







 本文详细介绍了图像检索领域的关键评价指标mAP(mean Average Precision)及其变种mAP@k。mAP@k衡量的是在检索结果的前k张图片中查准率的平均值,而mAP则考虑所有结果,计算所有正样本的平均查准率。通过实例展示了如何计算mAP@k和mAP,并提供了相应的Python代码实现。
本文详细介绍了图像检索领域的关键评价指标mAP(mean Average Precision)及其变种mAP@k。mAP@k衡量的是在检索结果的前k张图片中查准率的平均值,而mAP则考虑所有结果,计算所有正样本的平均查准率。通过实例展示了如何计算mAP@k和mAP,并提供了相应的Python代码实现。
mAP ,mean Average Precision,平均检索精度.是图像检索领域最最常用的评价指标。
一、mAP@k、mAP
1.1 mAP@k
很多地方喜欢用这张图来解释,确实画的很好了,不过略有瑕疵,我稍微修改了一下。这张图是求mAP@10的结果。
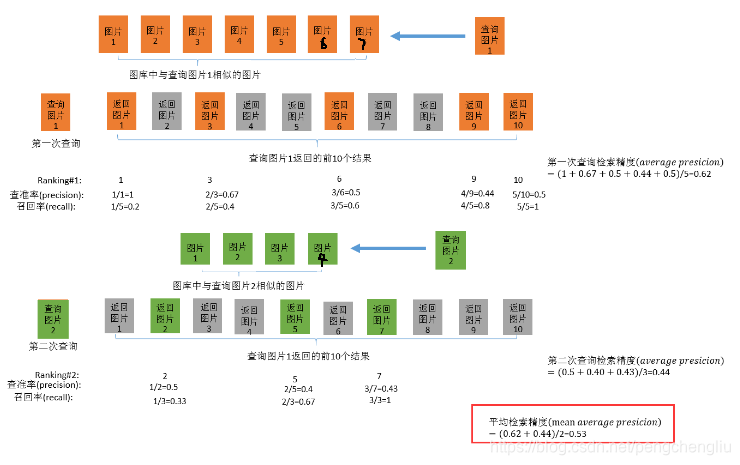
原图主要存在的问题就是,在前10张图片中,把所有的相似的结果都返回了。这样会给读者造成这样的困扰:没检索出来的但是又相似的图片怎么办??
改了之后,就清晰多了。我们就会发现我们这里求mAP的时候是不考虑召回率的,也就是并没有考虑那些相似的但是不在topk中的那些漏掉的图片。只考虑了topk中,相似的图片。
注:当然还有一种计算mAP的方法,就是考虑召回率的计算方法,我们这里不展开。
mAP@k,理解的话应该是m(AP@k),而不是(mAP)@k。也就是先求AP@k,再求平均。
AP@k,理解的话应该是A(P@k),而不是(AP)@k。也就是先求P@k,再求平均。
P@k = 前k个中有多少个正样本 / k,比如对于查询1的结果:P@1 = 1, P@2 = 1/2, P@3 = 2/3...
求AP@k的时候,是求哪些P@k,然后再求平均呢?是求检索到的k张图片中,正样本位置上的P@k。比如,查询1中,返回了10张图片,但是只有5个正样本,分别在第1、3、6、9、10位。所以要求P@1,P@3,P@6, P@9,P@10这5个值,再求平均得到AP@10.
在求mAP@k的时候,k是指每次查询的时候返回k张图片。这个写@k是与后面要讲的mAP做区分用的。写论文的时候有的时候都不写@k,到底是用的mAP@k,还是mAP,自己把握去吧
【举例】
假设有3张图片,这三张图片的哈希码为:query1=[1,-1,1,1], query2=[-1,1,-1,-1],query3=[1,-1,-1,-1]。
数据库中有7张图片,对应的哈希码为:gallery=[[ 1,-1,-1,-1], [-1, 1, 1,-1], [ 1, 1, 1,-1], [-1,-1, 1, 1], [ 1, 1,-1,-1], [ 1, 1, 1,-1], [-1, 1,-1,-1]]
三张query图片的标签为:[1,0,0], [1,1,0], [0,0,1]。
7张gallery图片的标签为:[0,1,0], [1,1,0], [1,0,1], [0,0,1], [0,1,0], [0,0,1], [1,1,0]
求mAP@5.
(1)对于query1([1,-1,1,1]):
首先query1与gallery图片求距离,然后按照距离进行排序,得到最近的topk(这里设为5)张图片。
| gallery | 汉明距离(有几位不同) | 排序 |
| [ 1,-1,-1,-1] | 2 | 2 |
| [-1, 1, 1,-1] | 3 | 5 |
| [ 1, 1, 1,-1] | 2 | 3 |
| [-1,-1, 1, 1] | 1 | 1 |
| [ 1, 1,-1,-1] | 3 | |
| [ 1, 1, 1,-1] | 2 | 4 |
| [-1, 1,-1,-1] | 4 |
然后,看看返回的topk张图片中,哪些是正样本,哪些是负样本。query1的标签为[1,0,0],所以包含第1类的都是正样本。
| 返回的topk | 图片4 | 图片1 | 图片3 | 图片6 | 图片2 |
| 标签 | [0,0,1] | [0,1,0] | [1,0,1] | [0,0,1] | [1,1,0] |
| 是否正样本 | 否 | 否 | 是 | 否 | 是 |
最后,计算AP@5值:
(1/3 + 2/5)/2 = 0.3667
(2)对于query2([-1,1,-1,-1]):
首先query2与gallery图片求距离,然后按照距离进行排序,得到最近的topk(这里设为5)张图片。
| gallery | 汉明距离(有几位不同) | 排序 |
| [ 1,-1,-1,-1] | 2 | 4 |
| [-1, 1, 1,-1] | 1 | 2 |
| [ 1, 1, 1,-1] | 2 | 5 |
| [-1,-1, 1, 1] | 3 | |
| [ 1, 1,-1,-1] | 1 | 3 |
| [ 1, 1, 1,-1] | 2 | |
| [-1, 1,-1,-1] | 0 | 1 |
然后,看看返回的topk张图片中,哪些是正样本,哪些是负样本。query2的标签为 [1,1,0],所以包含第1类或第2类的都是正样本。
| 返回的topk | 图片7 | 图片2 | 图片5 | 图片1 | 图片3 |
| 标签 | [1,1,0] | [1,1,0] | [0,1,0] | [0,1,0] | [1,0,1] |
| 是否正样本 | 是 | 是 | 是 | 是 | 是 |
最后,计算AP@5值:
(1/1 + 2/2 + 3/3 + 4/4 + 5/5)/5 = 1.0
(3)对于query3([1,-1,-1,-1]):
首先query3与gallery图片求距离,然后按照距离进行排序,得到最近的topk(这里设为5)张图片。
| gallery | 汉明距离(有几位不同) | 排序 |
| [ 1,-1,-1,-1] | 0 | 1 |
| [-1, 1, 1,-1] | 3 | |
| [ 1, 1, 1,-1] | 2 | 3 |
| [-1,-1, 1, 1] | 3 | |
| [ 1, 1,-1,-1] | 1 | 2 |
| [ 1, 1, 1,-1] | 2 | 4 |
| [-1, 1,-1,-1] | 2 | 5 |
然后,看看返回的topk张图片中,哪些是正样本,哪些是负样本。query3的标签为 [0,0,1],所以包含第3类的都是正样本。
| 返回的topk | 图片1 | 图片5 | 图片3 | 图片6 | 图片7 |
| 标签 | [0,1,0] | [0,1,0] | [1,0,1] | [0,0,1] | [1,1,0] |
| 是否正样本 | 否 | 否 | 是 | 是 | 否 |
最后,计算AP@5值:
(1/3 + 2/4)/2 = 0.4165
(4)对所有的query的AP值,求平均
mAP@5 = (0.3667 + 1 + 0.4165) /3 = 0.5944
1.2 mAP与mAP@k的区别
mAP呢,就是每次查询的时候不是返回k张图片了,而是把所有的图片都按相似度进行返回。也就是k的值等于gallery数据库的大小。
【举例】
还是用上面的例子。求mAP。
(1)对于query1([1,-1,1,1]):
首先query1与gallery图片求距离,然后按照距离进行排序
| gallery | 汉明距离(有几位不同) | 排序 |
| [ 1,-1,-1,-1] | 2 | 2 |
| [-1, 1, 1,-1] | 3 | 5 |
| [ 1, 1, 1,-1] | 2 | 3 |
| [-1,-1, 1, 1] | 1 | 1 |
| [ 1, 1,-1,-1] | 3 | 6 |
| [ 1, 1, 1,-1] | 2 | 4 |
| [-1, 1,-1,-1] | 4 | 7 |
然后,看看返回的topk张图片中,哪些是正样本,哪些是负样本。query1的标签为[1,0,0],所以包含第1类的都是正样本。
| 返回的topk | 图片4 | 图片1 | 图片3 | 图片6 | 图片2 | 图片5 | 图片7 |
| 标签 | [0,0,1] | [0,1,0] | [1,0,1] | [0,0,1] | [1,1,0] | [0,1,0] | [1,1,0] |
| 是否正样本 | 否 | 否 | 是 | 否 | 是 | 否 | 是 |
最后,计算AP值:
(1/3 + 2/5 + 3/7)/3 = 0.3873
(2)对于query2([-1,1,-1,-1]):
首先query2与gallery图片求距离,然后按照距离进行排序,得到最近的topk(这里设为5)张图片。
| gallery | 汉明距离(有几位不同) | 排序 |
| [ 1,-1,-1,-1] | 2 | 4 |
| [-1, 1, 1,-1] | 1 | 2 |
| [ 1, 1, 1,-1] | 2 | 5 |
| [-1,-1, 1, 1] | 3 | 7 |
| [ 1, 1,-1,-1] | 1 | 3 |
| [ 1, 1, 1,-1] | 2 | 6 |
| [-1, 1,-1,-1] | 0 | 1 |
然后,看看返回的topk张图片中,哪些是正样本,哪些是负样本。query2的标签为 [1,1,0],所以包含第1类或第2类的都是正样本。
| 返回的topk | 图片7 | 图片2 | 图片5 | 图片1 | 图片3 | 图片6 | 图片4 |
| 标签 | [1,1,0] | [1,1,0] | [0,1,0] | [0,1,0] | [1,0,1] | [0,0,1] | [0,0,1] |
| 是否正样本 | 是 | 是 | 是 | 是 | 是 | 否 | 否 |
最后,计算AP值:
(1/1 + 2/2 + 3/3 + 4/4 + 5/5)/5 = 1.0
(3)对于query3([1,-1,-1,-1]):
首先query3与gallery图片求距离,然后按照距离进行排序,得到最近的topk(这里设为5)张图片。
| gallery | 汉明距离(有几位不同) | 排序 |
| [ 1,-1,-1,-1] | 0 | 1 |
| [-1, 1, 1,-1] | 3 | 6 |
| [ 1, 1, 1,-1] | 2 | 3 |
| [-1,-1, 1, 1] | 3 | 7 |
| [ 1, 1,-1,-1] | 1 | 2 |
| [ 1, 1, 1,-1] | 2 | 4 |
| [-1, 1,-1,-1] | 2 | 5 |
然后,看看返回的topk张图片中,哪些是正样本,哪些是负样本。query3的标签为 [0,0,1],所以包含第3类的都是正样本。
| 返回的topk | 图片1 | 图片5 | 图片3 | 图片6 | 图片7 | 图片2 | 图片4 |
| 标签 | [0,1,0] | [0,1,0] | [1,0,1] | [0,0,1] | [1,1,0] | [1,1,0] | [0,0,1] |
| 是否正样本 | 否 | 否 | 是 | 是 | 否 | 否 | 是 |
最后,计算AP值:
(1/3 + 2/4 + 3/7)/3 = 0.4206
(4)对所有的query的AP值,求平均
mAP = (0.3873 + 1 + 0.4206) /3 = 0.6026
二、代码实现
# @file name : test2.py
# @brief :
# @author : liupc
# @date : 2021/8/2
import numpy as np
#计算汉明距离。有几位不同,距离就为几。
def CalcHammingDist(B1, B2):
q = B2.shape[1]
distH = 0.5 * (q - np.dot(B1, B2.transpose()))
return distH
#计算mAP@k的值
def CalcTopMap(qB, rB, queryL, retrievalL, topk):
#qB queryBinary, query数据集,都转成了哈希码
#rB retrievalBinary,gallery数据集,都转成了哈希码
#queryL queryLabel,query数据集的标签
#retrievalL retrievalLabel,gallery数据集的标签
num_query = queryL.shape[0] #共有多少个查询
topkmap = 0
for iter in range(num_query): #对每一个查询,求其AP@k的值
#gnd:一个长度等于gallery数据集的0/1向量,1表示为正样本(即至少包含query的一个标签),0表示负样本(即,不包含query的标签)。
gnd = (np.dot(queryL[iter, :], retrievalL.transpose()) > 0).astype(np.float32)
hamm = CalcHammingDist(qB[iter, :], rB) #计算第iter张query图片与gallery数据集的汉明距离
ind = np.argsort(hamm) #对汉明距离进行排序,返回下标,表示最相似的图片列表
gnd = gnd[ind] #最相似的图片是否为正样本的列表
tgnd = gnd[0:topk] #只看前topk个结果
tsum = np.sum(tgnd).astype(int) #前topk个中有多少个预测对了
if tsum == 0:
continue
count = np.linspace(1, tsum, tsum)
tindex = np.asarray(np.where(tgnd == 1)) + 1.0
topkmap_ = np.mean(count / (tindex))
topkmap += topkmap_
topkmap = topkmap / num_query
return topkmap
#计算mAP的值
def CalcMap(qB, rB, queryL, retrievalL):
#qB queryBinary, query数据集,都转成了哈希码
#rB retrievalBinary,gallery数据集,都转成了哈希码
#queryL queryLabel,query数据集的标签
#retrievalL retrievalLabel,gallery数据集的标签
num_query = queryL.shape[0]
map = 0
# print('++++++++++++++++++++++++++++++++++++++++++++++++++++++++++')
for iter in range(num_query):
gnd = (np.dot(queryL[iter, :], retrievalL.transpose()) > 0).astype(np.float32)
tsum = np.sum(gnd).astype(int)
if tsum == 0:
continue
hamm = CalcHammingDist(qB[iter, :], rB)
ind = np.argsort(hamm)
gnd = gnd[ind]
count = np.linspace(1, tsum, tsum)
tindex = np.asarray(np.where(gnd == 1)) + 1.0
map_ = np.mean(count / (tindex))
# print(map_)
map = map + map_
map = map / num_query
return map
#计算topk准确率
def CalcTopAcc(qB, rB, queryL, retrievalL, topk):
# qB: {-1,+1}^{mxq}
# rB: {-1,+1}^{nxq}
# queryL: {0,1}^{mxl}
# retrievalL: {0,1}^{nxl}
num_query = queryL.shape[0]
topkacc = 0
# print('++++++++++++++++++++++++++++++++++++++++++++++++++++++++++')
for iter in range(num_query):
# gnd:一个长度等于gallery数据集的0/1向量,1表示为正样本(即至少包含query的一个标签),0表示负样本(即,不包含query的标签)。
gnd = (np.dot(queryL[iter, :], retrievalL.transpose()) > 0).astype(np.float32)
hamm = CalcHammingDist(qB[iter, :], rB) #计算第iter张query图片与gallery数据集的汉明距离
ind = np.argsort(hamm) #对汉明距离进行排序,返回下标,表示最相似的图片列表
gnd = gnd[ind] #最相似的图片是否为正样本的列表
tgnd = gnd[0:topk] #只看前topk个结果
tsum = np.sum(tgnd) #前topk个中有多少个预测对了
if tsum == 0:
continue
topkacc += tsum / topk
topkacc = topkacc / num_query
return topkacc
if __name__=='__main__':
queryBinary = np.array([[1,-1,1,1],[-1,1,-1,-1],[1,-1,-1,-1]])
galleryBinary = np.array([[ 1,-1,-1,-1],
[-1, 1, 1,-1],
[ 1, 1, 1,-1],
[-1,-1, 1, 1],
[ 1, 1,-1,-1],
[ 1, 1, 1,-1],
[-1, 1,-1,-1]])
queryLabel = np.array([[1,0,0],
[1,1,0],
[0,0,1]], dtype=np.int64)
galleryLabel = np.array([[0,1,0],
[1,1,0],
[1,0,1],
[0,0,1],
[0,1,0],
[0,0,1],
[1,1,0]], dtype=np.int64)
topk = 5
topkmap = CalcTopMap(queryBinary, galleryBinary, queryLabel, galleryLabel, topk)
print("map@{}为:{}".format(topk, topkmap))
map = CalcMap(queryBinary, galleryBinary, queryLabel, galleryLabel)
print("map为:{}".format(map))
topkacc = CalcTopAcc(queryBinary, galleryBinary, queryLabel, galleryLabel, topk)
print("acc@{}为:{}".format(topk, topkacc))运行结果:

三、代码详解
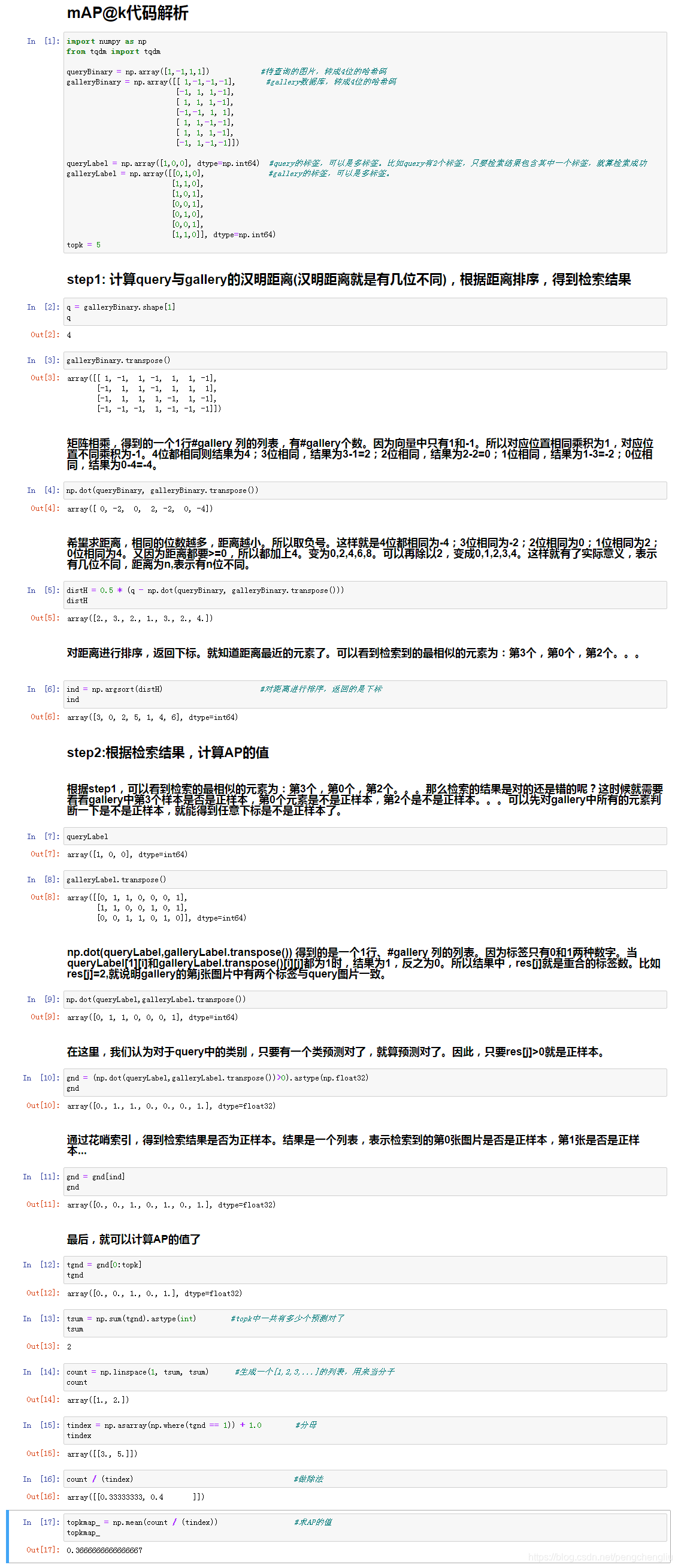
参考:https://yongyuan.name/blog/evaluation-of-information-retrieval.html



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









