









为什么有hive
facebook最初研发来处理海量的社交数据和机器学习。
hive:简化分析:使用sql,开发效率高500行
mr:10000
hive是什么
hive是一个大数据仓库
hive是一个基于hadoop的数据仓库
hive是一个基于hadoop的数据仓库,可以通过类sql语句来对数据进行读、写、管理(元数据管理)
hive的架构(三层)
用户连接客户端:cli、jdbc/odbc、web gui
thrift server:第三方服务
metastore:hive的元数据存储(库名、表名、字段名、数据类型、分区、分桶、创建者、创建时间等)
Driver:解释器,将hql语句生成抽象表达式树。
compiler:编译器,对hql语句进行词法、语法、语言的编译(此时需要联系元数据),编译完成后生成一个有向无环的执行计划。
a->b->c->d->e
optimizer:优化器,将执行计划进行优化,减少不必要的列、使用分区等优化策略
executor:执行器,将优化后的执行计划转换成hadoop的mapreduce框架再提交给yarn集群去运行
hive的特性
通过SQL轻松访问数据的工具,从而支持数据仓库任务,如提取/转换/加载(ETL)、报告和数据分析。
将结构强加于多种数据格式的机制
访问直接存储在Apache HDFS中的文件™ 或在其他数据存储系统(如Apache HBase)中™
通过Apache Tez执行查询™,阿帕奇星火™,或MapReduce
带HPL-SQL的过程语言
通过Hive LLAP、Apache YARN和Apache Slider进行亚秒查询检索。
hive和hadoop的关系
hive本身没有存储和计算的功能。hive相当于套在hadoop上的一个壳子。hive是基于hadoop,hive的存储基于hdfs(hbase),hive的计算基于mapreduce。
hive的安装
常用的有3种安装方式(hive会自动检测hadoop的环境变量,如果有就必须启动hadoop)模式主要是元数据的管理
1、本地模式
使用hive自带的默认元数据库derby来进行元数据存储,通常用于测试环境
优点:使用简单,不需要进行配置
缺点:只支持单session
2、远程模式(mysql服务和hive在同一台服务器上)hive是mysql的客户端
通常使用关系型数据库来进行元数据存储,mysql、sql server oracle等待jdbc驱动的数据库
优点:支持多session
缺点:需要配置,还需要安装mysql等数据库
1、解压并配置环境变量
2、配置hive的配置文件
2、1 vi hive-env.sh
JAVA_HOME =
2、2配置 vi hive-site.xml
<configuration>
<!--配置mysql的连接字符串-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.137.91:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<!--指定连接mysql的驱动-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!--指定连接mysql的用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<!--指定用户的登录密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
</configuration>3、将mysql的驱动包cp到hive的安装目录下的lib下
4、在mysql上的hive元数据库的编码集一定要使用latin1(用默认的,不能有utf-8)
5、启动
3、远程模式(mysql服务和hive不在同一台服务器上)
本地模式安装、远程模式安装
1、先将其解压到指定目录下

2、编辑文件,配置环境变量,才可以使hive在任意地方执行命令
![]()

hive启动之前,先启动hadoop(因为hive是套在hadoop外面的一个壳子)hive会自动检测hadoop的环境变量,如果有就必须启动hadoop
然后在启动hive
![]()
远程的,元数据是存储到mysql里面,所以要配置元数据的管理
远程版的 hive-env.sh(这个配不配都没有什么问题)

第二个是自定义配置(上面哪里有文件)
![]()
将mysql的驱动包放到hive的lib下面

基本操作
查看状态,下面的状态是active
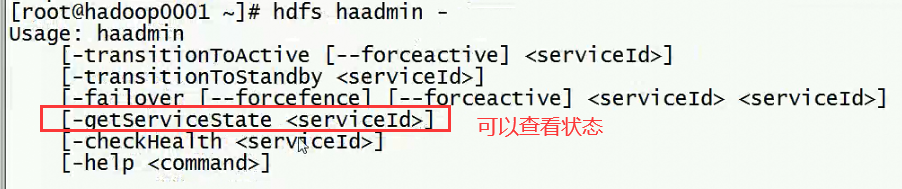

在那个目录下执行hive命令,就在那个目录下生成元数据的文件,其他用户进来是不可以的,因为已经被占用了

同一个用户,在那个目录下执行hive ,就在那个目录下生成这个文件,如果没有就生成,有就加载,如果另外一个用户进来,则不能再加载,因为已经被占用了。是启动目录生成。
下面进行测试写法
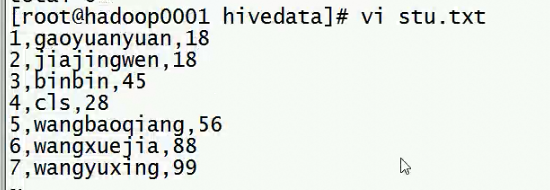
上传文件

查询

创建一个表
![]()
加载数据到t2表里面

正确写法
hive使用
hive的默认列分隔符:
\001 \u0001 ctrl + v + ctrl + a
create table if not exists t3(
id int,
name string,
age int
)
row format delimited
fields terminated by ','
lines terminated by '\n'
;

再加载文件到表2
![]()

自定义分隔符

将文件加载过来
















 7423
7423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









