






文章目录
一、Domain Shift
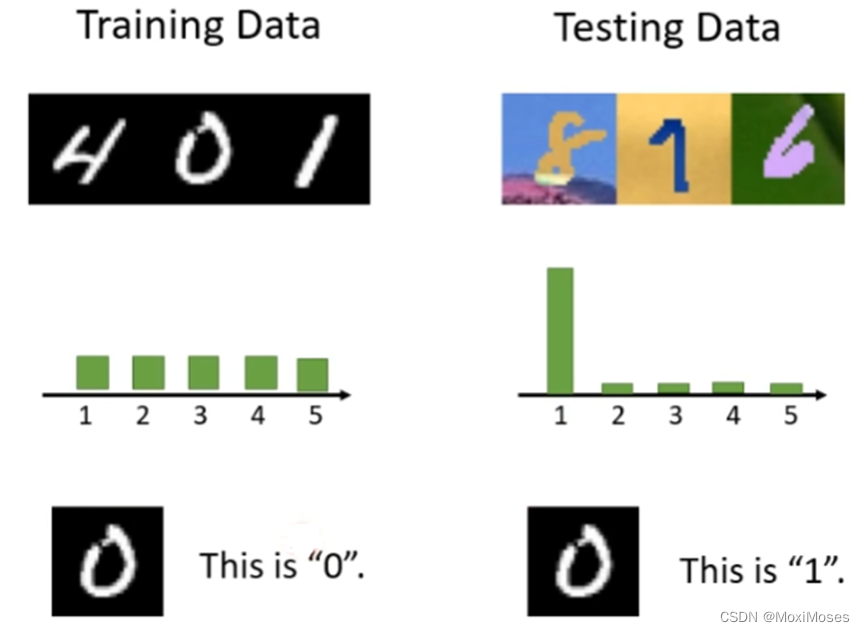
如下图所示,有几种Domain Shift的情况。第一种是在训练资料上是黑白的数字图片,而测试资料上是彩色的数字图片;第二种是在训练过程中的输出分布非常平均,而测试过程中的输出分布比较陡峭;最后一种是一张图片在训练资料中可能是“0”,而在测试资料中可能是“1”。在后面的内容中,就会用第一种情况来进行说明。
二、Domain Adaptation
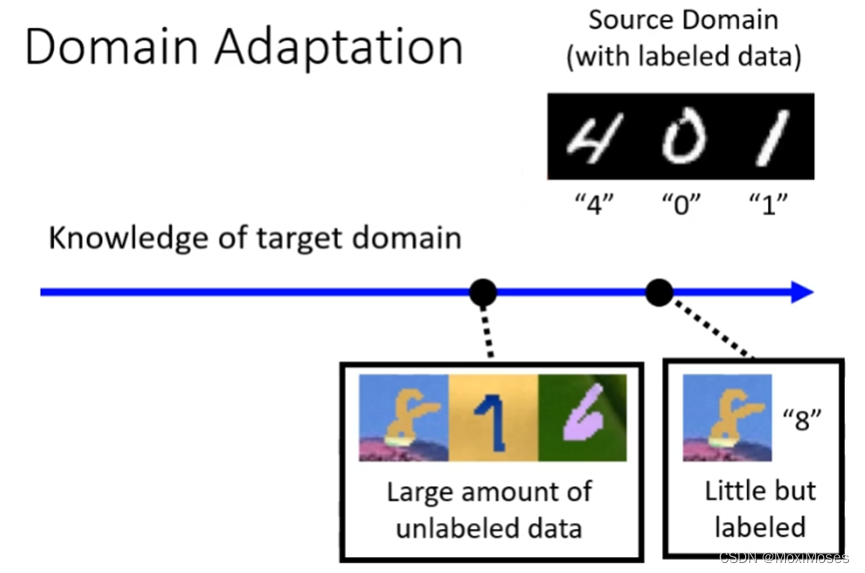
如下图所示,Target Domain(带有颜色的图片)上有大量的训练资料,但是我们不知道每个图片上面的数字是什么,现在的问题是怎么把Target Domain的资料用在Source Domain上,训练出一个模型,然后用在Target Domain上?
三、Basic Idea
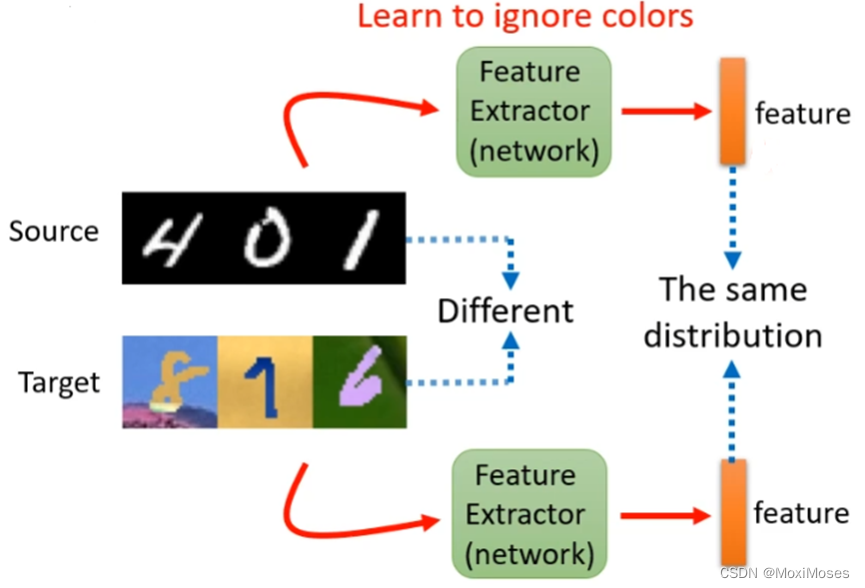
现在的想法是有一个Feature Extractor,它会忽视掉Source Domain和Target Domain中图片的颜色,然后把图片作为输入,输出一个feature(Source Domain和Target Domain中相同的分布)。
四、Domain Adversarial Training
1. 如下图所示,我们把Source Domain中的图片输入到模型后,会得到正确的输出,但是现在的问题是把Target Domain中的图片输入后,我们怎么判断输出是否正确呢?解决方法是我们把Source Domain和Target Domain中的图片通过Feature Extractor得到的分布如果没有差异,即可以进行判断。
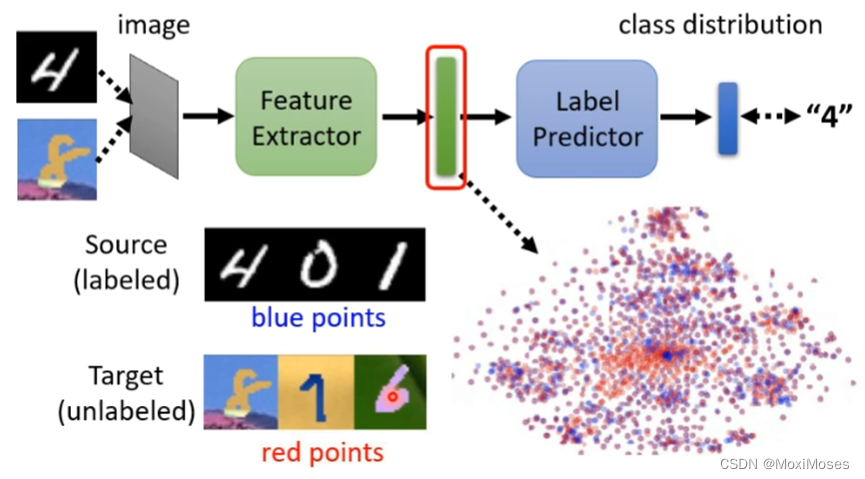
2. 于是我们训练一个Domain Classifier,让它无法分辨出Source Domain和Target Domain通过Feature Extractor后得到输出之间的差异。
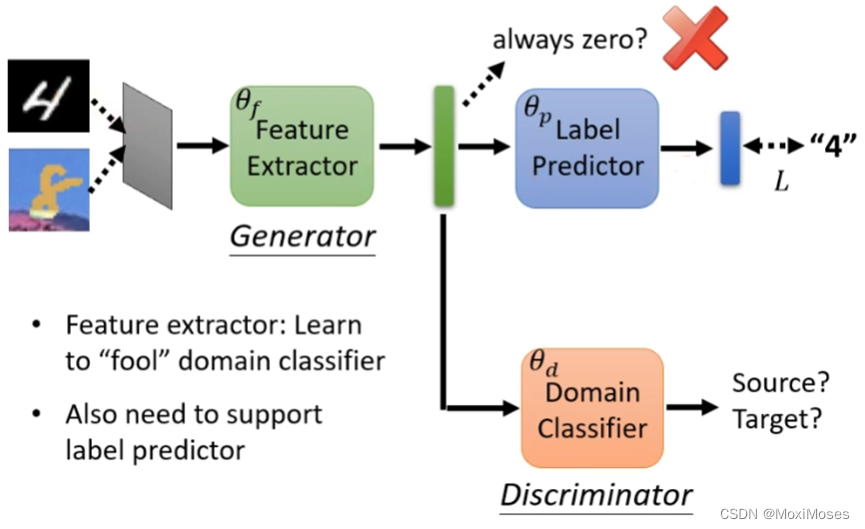
五、Considering Decision Boundary
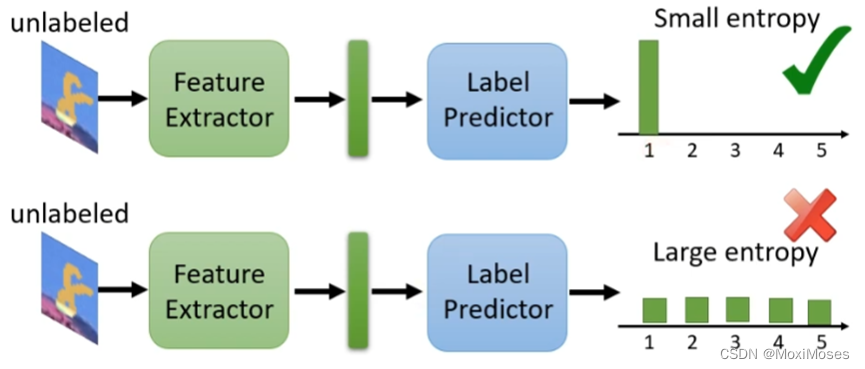
现在我们想要知道得到的分布是怎样的?如下图所示,我们希望将不知道label的图片输入到模型后得到的分布是在某一个区域集中的,也就是说希望得到的结果是Small entropy。















 519
519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









