







1.挑战:我们有一堆有标注的source domain资料,还有大量的无标注的target domain 资料。我们可以训练一个在source domain 上难免表现很出色的模型,但是当target domian和source domain的数据分布不一样时候,我们之前在source domian上面训练的模型,在target domain上面表现可能不是很好。如何解决这种问题呢?这就是Domain Adaptation要解决的问题。
2.解决思路:我们可以利用领域对抗训练的思路。如下图:
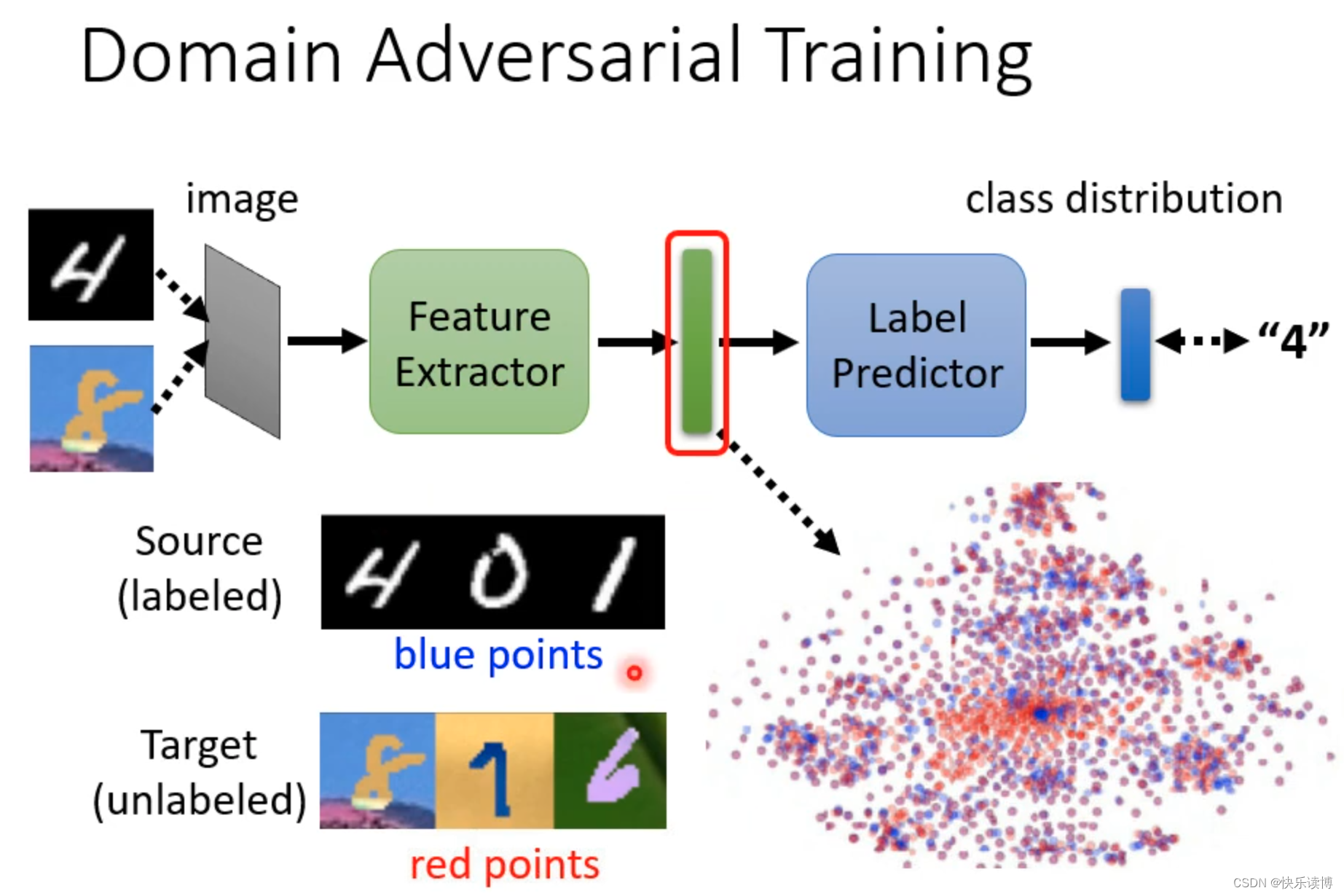
其中绿色长方形的代表我们从source domain和target domain提取的特征图(特征向量),我们要求来自两张图片(source domain 和target domain)出现的数据点(红色点和蓝色点)分布应该看起来一样,分不出差异。
如何做到使得两组数据点(来自source domian的蓝色点和target domain的红色点)分布相似呢?我们需要的是Domian Adeversarial Training(领域对抗训练) 如下图。
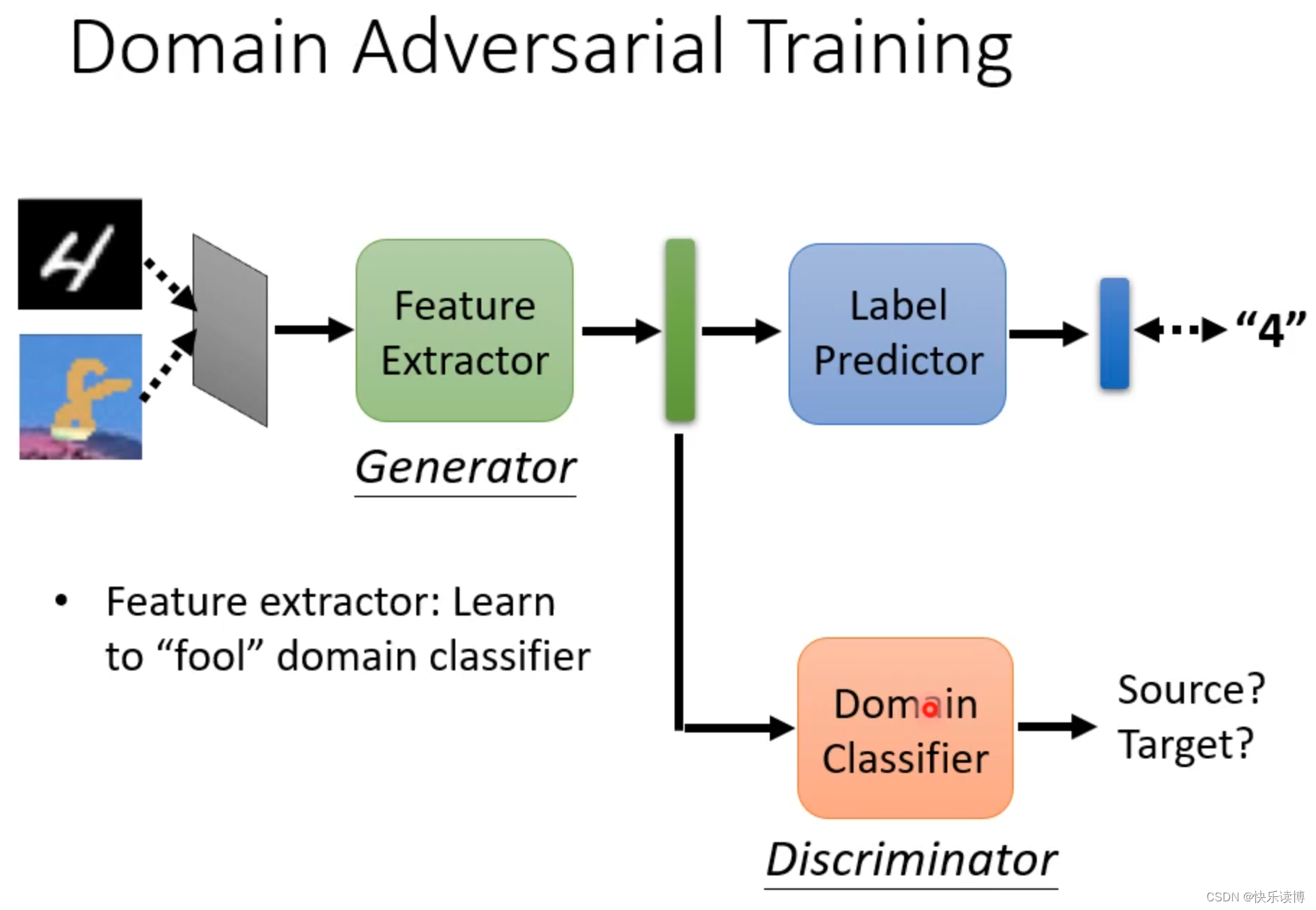
Domain Adversary training这和生成对抗网络的思路类似。他要求feature extractor 提取的两个领域的特征,让domain classifier分不出来。但是有一个问题就是如果特征提取器都提取全0向量的特征,那判别器肯定是无法区分了,但这不是我们想要的情况。那这种提取全0向量的情况会发生吗?(并不会,因为label predictor需要标签,所以会知道feature extrator提取有用的特征)
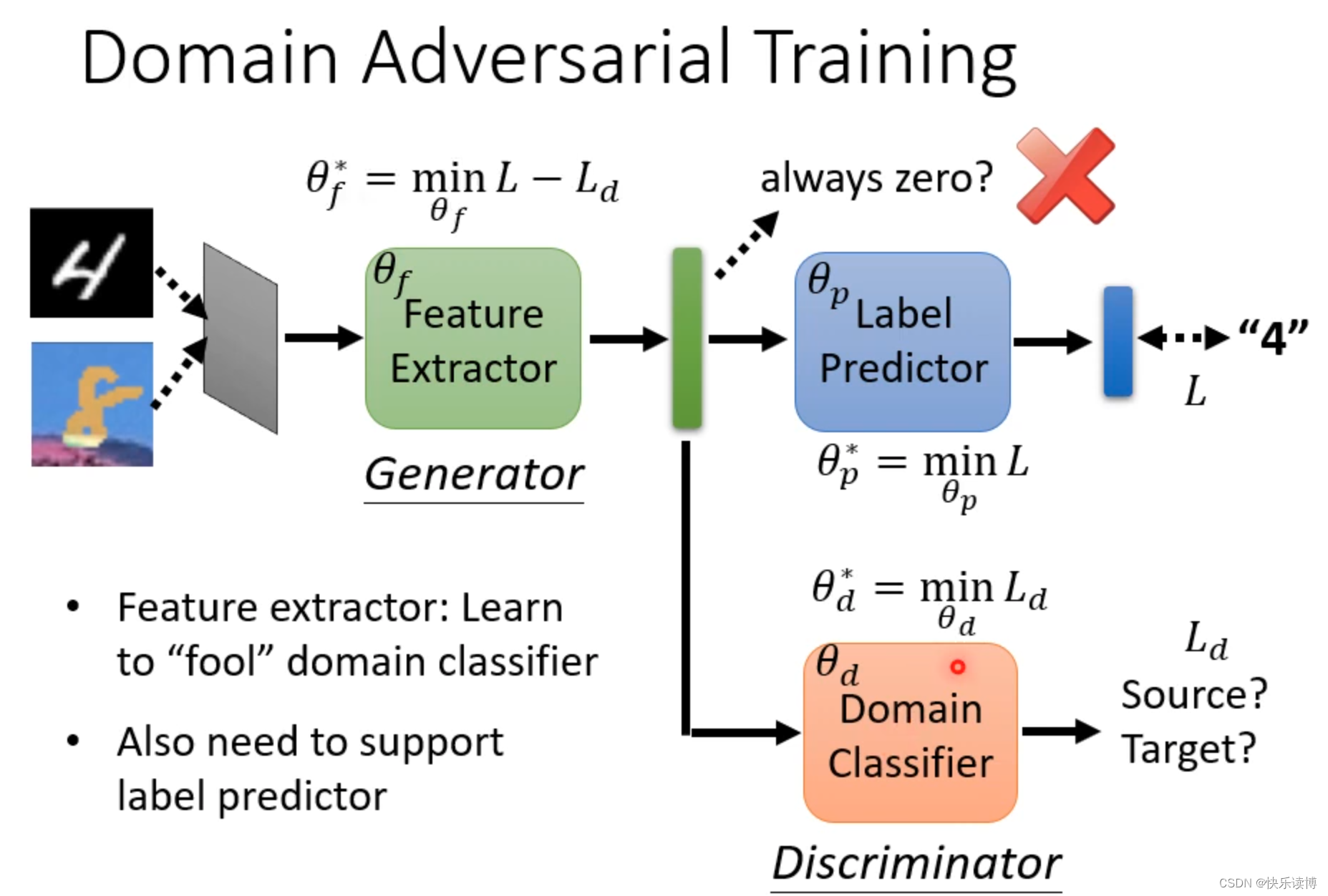
最开始的domain adversarial training做法(并不是最好的): 如上图,我们想通过label predictor将有标签的source domain data正确区分,其损失函数为:L,越小越好,即分类越正确越好。我们还需要一个domain claasifier 将两个领域source domian data和target domian data区分开来,其损失函数为:Ld,越小越好,越正确越好。最后feature extractor需要和label predictor站在同一战线,提取出让domian claasifier无法正确区分领域的特征,所以他的损失函数为:L-Ld。
原始论文如下:

上述方法的局限性:无法使得target data像source data有一样的分界线,如下图:
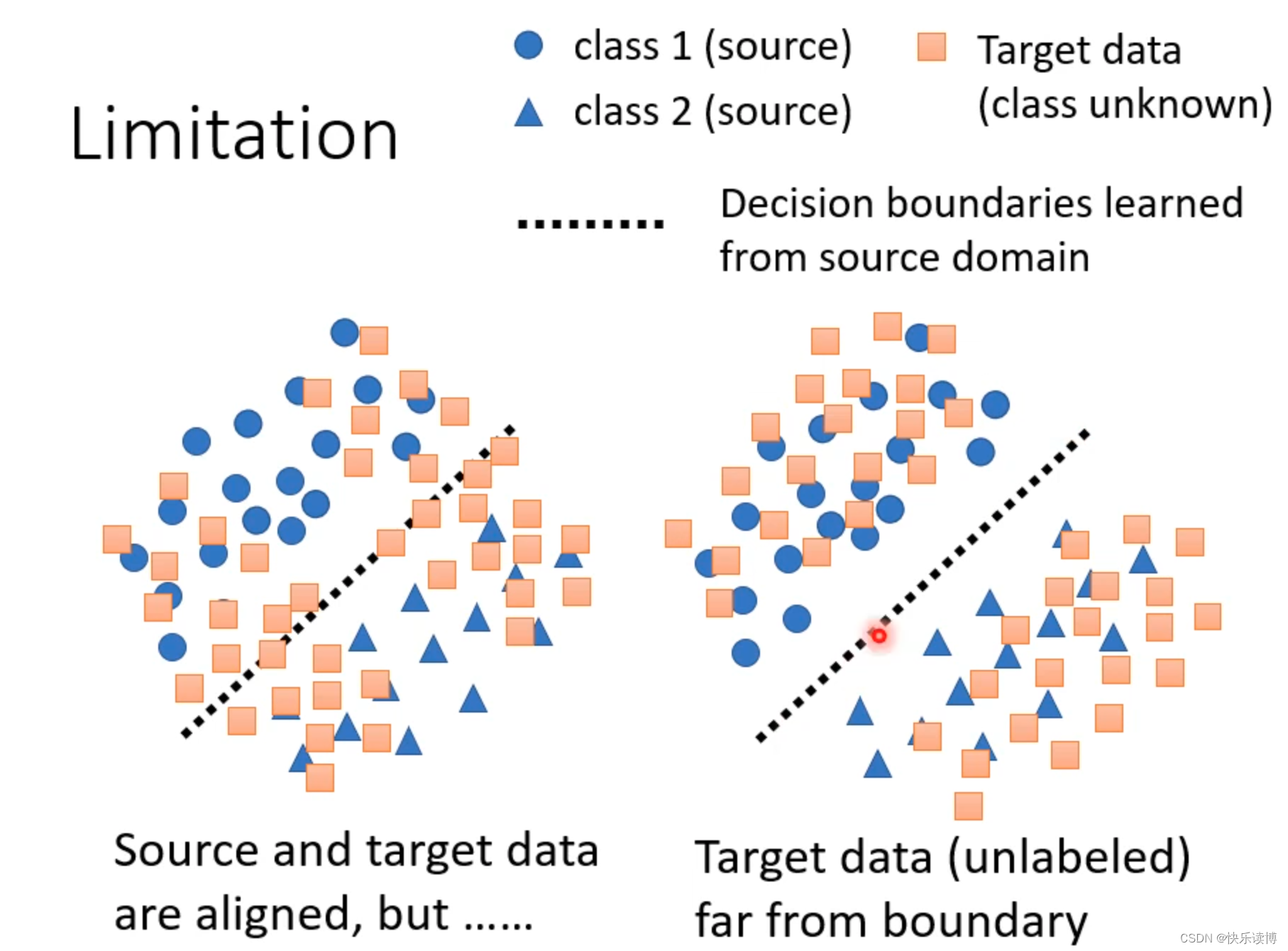
解决办法:如下图
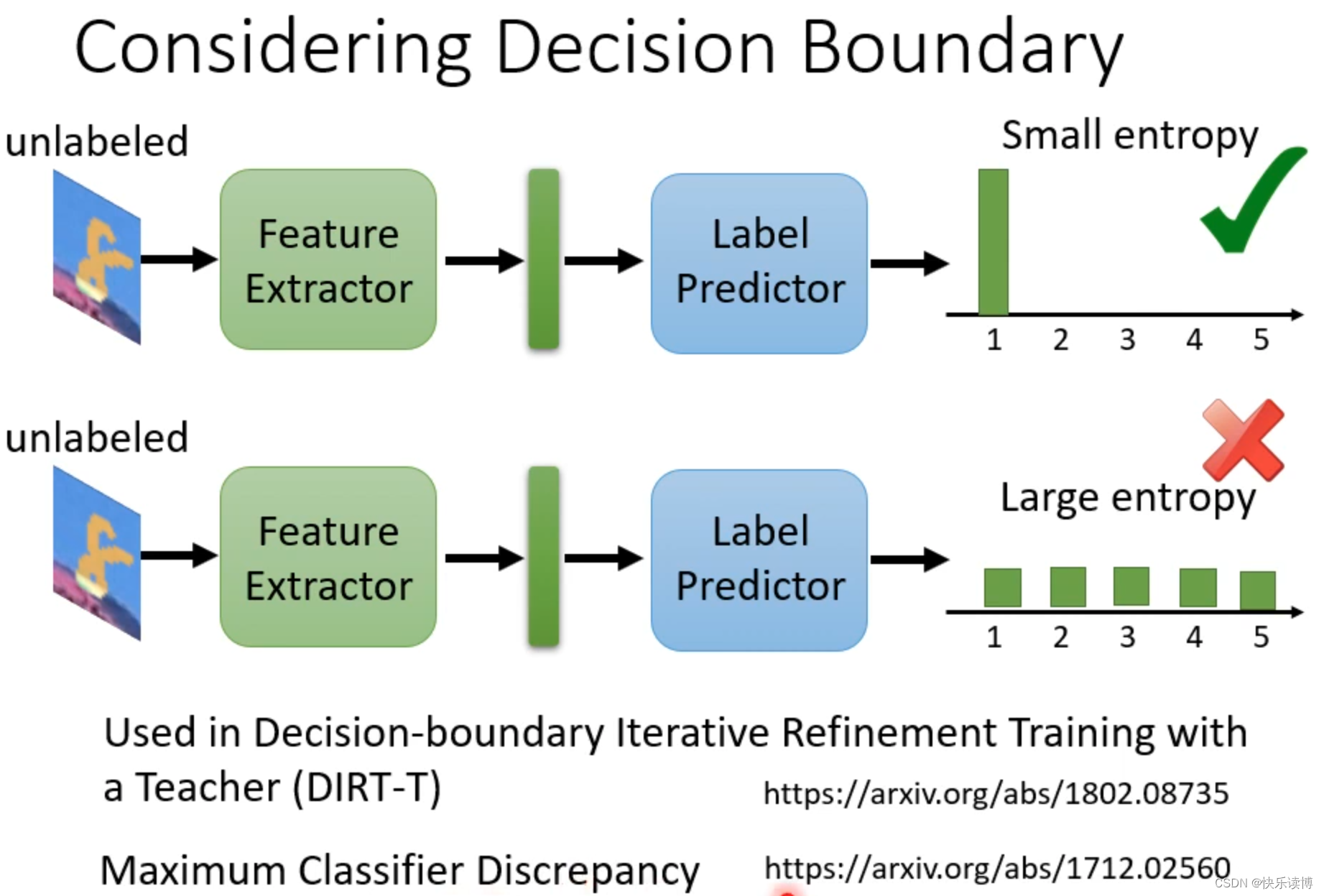
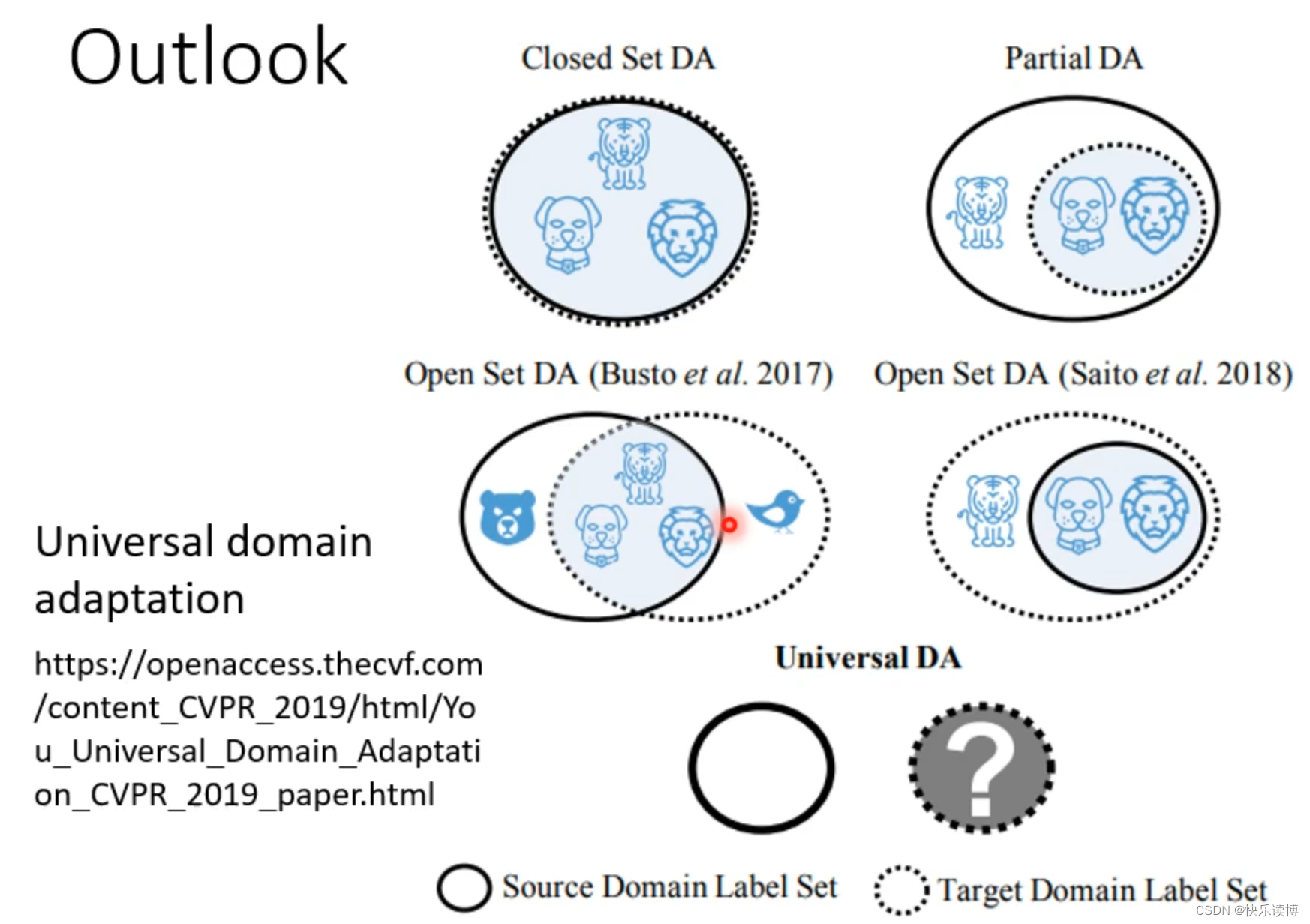
以上讨论的技术,都默认source domian data和target domian data的数据标签是相同的,但实际上,source domain和target domian不一定标签重合,如下图,还可能出现其他三种情况:
source domain类别多,target domian 类别少
source domain类别少,target domian 类别多
source domain类别和target domian 类别有重合但是也有不同。
可以参考Universal domian adaptation(cvpr2019年文章)
另外一个问题:假设target data只有一张图片(非常少)怎么办?
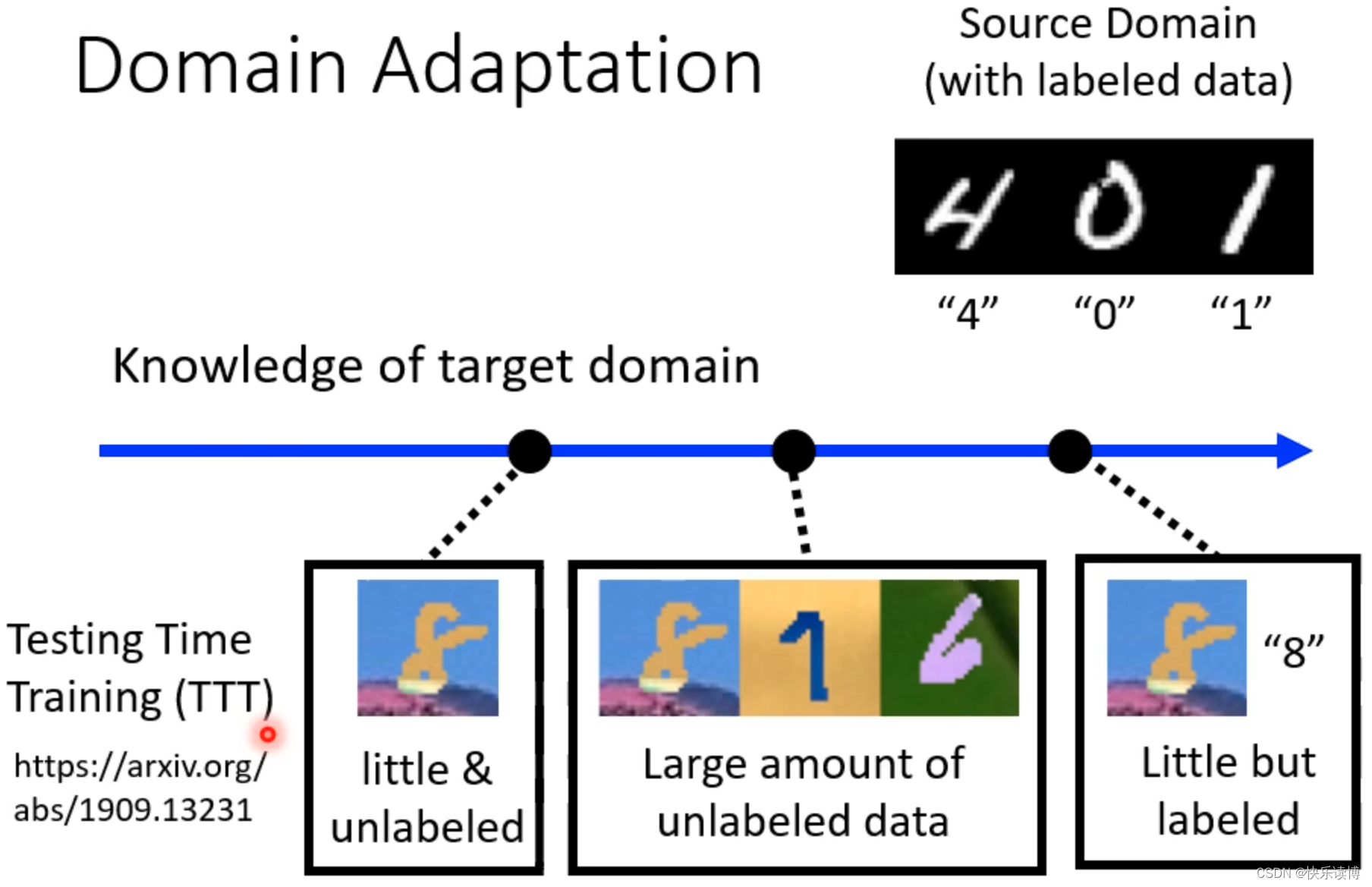
更严峻的挑战:如果对target domian基本不了解怎么办?
1.domian generalization
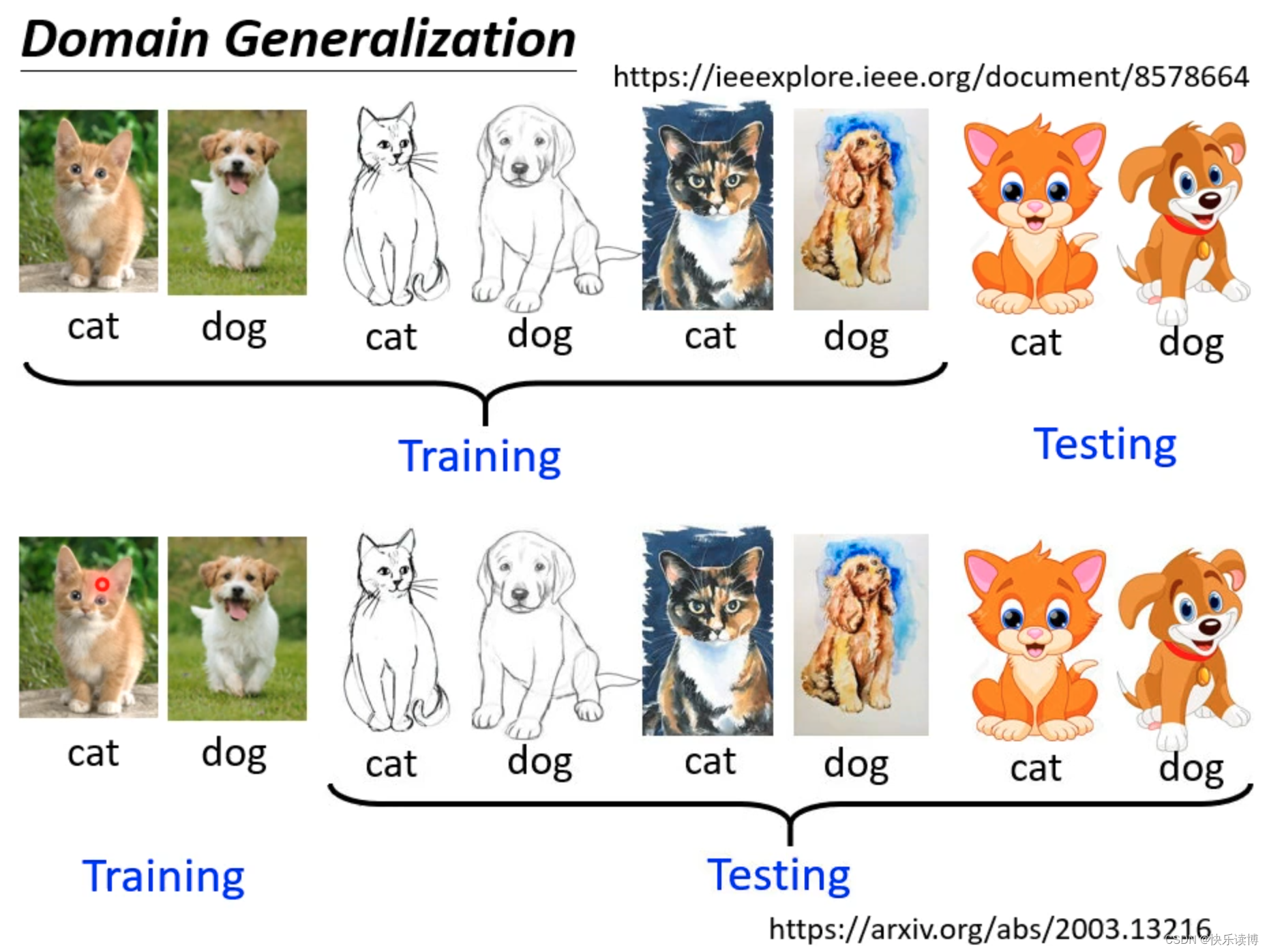
本文是观看李宏毅老师上课时的笔记。
后续我会阅读Universal domian adaptation(通用领自适应)


















 1676
1676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









