 关注
关注
 分享
分享
彭祥.
目前研究生在读,主要研究目标检测相关算法,具体以Transformer模型为主,对图像去噪方面也有涉猎,大学期间专业为软件开发,拥有较为丰富的编程与毕业设计撰写经验。
展开
-
RT-DETR 目标检测视频推理
事实上,进行视频推理的过程与单张图片的过程及其类似,就是将原本的视频切分为多帧图像后再进行推理即可。这里面涉及到Image等相关操作,今天便借此机会梳理一遍。先前介绍了RT-DETR推理单张图像的案例,今天则介绍以下如何利用RT-DETR来进行视频推理。根据结果获取目标类别,标注框与得分,并将其绘制在每张图像上。可以看到,其在视频推理过程中,对CPU的利用率明显增高。视频合成,指定合成视频的名称,帧率等信息,将。利用cv2生成视频读取器,读取视频。是否可用,同时进行前向推理,并计算。原创 2024-07-17 10:55:25 · 287 阅读 · 2 评论 -
RT-DETR+Flask实现目标检测推理案例
今天,带大家利用RT-DETR(我们可以换成任意一个模型)+Flask来实现一个目标检测平台小案例,其实现效果如下:目标检测案例这个案例很简单,就是让我们上传一张图像,随后选择一下置信度,即可检测出图像中的目标,那么具体该如何实现呢?原创 2024-07-15 17:25:43 · 583 阅读 · 0 评论 -
RT-DETR详解之 Decoder 层
在上一篇博客中,博主已经讲解了如何利用选择出好的特征,接下来便要将这些特征输入到Decoder中进行解码,需要注意的是,在RT-DETR的Encoder中,使用的是标准的自注意力计算方法,而在其Decoder中,则使用的是可变形自注意力(deformable attention),可变形自注意力能够大幅的降低计算量,同时该部分还使用到了CUDA算子,能够加快运行速度,当然,这个可变形自注意力计算并非是RT-DETR的创新点,但其作用却是极大,在DINO,DN-Deformable-DETR中都有使用。原创 2024-06-11 23:37:42 · 882 阅读 · 1 评论 -
RT-DETR 详解之 Uncertainty-minimal Query Selection
通过上述过程,在进行特征向量选择的过程中,由于anchor在构造时具有倾向性,即多位于一些中心点区域,因此其anchor具有高IOU,在最后选择时,再选择这里面分类分数高的特征,从而选择高分类分数与高。进入_get_decoder_input方法后,首先进行的是构造Anchor,对应的是_generate_anchors方法。最终将Encoder得到的特征图生成的查询向量与查询降噪生成的查询向量结合起来,输入Decoder进行下一步的操作。分数变高,其分类分数也较高,而绿色代表原方法,可以看到。原创 2024-06-11 11:37:48 · 1172 阅读 · 0 评论 -
RT-DETR 详解之查询去噪( DeNoise)
在讲解Uncertainty-minimal Query Selection之前,RT-DETR还做了一个DeNoise的操作,该方法并非是RT-DETR所提出的,但其在这里使用了,这个方法便是查询去噪方法。输出的查询向量也是十分强的,这就会导致作弊,因此,加噪组查询向量与原始查询向量需要加以区分,而这个做法便是遮蔽掩膜,其实这个掩膜与前面噪声构造时的很相似。生成的掩膜如下,黄色为正样本,红色为负样本,这意味着红色样本的标注框偏移,大小变化会更大,即噪声更大。那么,RT-DETR到底是怎么做的呢?原创 2024-06-10 18:24:30 · 1236 阅读 · 0 评论 -
RT-DETR 详解之 Efficient Hybrid Encoder
在先前的博文中,博主介绍了RT-DETR在官方代码与YOLOv8集成程序中的训练与推理过程,接下来,博主将通过代码调试的方式来梳理RT-DETR的整个过程。原创 2024-06-08 00:10:50 · 1161 阅读 · 0 评论 -
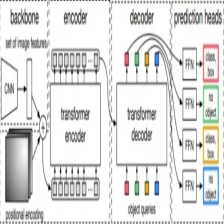
RT-DETR:端到端的实时Transformer检测模型(目标检测+跟踪)
博主一直一来做的都是基于的目标检测领域,相较于基于卷积的目标检测方法,如YOLO等,其检测速度一直为人诟病。终于,RT-DETR横空出世,在取得高精度的同时,检测速度也大幅提升。那么RT-DETR是如何做到的呢?在研究RT-DETR的改进前,我们先来了解下DETR类目标检测方法的发展历程吧DETRNMSDAB-DETRDETR100DETRDAB-DETRH-DETR然而,上述方法尽管已经大幅提升了检测精度,降低了计算复杂度,但其受本身高计算复杂度的制约,DETR。原创 2024-05-31 16:45:01 · 3429 阅读 · 13 评论 -
SegFormer程序调试记录
随后切换到segformer目录下执行安装requirement.txt中指定的依赖。安装pytorch版本,博主使用的是pytorch1.7.0。此时基本已经完成环境配置过程,下载一个权重文件进行简单测试。安装完成后继续配置,注意一定要在segformer目录下。随后进入demo文件夹,修改下配置文件。原创 2023-04-07 22:01:02 · 1373 阅读 · 10 评论 -
DN-DETR调试记录
先前的DN-DETR模型都是在服务器上运行的,后来在本地运行时出现了一些小问题,这篇博文则主要介绍DN-DETR模型在本地运行时所需要做的配置。原创 2023-12-25 11:21:20 · 690 阅读 · 1 评论 -
神经网络输出中间特征图
在进行神经网络的训练过程中,会生成不同的特征图信息,这些特征图中包含大量图像信息,如轮廓信息,细节信息等,然而,我们一般只获取最终的输出结果,至于中间的特征图则很少关注。前两天师弟突然问起了这个问题,但我也没有头绪,后来和师弟研究了一下,大概有了一个思路。即每个特征提取模块都会输出一个特征图,这些特征图的每个像素实际上就是一些数值,那么只需要将这些数值保存,再以图像的形式展现出来便OK了。基于这个思路,我们来进行设计。原创 2023-09-09 10:00:38 · 797 阅读 · 0 评论 -
DETR,YOLO模型计算量(FLOPs)参数量(Params)
关于计算量(FLOPs)参数量(Params)的一个直观理解,便是计算量对应时间复杂度,参数量对应空间复杂度,即计算量要看网络执行时间的长短,参数量要看占用显存的量。计算量: FLOPs,FLOP时指浮点运算次数,s是指秒,即每秒浮点运算次数的意思,考量一个网络模型的计算量的标准。参数量: Params,是指网络模型中需要训练的参数总数。了解以上概念后,接下来便是如何计算这两个值。一个很常见的方法便是通过ptflos包来实现。这段代码可以说是即插即用。原创 2023-08-11 09:47:32 · 4400 阅读 · 2 评论 -
关于COCO数据集评价参数设置
就没有什么问题,而在WidePerson数据集中,尽管绝大部分图片中目标的数量在100以内,但却存在某些图片中包含近200个目标,那么我们再使用maxDets=100就不符合要求了。maxDets:该指标的意思是分别保留测试集的每张图上置信度排名第1、前10、前100个预测框,根据这些预测框和真实框进行比对,来计算AP、AR等值。比如博主在使用COCO数据集时,博主将其中的car,bus,truck进行提取,这就导致在一张图片中的目标数目可能只有几张,那么我们使用。原创 2023-06-29 10:05:21 · 874 阅读 · 0 评论 -
DINO推理模块实现
引入COCO数据集中的标注类别名称,博主使用的是COCO缩减数据集,大家可以按照这个格式进行制作。的代码中已经给出了推理模块的实现,这里博主是将其流程进行梳理,并对其中的问题给出解决方案。即我们常说的推理模块,前面博主已经介绍了如何使用。项目中,博主想将模型与网络分离开进而将其部署在云端,进而开发一个目标检测的接口。,意为不计算梯度,因为这里的推理是不需要梯度更新的,否则会爆显存。随后是构建模型与权重文件加载,指的注意的是要想。进行推理,就需要将推理代码放到。进行推理,今天博主则介绍。原创 2023-06-28 22:22:00 · 465 阅读 · 5 评论 -
DINO-DETR匈牙利匹配与加噪过程学习记录
今天再来回顾一下DINO中匈牙利匹配与损失函数部分,该部分大致与DETR相似,却又略有不同。为了查看数据方便,博主将num_query改为20,max_select值也为20。原创 2023-06-17 18:26:39 · 1122 阅读 · 1 评论 -
MMDetection学习记录(二)之配置文件
介绍MMDetection的配置文件主要结构原创 2023-06-05 21:17:07 · 1165 阅读 · 0 评论 -
注意力机制学习记录
ECA通道注意力机制,SELayer的改进版本原创 2023-06-02 10:25:36 · 132 阅读 · 0 评论 -
Sinkhorn-Knopp算法
Sinkhorn-Knopp是为了解决最优传输问题所提出的。原创 2023-05-31 17:19:56 · 3839 阅读 · 0 评论 -
DINO损失函数构造解析
idx值为:(tensor([0, 0, 0, 0, 1, 1, 1, 1]), tensor([696, 720, 721, 866, 0, 1, 2, 3]))idx值为(tensor([0, 0, 0, 0, 1, 1, 1, 1]), tensor([696, 720, 721, 866, 0, 1, 2, 3]))随后我们看看如何损失函数的计算,首先是进行匹配,即将预测框与真值框使用二分匹配的方式进行匹配。方法的定义可知,其返回结果为所属batch与预测框的编号。原创 2023-05-18 15:32:47 · 1296 阅读 · 0 评论 -
PVT(Pyramid Vision Transformer)学习记录
x为torch.Size([2, 3136, 64]),首先经过permute进行维度变换为torch.Size([2, 64,3136]),随后经过reshape为:torch.Size([2, 64, 56, 56])值得注意的是,只有stage1上patch=4,在后面的三个stage上patch都为2,这样也就参考卷积,其是一个二倍大小的关系。首先我们的输入图片为torch.Size([2, 3, 224, 224]),即batch-size=2,channel=3,W=H=224。原创 2023-05-16 15:28:09 · 2361 阅读 · 2 评论 -
DETR类环境快速搭建
随后切换到DINO目录,安装所需包,记得将requirements.txt 中的git clone下载删掉。随后修改pycocotools中配置使其输出多个类别的AP值。随后安装pycocotools。原创 2023-05-13 15:59:43 · 580 阅读 · 0 评论 -
DAB-Deformable-DETR源码学习记录之模型构建(二)
书接上回,上篇博客中我们学习到了Encoder模块,接下来我们来学习Decoder模块其代码是如何实现的。其实Deformable-DETR最大的创新在于其提出了可变形注意力模型以及多尺度融合模块:其主要表现在Backbone模块以及self-attention核cross-attention的计算上。这些方法都在DINO-DETR中得到继承,此外DAB-DETR中的Anchor Query设计与bounding box强化机制也有涉及。原创 2023-04-27 14:52:48 · 908 阅读 · 0 评论 -
目标检测之损失函数
损失函数的作用为度量神经网络预测信息与期望信息(标签)的距离,预测信息越接近期望信息,损失函数值越小。在目标检测领域,常见的损失分为分类损失和回归损失。原创 2023-04-26 16:10:18 · 1638 阅读 · 0 评论 -
DAB-Deformable-DETR代码学习记录之模型构建
DAB-DETR的作者在Deformable-DETR基础上,将DAB-DETR的思想融入到了Deformable-DETR中,取得了不错的成绩。今天博主通过源码来学习下DAB-Deformable-DETR模型。原创 2023-04-25 10:59:07 · 1471 阅读 · 2 评论 -
DAB-DETR代码学习记录之模型解析
在Decoder部分的(Anchor Boxes)中,其初始化为【2,300,4】会通过,x,y,w,h都会进行,都转换为128维度,4个即为512维,随后通过一个MLP转换为256。位置编码方式如下:总共4个,被编码维128维。下面是其主要的一个创新点,加入了宽高调制的注意力机制,之所以这样做是让注意力能够对宽高也比较敏感。原创 2023-04-20 09:06:44 · 1641 阅读 · 0 评论 -
Windows环境下调试DAB-DETR与Deformable-DETR
先前都是在服务器上运行DETR的相关程序,服务器使用的是Linux,所以运行较为简单,但如果想要简单的debug的话就没必要使用服务器了,今天便来在Winodws环境下调试DETR类项目,这里以Deformable-DETR与DAB-DETR为例。首先是DAB-DETR的配置,这个部分较为简单,需要注意的是DAB-DETR不需要配置CUDA算子,如果我们只想执行DAB-DETR程序的话我们将DAB-Deformable-DETR的引入模块删掉即可。同时注释掉model/init下的这段代码。原创 2023-04-19 13:24:31 · 1500 阅读 · 2 评论 -
匈牙利算法学习记录
匈牙利算法主要用来解决两个问题:求二分图的最大匹配数和最小点覆盖数。匈牙利算法事实上有两个算法,分别解决指派问题和二分图最大匹配求解问题,此处算法指求解指派问题的匈牙利算法。原创 2023-04-14 11:16:46 · 557 阅读 · 0 评论 -
DN-DETR源码学习记录
DN-DETR是在DAB-DETR的基础上完成的,DN-DETR的作者认为导致DETR类模型收敛慢的原因在于匈牙利匹配所导致的二义性,即匈牙利算法匹配的离散性和模型训练的随机性,导致ground-truth的匹配变成了一个动态的、不稳定的过程。举个例子,在epoch=8时,1号预测框与2号真实框匹配,但到了epoch=9时,5号预测框与2号真实框相匹配。原创 2023-04-13 19:43:10 · 1051 阅读 · 0 评论 -
Deformable DETR模型学习记录
多尺度的特征融合方法则是取了骨干网(ResNet)最后三层的特征图C3,C4,C5,并且用了一个Conv3x3 Stride2的卷积得到了一个C6构成了四层特征图。其他方面,Deformable相较于DETR修改了query-num的数量,改为300,但在推理过程中其会仍使用top100的预测框,此外在匈牙利匹配的cost矩阵构建时class的损失由原本的softmax简单运算变为了Focus loss。过一个nn.Linear,得到多组偏移量,每组偏移量的维度为参考点的个数,组数为注意力头的数量。原创 2023-04-11 21:22:39 · 1468 阅读 · 3 评论 -
GPU服务器环境配置踩坑
今天在购买腾讯云服务器时,不小心选择错了环境,也就只能重装系统,然而重装后的系统中没有装入conda环境,需要自己手动按照一下:博主选择安装miniconda。原创 2023-04-07 15:32:41 · 308 阅读 · 1 评论 -
DETR代码学习(五)之匈牙利匹配
匈牙利匹配先前在损失函数那块已经介绍过,但讲述了并不清晰,而且准确来说,匈牙利匹配所用的cost值与损失函数并没有关系,因此今天我们来看一下匈牙利匹配这块的代码与其原理。前面已经说过,DETR将目标检测看作集合预测问题,在最后的预测值与真实值匹配过程,其实可以看做是一个二分图匹配问题,该问题的解决方法便是匈牙利算法。原创 2023-04-04 11:29:27 · 7011 阅读 · 4 评论 -
DN-DETR调试记录
博主在进行DINO实验过程中,发现在提取了3个类别的COCO数据集中,DINO-DETR对car,truck的检测性能并不理想,又通过实验自己的数据集,发现AP值相差不大且较为符合预期,因此便猜想是否是由于DINO中加入了负样本约束导致背景难以学习进而使效果差,因此便使用了DN-DETR来进行实验。下图为DN-DETR模型框架图。接下来介绍自己的实验过程。由于DN-DETR也是DETR模型的一部分,所以我们不需要再额外配置conda环境了,使用原本的detr的conda环境即可。原创 2023-04-02 13:45:30 · 708 阅读 · 1 评论 -
DETR-like模型输出各类别AP值
而博主想要显示每个类别的的AP值,因此查询了相关资料发现,DETR类模型框架的AP值计算输出这块都是由pycocotools的coco.py和cocoeval.py负责完成的。原创 2023-03-27 16:00:16 · 1257 阅读 · 5 评论 -
DAB-DETR模型学习记录
这篇论文中的贡献之一便是回答了Query到底是什么,Decoder中的Query与Encoder中的key(图像特征)做交互,从中提取信息并试驾到Value上,形成新的feature,而加入了位置先验信息后,那么Query在与key交互时便不再盲目提取语义信息,由于位置编码的约束,其就会相当于从不同的框中去提取语义信息,那么Query就类似于Fast-R-CNN中的ROI Pooling。原创 2023-03-30 20:49:19 · 1678 阅读 · 1 评论 -
DETR源码讲解(四)之注意力计算
24,256分别是128行编码与28列编码,这是设定好的。query_embed:torch.Size([100, 2, 256]) ,其为decoder预测输入,即论文中反复提到的object queries,每帧预测num_queries个目标,这里预测100个。其最开始时是进行随机初始为0的,之后会加上位置编码信息。这个意思是想让query对位置较为敏感,或者说应该有自己所关注的范围,不能越界。原创 2023-03-21 16:02:25 · 1199 阅读 · 0 评论 -
DETR模型简易代码
可以看出,代码非常简练,通过实验pytorch在封装的backbone,Transformer模型以及一些全连接层,卷积层的组合便实现了DETR模型的构造。在DETR模型的论文的末尾,其给出了DETR模型的伪代码,严格意义上来讲其并非是伪代码,因为其是可以正常运行的代码。原创 2023-03-22 20:48:47 · 567 阅读 · 1 评论 -
DN-DETR论文学习
本文提出了一种新颖的去噪训练方法,以加快DETR(DEtection TRansformer)训练,并加深了对类DETR方法的慢收敛问题的理解。我们表明,缓慢收敛是由于二分图匹配的不稳定性导致早期训练阶段的优化目标不一致。为了解决这个问题,除了匈牙利损失之外,我们的方法还向Transformer解码器馈送了带有噪声的GT边界框,并训练模型重建原始框,从而有效地降低了二分图匹配难度,并加快了收敛速度。我们的方法是通用的,可以通过添加数十行代码轻松插入任何类似 DETR 的方法,以实现显着的改进。翻译 2023-03-31 09:48:16 · 876 阅读 · 0 评论 -
DAB-DETR论文学习记录
在本文中,1.我们提出了一种使用动态锚框进行DETR(DEtection TRansformer)的新颖查询公式,并提供了对查询在DETR中的作用的更深入理解。这个新公式直接使用框坐标作为转换器解码器中的查询,2.并逐层动态更新它们。使用框坐标不仅有助于使用显式位置先验来提高查询特征相似性并消除 DETR 中缓慢的训练收敛问题,3.而且还允许我们使用框宽度和高度信息来调节位置注意力图。这样的设计清楚地表明,DETR 中的查询可以作为以级联方式逐层执行软 ROI 池化来实现。原创 2023-03-30 17:19:10 · 938 阅读 · 0 评论 -
DETR-like 模型环境配置
这不要紧,我们在真正运行该项目时只需要调整batch-size即可,此时博主使用的显卡未NVIDIA P40,显存为24G,可以说已经足以满足需要了。首先是进行项目下载,由于博主此时并未对项目进行大量更改,只需要从github上直接git即可。再次配置即可,test.py主要进行一个维度计算测试,与你的GPU显存有关。至此,DINO-DETR的环境配置便完成了,只需要上传完数据集即可运行了。可以看到博主在进行 2048通道计算时爆显存了。然后再进行pycocotools的安装。紧接着配置CUDA算子。原创 2023-03-26 16:39:45 · 525 阅读 · 0 评论 -
DINO-DETR 实验与分析
但让我想不通的是,博主的数据集并非是直接减少,而是按照不同类别进行提取,对于某个类别而言,其不该有如此大的差距。2.按照目前对Transformer的研究来看,其效果一般在数据量及其庞大的情况下越好,因此博主虽然是按照类别进行提取了,但不可否认的是数据集数量大大缩水,所以导致了实验效果差。在验证的过程中,博主也发现,先前的loss值最多只能下降到6.2便不再下降,而在使用论文中提供的权重文件时,其可以下降到3.1左右,这倒是令我感到意外。1.博主的类别提取方法有问题,提取的数据集有问题(太可怕了)原创 2023-03-21 19:38:26 · 1098 阅读 · 2 评论 -
DINO-DETR在COCO缩减数据集上实验结果分析
博主在进行DINO-DETR模型实验时,使用缩减后的COCO数据集进行训练,发现其mAP值只能达到0.27作用,故而修改了下pycocotool的代码,令其输出每个类别的AP值,来看看是由于什么原因导致这个问题。首先在我们缩小的COCO数据集上,尽管car的标注较多,但目标都较小,而且存在很大程度的遮挡。上述实验结果首先证明了博主的猜想,即各个类别的AP值是不同的,也就说明其并非是对所有类别信息都有一个较好的结果。对应car,bus,truck为:0.49,0.72,0.42,map值为0.54。原创 2023-03-27 21:02:01 · 1135 阅读 · 2 评论