














Shuffle的细节图描述




分区案例




![]()

高可用配置





将不同的数据最终输出到不同的目录

![]()


![]()
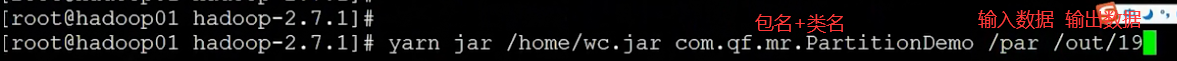
![]()



自定义分区到此就可以了。主要是如何进行分类。
package qf.com.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/*
*类说明:分区
输入数据
Hello HI HI qianfeng
hi hi qianfeng qianfeng
163.com
qq.com
189.com
@163.com
@qq.com
*123
输出:
将首写字母为A-Z的放到一个文件中
将首写字母为a-z的放到一个文件中
将首写字母为0-9的放到一个文件中
其他的放到一个文件中
结果文件:part-r-00000
Hello 1
Hi 2
结果文件:part-r-00001
hi 2
qianfeng 2
结果文件:part-r-00002
....
结果文件:part-r-00003
....
*/
public class PartitionDemo implements Tool {
/**
* map阶段
*
* @author HP
*
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String words[] = line.split(" ");
for (String s : words) {
context.write(new Text(s), new Text(1 + ""));
}
}
}
/**
* reduce阶段
*/
public static class MyReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
int counter = 0;
for (Text t : values) {
counter += Integer.parseInt(t.toString());
}
context.write(key, new Text(counter + ""));
}
}
public void setConf(Configuration conf) {
// 对conf的属性设置
conf.set("fs.defaultFS", "hdfs://qf");
conf.set("dfs.nameservices", "qf");
conf.set("dfs.ha.namenodes.qf", "nn1, nn2");
conf.set("dfs.namenode.rpc-address.qf.nn1", "hadoop01:9000");
conf.set("dfs.namenode.rpc-address.qf.nn2", "hadoop02:9000");
conf.set("dfs.client.failover.proxy.provider.qf", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider");
}
public Configuration getConf() {
return new Configuration();
}
/**
* 驱动方法
*/
public int run(String[] args) throws Exception {
// 1.获取配置对象信息
Configuration conf = getConf();
// 2.对conf进行设置(没有就不用)
// 3.获取job对象 (注意导入的包)
Job job = Job.getInstance(conf, "job");
// 4.设置job的运行主类
job.setJarByClass(PartitionDemo.class);
//set inputpath and outputpath
setInputAndOutput(job, conf, args);
// System.out.println("jiazai finished");
// 5.对map阶段进行设置
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//添加分区信息
job.setPartitionerClass(MyPatitioner.class);
job.setNumReduceTasks(4);//上面有4种情况 分为4个文件存放
// System.out.println("map finished");
// 6.对reduce阶段进行设置
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//提交
return job.waitForCompletion(true) ? 0 : 1;
}
//主方法
public static void main(String[] args) throws Exception {
int isok = ToolRunner.run(new Configuration(), new PartitionDemo(), args);
System.out.println(isok);
}
/**
* 处理参数的方法
* @param job
* @param conf
* @param args
*/
private void setInputAndOutput(Job job, Configuration conf, String[] args) {
if(args.length != 2) {
System.out.println("usage:yarn jar /*.jar package.classname /* /*");
return ;
}
//正常处理输入输出参数
try {
FileInputFormat.addInputPath(job, new Path(args[0]));
FileSystem fs = FileSystem.get(conf);
Path outputpath = new Path(args[1]);
if(fs.exists(outputpath)) {
fs.delete(outputpath, true);
}
FileOutputFormat.setOutputPath(job, outputpath);
} catch (Exception e) {
e.printStackTrace();
}
}
}
package qf.com.mr;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/*
*类说明:自定义的Partitioner
*自定义分区需要注意的
*1.分区需要继承Partitioner<key, value>, 其中的key-value需要和map阶段的输出相同
*2.实现getPartition(key, value, numPartitions)方法, 该方法只能返回int类型
*3.分区数和reduce个数相同
*4.默认使用HashPartitioner
*/
public class MyPatitioner extends Partitioner<Text, Text>{
@Override
public int getPartition(Text key, Text value, int numPartitions) {
String firstChar = key.toString().substring(0, 1);//把第一个字母给截下来
if(firstChar.matches("^[A-Z]")) {
return 0%numPartitions;
}else if(firstChar.matches("^[a-z]")) {
return 1%numPartitions;
}else if(firstChar.matches("^[0-9]")) {
return 2%numPartitions;
}else {
return 3%numPartitions;
}
}
}
倒排索引案
那个网页排名前面,那个网页排名后面,根据关键词进行倒排索引









到此就可以了,导出jar包,拉到home目录下面
![]()
![]()
![]()
![]()
![]()
![]()
![]()

![]()


到此,Combiner也讲完了。















 5223
5223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









