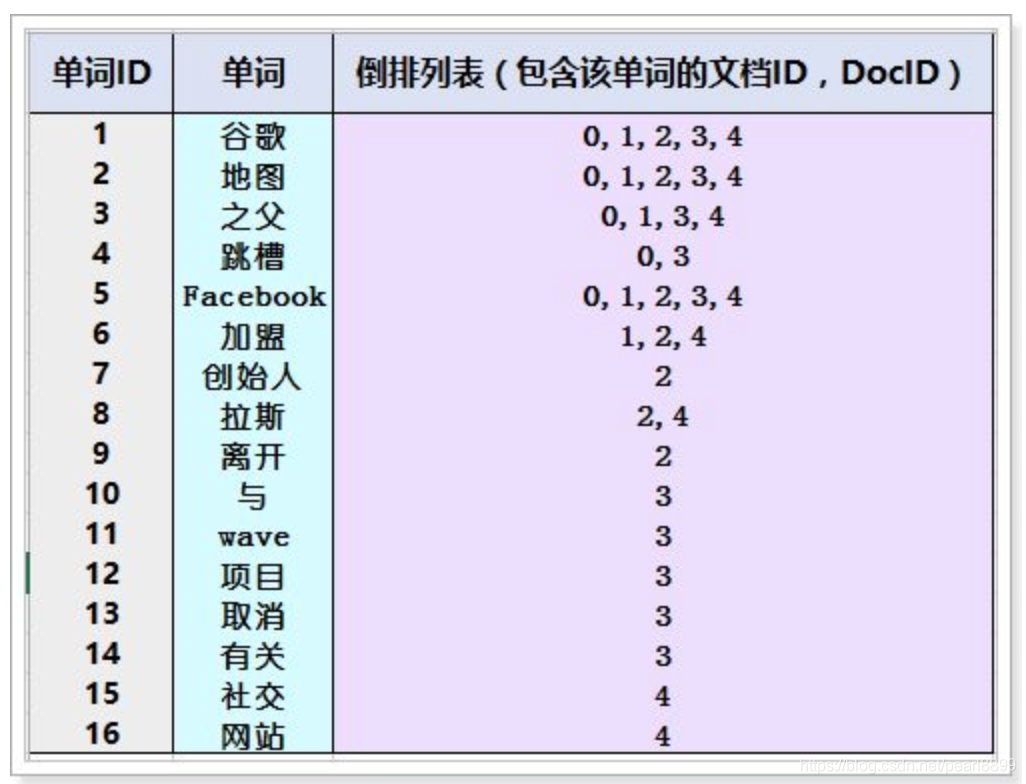
搜索的过程:
当用户输入任意的词条时,首先对用户输入的数据进行分词,得到用户要搜索的所有词条,然后拿着这些词条去倒排索引列表中进行匹配。找到这些词条就能找到包含这些词条的所有文档的编号(就是上图中的第三列,倒排列表)。
然后根据这些编号去文档列表中找到文档。
thinking:
在搜索业务中,会有搜索词,根据搜索词找到索引,那么在推荐场景中,没有搜索词,怎么召回?如果是基于LBS的业务场景,可以根据距离进行距离内的全部商品召回;或者加入多样性,根据user最近点击的商品,召回根该商品相似的商品作为召回返回结果。
参考:

















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









