







本文基于Andrew_Ng的ML课程作业
1-K-means clustering used for simple two-dimensional datasets: K-means聚类用于简单二维数据集
导入库
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import loadmat函数:初始化聚类中心
def init_centroids(X,k): #初始化聚类中心
m,n=X.shape
centroids=np.zeros((k,n))
idx=np.random.randint(0,m,k) #np.random.randint(low,high=None,size=None):返回size规模在[low, high)范围内的随机整型数
for i in range(k):
centroids[i,:]=X[idx[i],:]
return centroids函数:找到每个样本最接近的聚类中心(Cluster Assignment)
def find_closet_centroids(X,centroids): #找到每个样本最接近的聚类中心(Cluster Assignment)
m=X.shape[0]
k=centroids.shape[0]
idx=np.zeros(m)
for i in range(m):
min_distan=1000000 #最小距离先设置为一个极大值
for j in range(k):
distan_squ=np.sum((X[i,:]-centroids[j,:])**2) #第i个样本到第j个centroid距离的平方
if distan_squ < min_distan:
min_distan=distan_squ
idx[i]=j+1
return idx函数:计算簇的聚类中心(分配给簇的所有样本的平均值)(Move Centroid)
def compute_centroids(X,idx,k): #计算簇的聚类中心(分配给簇的所有样本的平均值)(Move Centroid)
n=X.shape[1]
centroids=np.zeros((k,n))
for i in range(k):
indices=np.where(idx==i+1) #np.where(condition):条件成立时,where返回每个符合condition条件元素的坐标,以元组的形式
centroids[i,:]=(np.sum(X[indices,:],axis=1)/len(indices[0])) #np.sum(X,axis=1):X为[[[],[]]]时,axis=1表示每一列元素相加,列数不变 #len(list):行数;len(list[0]):列数
return centroids函数:加入循环整合后的K-means算法
def K_means(X,initial_centroids,max_iters): #加入循环整合后的K-means算法
k=initial_centroids.shape[0]
centroids=initial_centroids
for i in range(max_iters):
idx=find_closet_centroids(X,centroids)
centroids=compute_centroids(X,idx,k)
return idx,centroids函数:用三种不同颜色展示三种聚类
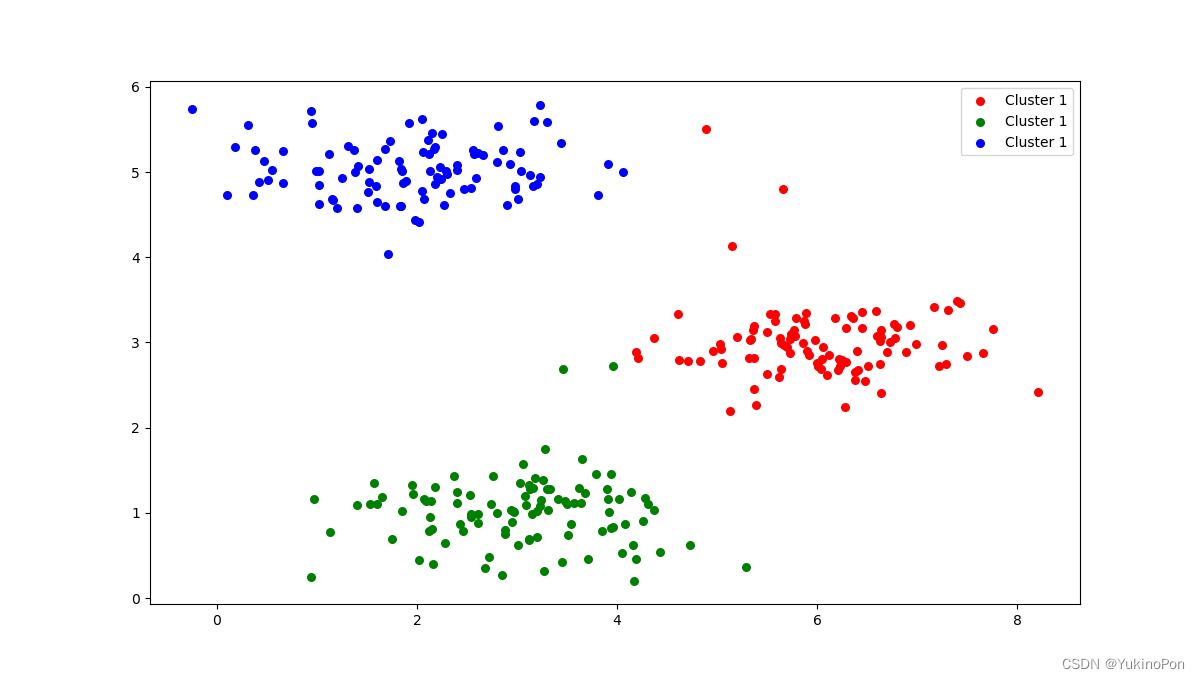
def plot_clusters(): #用三种不同颜色展示三种聚类
cluster1=X[np.where(idx==1)[0],:] #这里np.where()后要加[0]是因为返回的是多元素array,取第一个元素才是每个符合condition条件元素的坐标
cluster2=X[np.where(idx==2)[0],:]
cluster3=X[np.where(idx==3)[0],:]
fig,ax=plt.subplots(figsize=(12,8))
ax.scatter(cluster1[:,0],cluster1[:,1],s=30,color='r',label='Cluster 1')
ax.scatter(cluster2[:,0],cluster2[:,1],s=30,color='g',label='Cluster 1')
ax.scatter(cluster3[:,0],cluster3[:,1],s=30,color='b',label='Cluster 1')
ax.legend()
plt.show()主函数:
#K-means clustering used for simple two-dimensional datasets: K-means聚类用于简单二维数据集
data=loadmat('ex7data2.mat')
X=data['X'] #(300,2)
initial_centroids=init_centroids(X,3)
max_iters=10
idx,centroids=K_means(X,initial_centroids,max_iters)
plot_clusters()用三种颜色展示三种聚类
2-K-means clustering used for image compressing: K-means聚类用于压缩图像
导入库
from IPython.display import display,Image
from scipy.io import loadmat
import numpy as np
import matplotlib.pyplot as plt函数:初始化聚类中心
def init_centroids(X,k): #初始化聚类中心
m,n=X.shape
centroids=np.zeros((k,n))
idx=np.random.randint(0,m,k)
for i in range(k):
centroids[i,:]=X[idx[i],:]
return centroids函数:找到每个样本最接近的聚类中心(Cluster Assignment)
def find_closet_centroids(X,centroids): #找到每个样本最接近的聚类中心(Cluster Assignment)
m=X.shape[0]
k=centroids.shape[0]
idx=np.zeros(m)
for i in range(m):
min_distan=1000000
for j in range(k):
distan_squ=np.sum((X[i,:]-centroids[j,:])**2)
if distan_squ < min_distan:
min_distan=distan_squ
idx[i]=j+1
return idx函数:计算簇的聚类中心(分配给簇的所有样本的平均值)(Move Centroid)
def compute_centroids(X,idx,k): #计算簇的聚类中心(分配给簇的所有样本的平均值)(Move Centroid)
n=X.shape[1]
centroids=np.zeros((k,n))
for i in range(k):
indices=np.where(idx==i+1)
centroids[i,:]=(np.sum(X[indices,:],axis=1)/len(indices[0]))
return centroids函数:加入循环整合后的K-means算法
def K_means(X,initial_centroids,max_iters): #加入循环整合后的K-means算法
k=initial_centroids.shape[0]
centroids=initial_centroids
for i in range(max_iters):
idx=find_closet_centroids(X,centroids)
centroids=compute_centroids(X,idx,k)
return idx,centroids主函数:
#K-means clustering used for image compressing: K-means聚类用于压缩图像
#使用聚类找到最具代表性的16种少数颜色(16种选定颜色的RGB值),并使用聚类分配将原始的24位颜色映射到较低维的颜色空间
#在图像的直接24位颜色表示中,每个像素被表示为3个8位无符号整数(0~255),称为RGB编码
#原始图像的128×128像素位置中的每一个都需要24位(3x8),因此总大小为128×128×24=393216位;新的表示法需要以16种颜色的字典形式进行一些开销存储,每种颜色需要24位,但是图像本身只需要每个像素位置4位;因此最终使用的位数是16×24+128×128×4=65920位,相当于将原始图像压缩约6倍
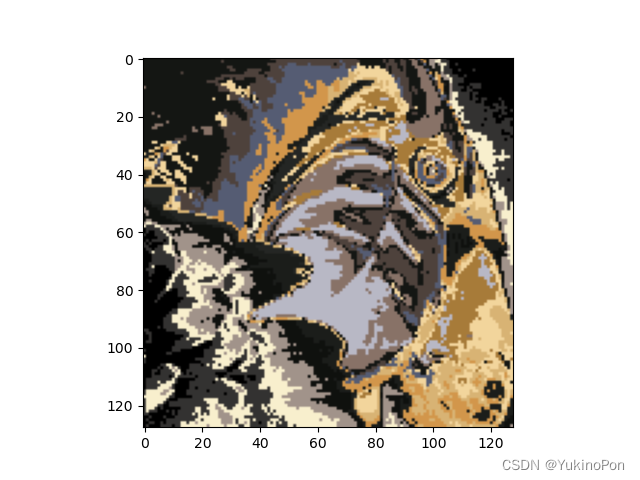
display(Image(filename='bird_small.png')) #IPython.display.display:显示图像(仅在Jupyter中可用) #IPython.display.Image:导入图像
image_data=loadmat('bird_small.mat')
A=image_data['A'] #A.shape=(128,128,3)表示数组有三个维度,可以理解为有128张纸,每张纸上有一个128*3的矩阵
#Data Preprocessing
A=A/255 #normalize value ranges
X=np.reshape(A,((A.shape[0]*A.shape[1]),A.shape[2])) #将A reshape成两维
initial_centroids=init_centroids(X,16)
max_iters=10
idx,centroids=K_means(X,initial_centroids,max_iters) #idx.shape=(16384,);centroids.shape=(16,3)
idx=find_closet_centroids(X,centroids) #上一次循环后有新的聚类中心但未对每个样本点进行附属,这一步就是新附属
X_recovered=np.zeros(X.shape)
for i in range(16):
X_recovered[idx==i]=centroids[i]
X_recovered=X_recovered.reshape(128,128,3)
plt.imshow(X_recovered) #plt.imshow(X):热图(heatmap)通过色差、亮度来展示数据的差异;X:(M,N,3):具有RGB值的图像(RGB值应该在浮点数[0,...,1]或整数[0,...,255])
plt.show()原图

压缩后图
3-K-means clustering in scikit-learn used for image compressing:K-means聚类用于压缩图像(用scikit-learn中的K-Means模型)
导入库
import numpy as np
import matplotlib.pyplot as plt
from skimage import io
from sklearn.cluster import KMeans主函数:
#K-means clustering in scikit-learn used for image compressing:K-means聚类用于压缩图像(用scikit-learn中的K-Means模型)
pic=io.imread('bird_small.png')/255 #(128,128,3) #skimage.io.imread(fname):图像读取,fname为文件名,这里图像读取进来就是RGB格式
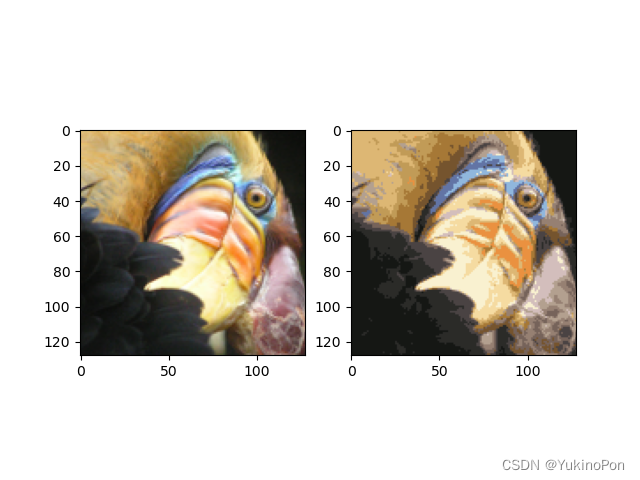
io.imshow(pic) #skimage.io.imshow(arr):图片显示1,arr为要显示的图像数组
io.show() ##skimage.io.show():图片显示2,相当于plt.show()
data=pic.reshape(128*128,3)
model=KMeans(n_clusters=16,n_init=100) #sklearn.cluster.KMeans(init=,max_iter=,n_clusters=,n_init=):n_clusters:聚类数量,即k值,默认为8;init:初始化聚类中心的方法,如需自定义设置,则传入ndarray格式的参数;n_init:用不同的初始化聚类中心运行算法的次数,默认为10,如自定义设置初始聚类中心,则为1;max_iter:最大迭代次数,默认300
model.fit(data)
centroids=model.cluster_centers_ #Kmeans.cluster_centers_:求取聚类中心
idx=model.predict(data) #求取样本属于哪个聚类的索引
compressed_pic=np.zeros(data.shape)
for i in range(16):
compressed_pic[idx==i]=centroids[i]
compressed_pic=compressed_pic.reshape(128,128,3)
fig,ax=plt.subplots(1,2)
ax[0].imshow(pic)
ax[1].imshow(compressed_pic)
plt.show()原始图和压缩后图对比
4-Principal Component Analysis used for dimensional reduction of simple two-dimensional datasets: PCA主成分分析用于简单二维数据集的降维
导入库
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import loadmat函数:实施PCA
def PCA(X): #实施PCA
#Data Preprocessing:Mean Normalization
X=(X-X.mean())/X.std()
#Compute covariance matrix
X=np.matrix(X) #(50,2)
cov=(X.T*X)/X.shape[0] #(2,2)
#Implement SVD
U,S,V=np.linalg.svd(cov) #np.linalg.svd(X):X维度(M,N),返回主成分矩阵U大小为(M,M),S(除了对角元素不为0其他元素都为0,作为一维矩阵返回)大小为(M,N),V大小为(N,N)
return U,S,V函数:选择主成分数量k
def Choose_k(X,S): #选择主成分数量k
for k in range(X.shape[1]):
variance=np.sum(S[:k+1])/np.sum(S[:])
if variance>0.99:
return k函数:将2维原始数据投射到1维空间中
def project_data(X,U,k): #将2维原始数据投射到1维空间中
Ureduce=U[:,:k] #(2,1)
z=Ureduce.T*X.T
return z.T函数:通过反向转换来恢复原始数据
def recover_data(Z,U,k): #通过反向转换来恢复原始数据
Ureduce=U[:,:k]
X_recovered=Ureduce*Z.T
return X_recovered.T主函数:
#Principal Component Analysis used for dimensional reduction of simple two-dimensional datasets: PCA主成分分析用于简单二维数据集的降维
data=loadmat('ex7data1.mat')
X=data['X']
U,S,V=PCA(X)
print(U,S,V)
k=Choose_k(X,S)
Z=project_data(X,U,k) #(50,1)
X_recovered=recover_data(Z,U,k)
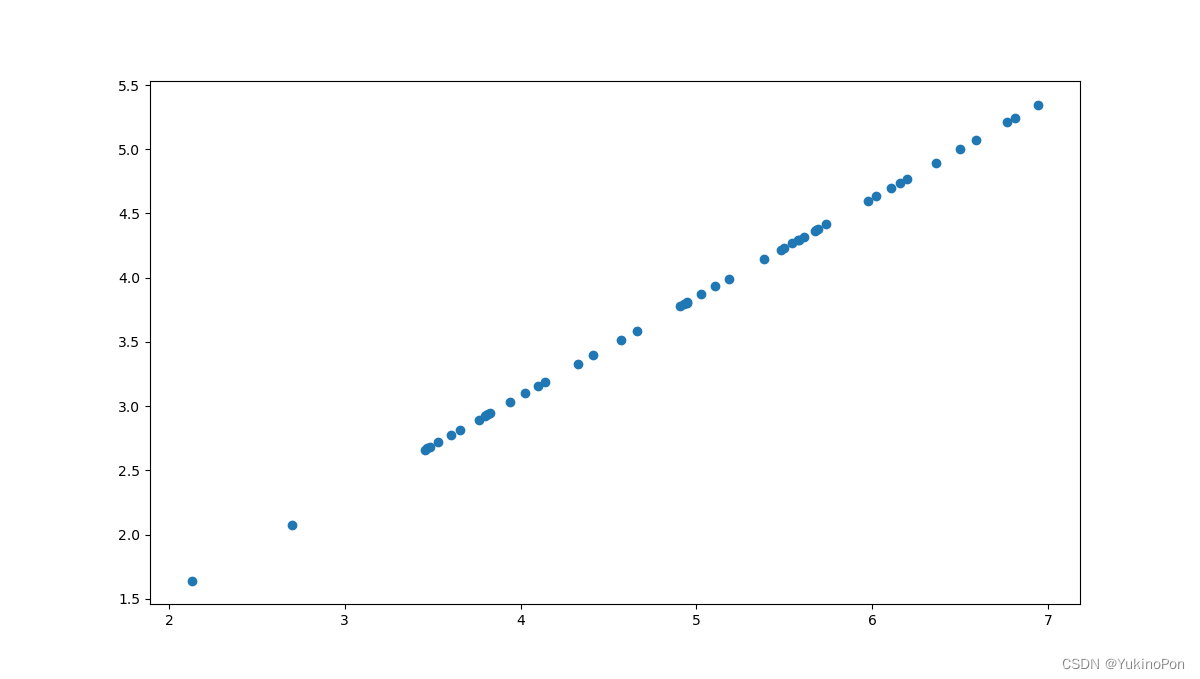
fig,ax=plt.subplots(figsize=(12,8))
ax.scatter(list(X_recovered[:,0]),list(X_recovered[:,1])) #list():将数据转换为列表类型 #这里转化成列表类型后画散点图否则报错
#第一主成分的投影轴基本上是数据集中的对角线,当我们将数据减少到一个维度时,我们失去了该对角线周围的变化,所以在再现中,一切都沿着该对角线
plt.show()U,S,V

原始数据图
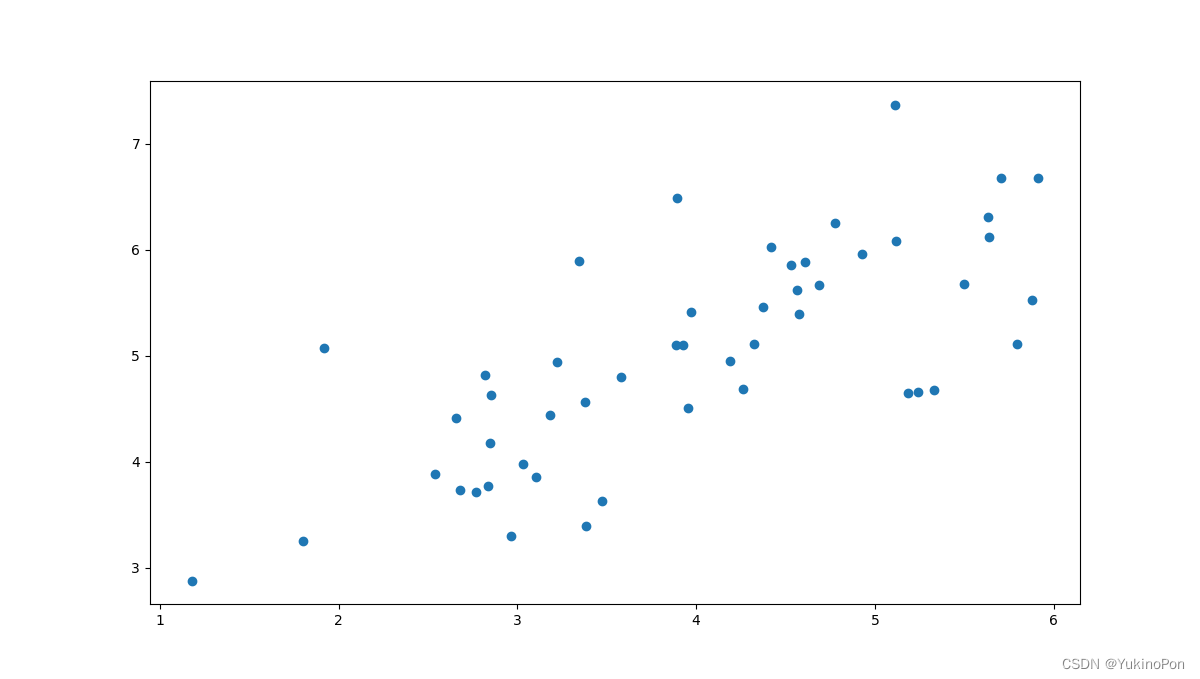
降维后再恢复的数据图
5-Principal Component Analysis used for dimensional reduction of face images: PCA主成分分析用于脸部图像数据集的降维
导入库
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import loadmat函数:实施PCA
def PCA(X): #实施PCA
X=(X-X.mean())/X.std()
X=np.matrix(X)
cov=(X.T*X)/X.shape[0]
U,S,V=np.linalg.svd(cov)
return U,S,V函数:选择主成分数量k
def Choose_k(X,S): #选择主成分数量k
for k in range(X.shape[1]):
variance=np.sum(S[:k+1])/np.sum(S[:])
if variance>0.99:
return k函数:将2维原始数据投射到1维空间中
def project_data(X,U,k): #将2维原始数据投射到1维空间中
Ureduce=U[:,:k]
z=Ureduce.T*X.T
return z.T函数:通过反向转换来恢复原始数据
def recover_data(Z,U,k): #通过反向转换来恢复原始数据
Ureduce=U[:,:k]
X_recovered=Ureduce*Z.T
return X_recovered.T函数:渲染数据集中前n张图像
def plot_n_image(X,n): #渲染数据集中前n张图像
images=X[:n,:]
pic_size=int(np.sqrt(X.shape[1])) #np.sqrt(x):开平方
grid_size=int(np.sqrt(n))
fig,ax=plt.subplots(ncols=grid_size,nrows=grid_size,figsize=(8,8))
for i in range(grid_size):
for j in range(grid_size):
ax[i][j].imshow(images[i*grid_size+j].reshape(pic_size,pic_size).T,cmap='OrRd_r') #将每张图reshape成32*32灰度的图像
ax[i][j].set_xticks([])
ax[i][j].set_yticks([])
plt.show()主函数:
#Principal Component Analysis used for dimensional reduction of face images: PCA主成分分析用于脸部图像数据集的降维
faces=loadmat('ex7faces.mat')
X=faces['X'] #(5000,1024)
plot_n_image(X,100)
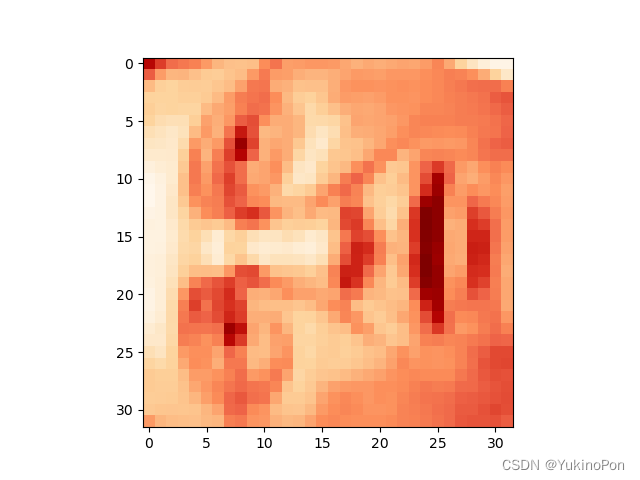
face=np.reshape(X[3,:],(32,32)) #渲染后的原图片
plt.imshow(face,cmap='OrRd_r')
plt.show()
U,S,V=PCA(X)
k=Choose_k(X,S)
print(k)
Z=project_data(X,U,100) #取k=100
X_recovered=recover_data(Z,U,100)
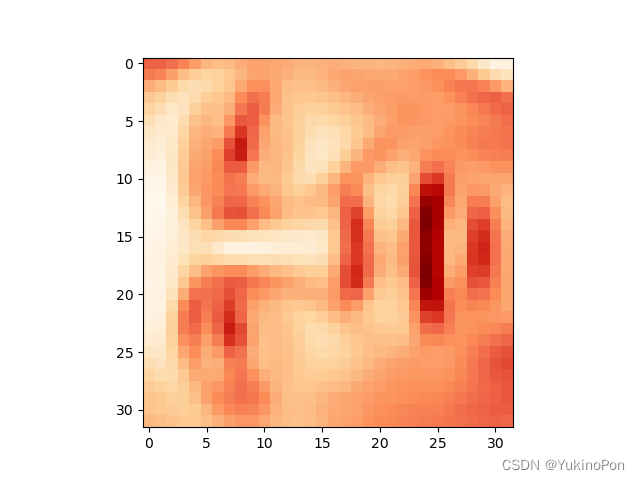
face=np.reshape(X_recovered[3,:],(32,32)) #使用PCA处理并渲染后的图片
plt.imshow(face,cmap='OrRd_r')
plt.show()主成分数量k
![]()
渲染后的前100张图像

使用PCA前渲染后的原图像
使用PCA处理并渲染后的图片















 2117
2117











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









