







在进行实验过程中,需要完成对雪天图像的处理,其中一个主要操作为去雪。相较于去雾,去雨模型,去雪模型相对较少,因此在研究时所能够借鉴的资料有限,这对我们的研究造成了一定困扰。
模型算法
DesnowNet网络模型(2017)
在深度学习领域中,去雪算法的开山鼻祖为DesnowNet,后续去雪算法也大多是在这个基础上改进的。进行我们就将围绕DesnowNet模型来学习相关概念。
DesnowNet的结构下图所示,它由半透明度复原模块和残差生成模块两部分组成,这两个模块均由一个描述子和一个复原器组成。描述子都是以 Inception-v4作为骨干设计的子网络,它使用多次空洞卷积来更好地提取尺度不变特征, 最后将各尺度的结果堆叠起来保持每个尺度的属性。对于上述的特征,接下来复原器使用不同感受野大小的卷积层来进行卷积,最后在所有卷积的结果里取最大值来选取最鲁棒的特征。半透明度复原模块最终输出图像雪花掩膜、色差图和初步复原图,这三个变 量通过堆叠形成新的特征作为残差生成模块的输入。
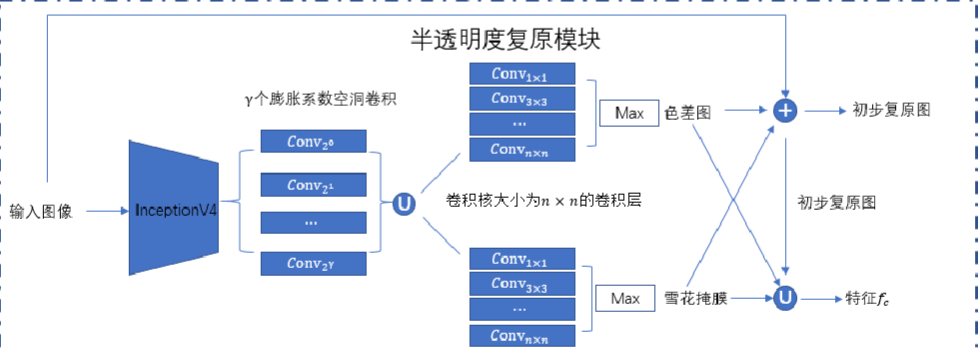
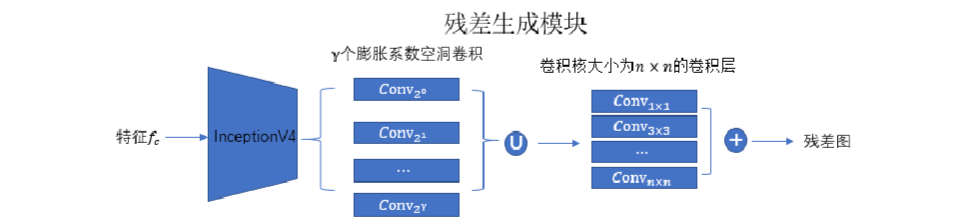
该特征经过类似的描述符后,将得 到的结果输入到不同感受野大小的卷积层。把不同层的结果相加起来得到初步复原图与 干净图像之间的残差图,将初步复原图与残差图相加便能得到网络最终输出的去雪花结果。
HDCW-Net(2021)
code
paper
datasets
这是针对降雪场景设计的网络模型
使用的框架为tensorflow。详细所需依赖如下所示:

应对多种复杂天气(2022)
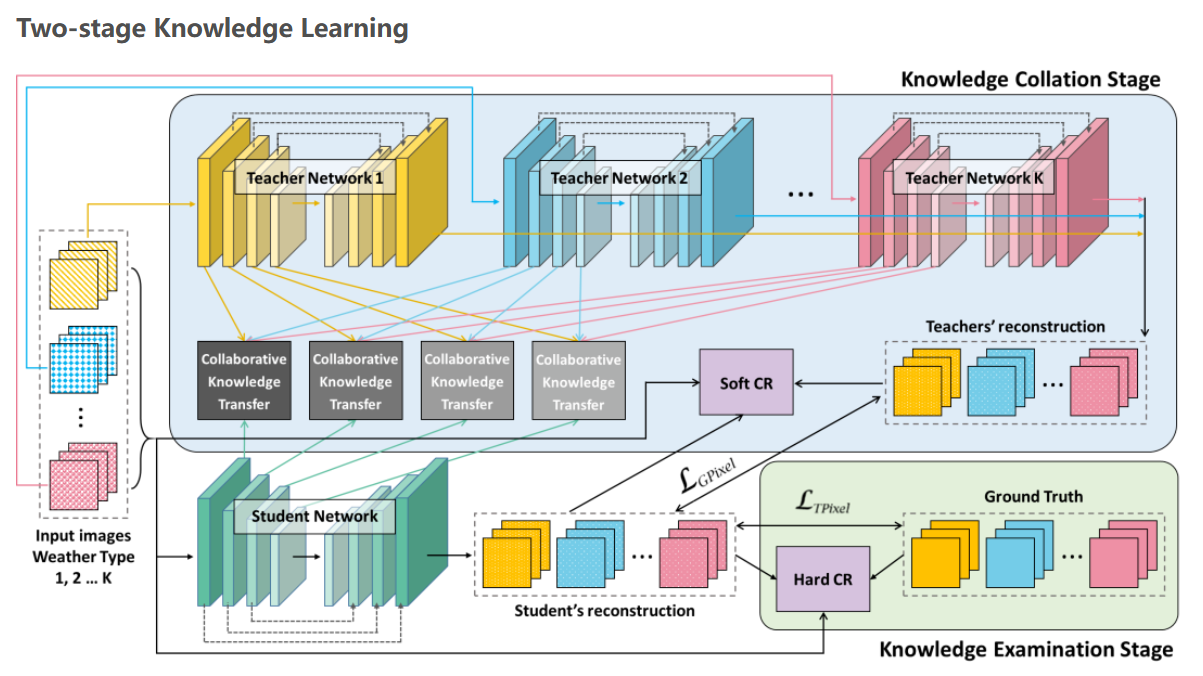
Learning Multiple Adverse Weather Removal via Two-stage Knowledge Learning and Multi-contrastive Regularization: Toward a Unified Model
这篇论文没有针对某一种恶劣天气进行处理,而是将多种恶劣天气同时进行处理。
当前针对恶劣天气的影像复原算法虽然已经发展多年并且已经成熟,但是有着许多的限制:
- 单张影像还原(Single Weather Removal) :
虽然能够在单种气候下获得良好的效果,但是对于其他天气而言效果相当有限,因为所设计的架构大多数是针对某种气候的特征去设计,不利于真实世界的应用。 - 多重天气还原(Multi-degradation removal) :可以使用同一种架构去针对不同还原任务去做训练,但是一种还原就要训练一组参数,并且必须事先分辨是哪一种还原任务。
- 多合一天气还原 (All-in-one Bad Weather Removal) [4]: 虽然使用Neural architecture search运用一个编码器搜索特征,能够实现一组预训练模型解决所有的天气,但是一种天气就需要一种译码器,对于模型有着大小的不便性。
对于真实世界而言影像还原模型需要能够在不增加运算需求以及模型大小的情况下扩充还原的型态,并且同时有着良好的性能,本篇文章针对这个问题,基于知识蒸馏(Knowledge Distillation)提出了一个新颖的算法,能够在不增加运算资源的情况下在多种天气下达到相当好的性能。
此外,这个团队在过去对于影像还原有许多发表:
- 单张影像去雪:[JSTASR] (ECCV’20) 、 [HDCW-Net] (ICCV’21)
- 单张影像去雾:[PMS-Net] (CVPR’19) and [PMHLD] (TIP’20)
- 单张影像去雨:[ContouletNet] (BMVC’21)
调试过程
其inference.py可以之间使用,只要将student的权重文件放入即可,博主实验过其去噪后的结果,貌似是变清晰了一点。但train时的meta里的json文件没有找到。
作者指出meta文件是需要自己构建
结构如下:
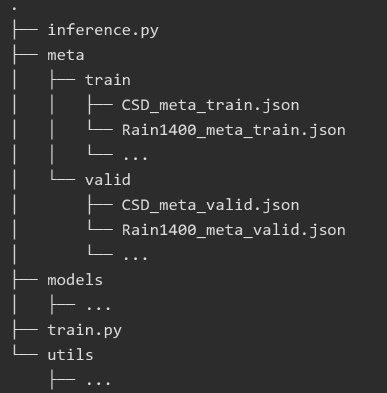
json文件结构如下:
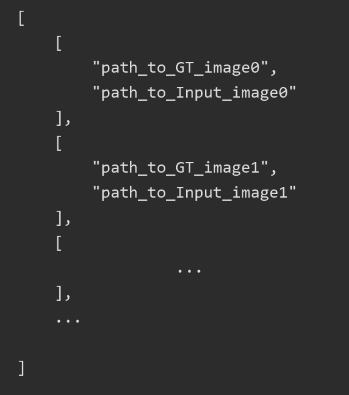
最终我们按照指定格式生成了对应的json地址文件
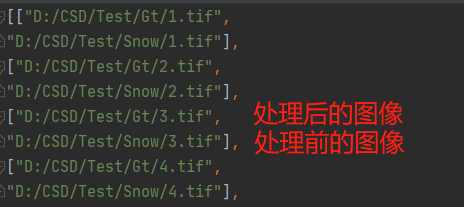
生成代码很简单,因为文件命名是有顺序的,所以不需要读取目录生成。
gt_path="D:/CSD/Test/Gt/"
input_path="D:/CSD/Test/Snow/"
for i in range(1,20):
path1=gt_path+str(i)+".tif"
path2=input_path+str(i)+".tif"
path='"'+path1+'",\n'+'"'+path2+'"'
with open('test.json', 'a') as f:
f.write("["+path+"],\n")
运行结果:
All-In-One Image Restoration for Unknown Corruption (AirNet)
也是一个集成图像处理模型,可以处理噪声,去雨,去雾。
采用MMCV框架
数据集
常见去雪数据集有:CSD,snow100k,Rain1400
ITS去雾数据集
训练集 ITS(indoor training set)室内,合成
利用1399张middlebury 和NYU2 Depth室内深度数据集 生成13990个图。一个 真实值对应10个雾天图
分成13000训练集和990验证集

OTS去雾数据集

评价指标
MSE与PSNR
用于衡量一张干净图片与一张有噪声图片间的差异。当两张图片差异越小,意味着噪声越小,即MSE越小,那么信噪比PSNR就越大,也就意味着图像质量越好。
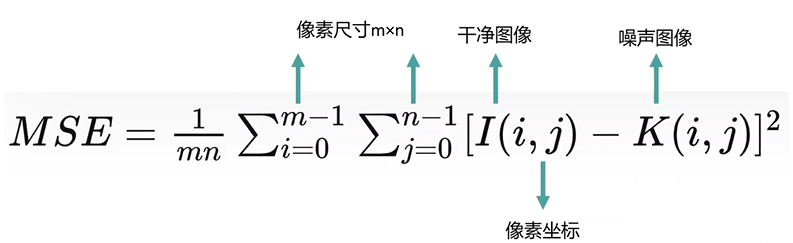
给定一个大小为mxn的干净图像I和噪声图像K,均方误差(MSE)定义为:
PSNR (Peak Signal-to-Noise Ratio) 峰值信噪比
然后PSNR(dB)就定义为:
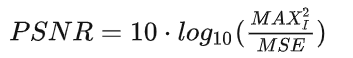
其中MAX为图片可能的最大像素值。如果每个像素都由 8 位二进制来表示,那么就为 255。通常,如果像素值由B位二进制来表示,那么:
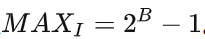
一般地,针对 uint8 数据,最大像素值为 255,;针对浮点型数据,最大像素值为 1。
上面是针对灰度图像的计算方法,如果是彩色图像,通常有三种方法来计算。
- 分别计算
RGB三个通道的PSNR,然后取平均值。 - 计算
RGB三通道的 MSE ,然后再除以 3 。 - 将图片转化为
YCbCr格式,然后只计算Y分量也就是亮度分量的PSNR。
其中,第二和第三种方法比较常见。
# im1 和 im2 都为灰度图像,uint8 类型
# method 1
diff = im1 - im2
mse = np.mean(np.square(diff))
psnr = 10 * np.log10(255 * 255 / mse)
# method 2
psnr = skimage.measure.compare_psnr(im1, im2, 255)
SSIM(Structure Similarity Index Measure)
衡量两张图片的相似性,也可用于衡量图片的失真程度。如下,在MSE相同的情况下,SSIM不同差别则很大。

结构相似指标可以衡量图片的失真程度,也可以衡量两张图片的相似程度。与MSE和PSNR衡量绝对误差不同,SSIM是感知模型,即更符合人眼的直观感受。
SSIM 主要考量图片的三个关键特征:
亮度(Luminance):指所有像素值灰度的平均值。
对比度(Contrast),
结构 (Structure)
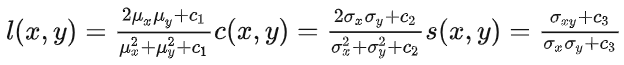

则有:


每次计算的时候都从图片上取一个NxN的窗口,然后不断滑动窗口进行计算,最后取平均值作为全局的 SSIM。
其取值范围为【-1,1】,具有边界性,唯一最大性。
# im1 和 im2 都为灰度图像,uint8 类型
ssim = skimage.measure.compare_ssim(im1, im2, data_range=255)
针对超光谱图像,我们需要针对不同波段分别计算 SSIM,然后取平均值,这个指标称为 MSSIM。

















 2401
2401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











