






点击蓝字 关注我们
人工编写高质量的单元测试用例费时费力。复旦大学CodeWisdom团队近期对ChatGPT的单元测试能力进行全面评估,并进一步提出基于ChatGPT的高质量单元测试生成框架ChatTester。更多细节参照论文Arxiv Preprint版本(https://arxiv.org/pdf/2305.04207.pdf),点击末尾“阅读原文”可跳转。
01
能力评估:“ChatGPT可以
代替开发者来写单元测试用例吗?”
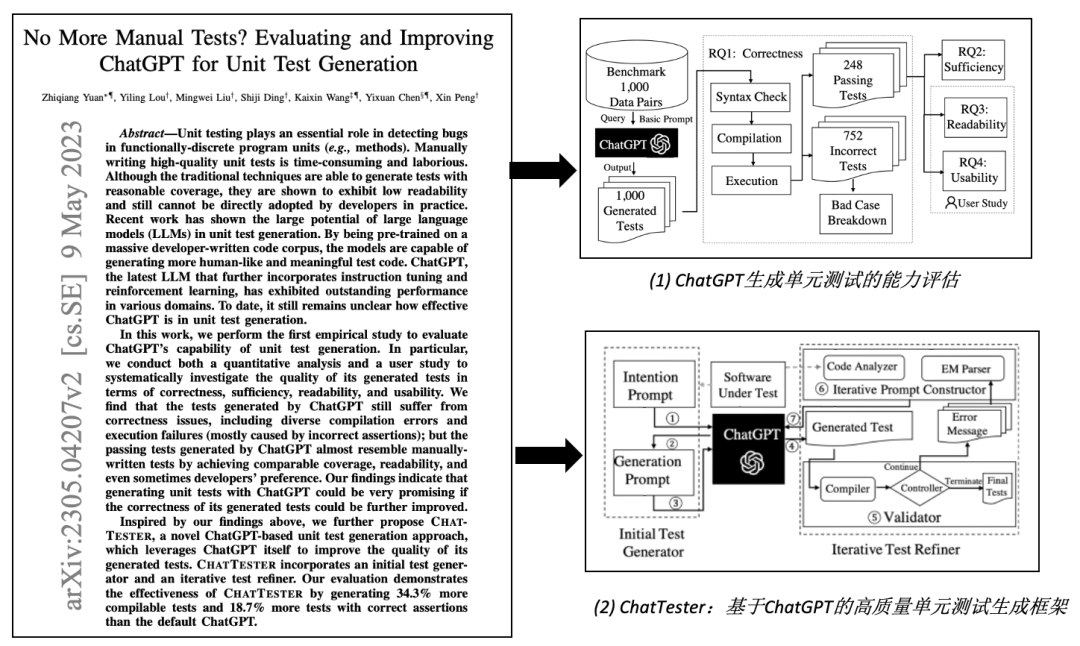
为了解答这个问题,我们对ChatGPT写出的1000个Junit单元测试用例在正确性、充分性、可读性等多个维度进行了全面评估。我们用图1中所示的提示模版让ChatGPT为给定的被测代码片段生成单元测试(注:本文关注GPT-3.5-turbo 模型)。

图1:提示示例
1.1 正确性评估
正确性:ChatGPT生成测试正确性仍然不足,仅有24.8%可顺利执行,58.9%和17.3%面临编译错误和运行错误。其中常见的编译错误包括符号解析错误、类型错误和访问错误等。而大多数执行错误是由于ChatGPT生成的错误断言语句导致的。
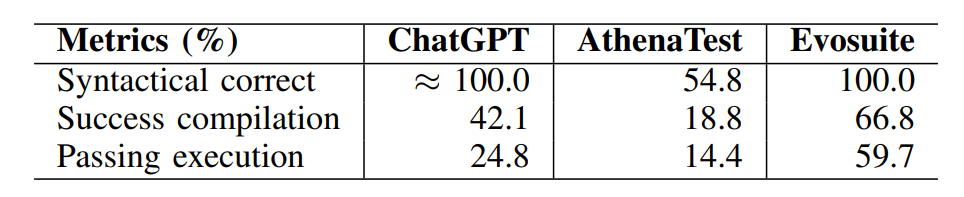
表1: ChatGPT、AthenaTest(基于深度学习的测试生成方法)、EvoSuite(基于搜索的测试生成方法)所生成测试的语法/编译/执行通过率
· 整体正确性。由表1所示, ChatGPT生成测试在正确率上并不理想,只有42.1%用例可通过编译,24.8%的用例可正确执行。但相比之前的基于学习的测试生成方法(AthenaTest),ChatGPT所生成测试用例的语法、编译和执行正确性更高。
· 常见编译错误。表2列举了ChatGPT生成测试用例中常见的编译错误类型分布。其中,最常见的编译错误为符号解析失败(如使用未定义的方法和变量等);另一个大类编译错误与类型相关(如函数调用中的参数类型与方法声明中的不一致);此外,ChatGPT所生成的错误测试代码会访问私有变量或方法、或对抽象类进行无效实例化。

表2 常见编译错误分类
· 常见执行错误。表3列举了测试用例执行错误的类型和频率,大多数执行失败(85.5%)是由于ChatGPT生成了错误的测试断言所造成。
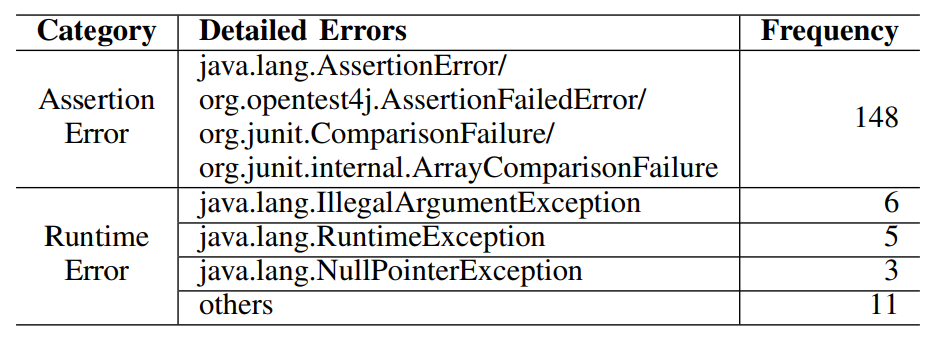
表3 常见执行错误分类
1.2 测试充分性评估
测试充分性:ChatGPT 生成测试的覆盖率与人工编写的测试相接近,并高于现有的测试生成技术。
表4展示了各生成用例的语句覆盖率和分支覆盖率。ChatGPT生成的测试用例实现了最高的测试覆盖率,并十分接近人工编写的水准。

表4 生成测试的覆盖率
1.3 测试可读性评估
可读性:ChatGPT 生成的测试具有良好的可读性,与人工编写的测试相比具有相近的可读性水平。
如图 2所示,其中X轴表示每个参与者(即从 A 到 E),Y轴表示不同得分比例的堆积条形图。总体而言,大多数 ChatGPT 生成的测试都被评为具有良好的可读性,并与人工编写的测试相近。
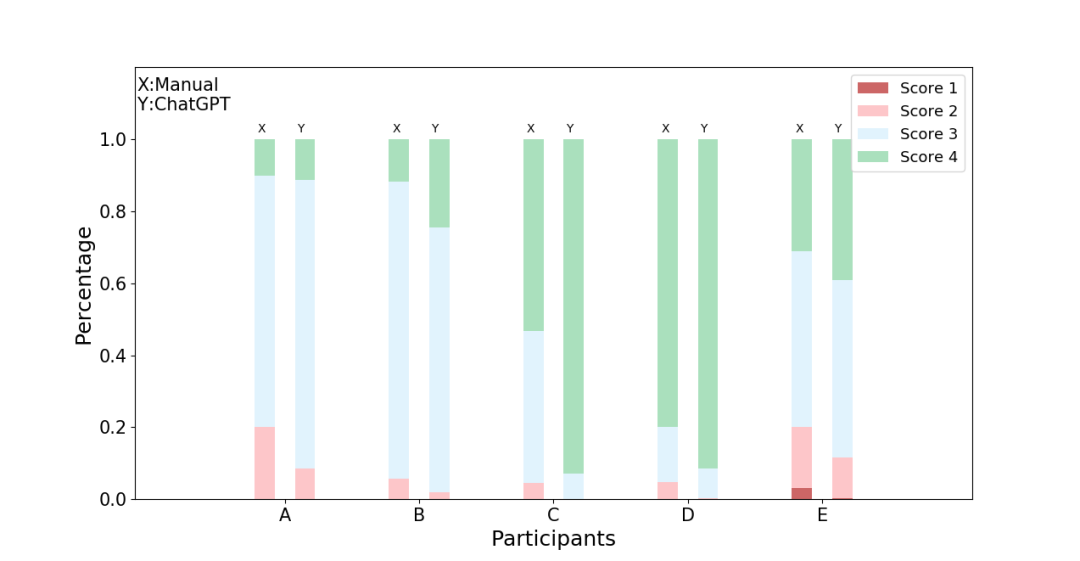
图2 测试的可读性评估
02
能力提升:基于ChatGPT的高质量
单元测试生成框架 ChatTester
受上述研究结果的启发,我们进一步提出了ChatTester,一个基于ChatGPT的高质量单元测试生成框架。ChatTester通过引入初始测试生成器(initial test generator)和迭代测试优化器(iterative test refiner)进一步提升ChatGPT生成单元测试用例的质量。
2.1 ChatTester方法简介
· 初始测试生成器(initial test generator) 将测试生成的任务分解成了两个子任务:首先通过intention prompt让 ChatGPT理解被测代码的意图;然后通过generation prompt,令ChatGPT基于被测代码的意图为其生成单元测试。与basic prompt相比,初始测试生成器通过意图推断这一中间步骤帮助ChatGPT生成质量更高的测试断言。例如 ,图3对比了basic prompt和初始测试生成器如何为被测函数“setCharAt()”生成测试的例子。如图3(a)所示,给定没有任何意图推断的basic prompt,ChatGPT生成了包含错误断言的测试(即“assertEquals(Hello-World, strBuilder.toString())”)。在图3(b)中,通过intention prompt,ChatGPT首先正确生成了被测函数“setCharAt()”的意图描述;然后通过generation prompt,ChatGPT生成了带有正确断言的测试(即“assertEquals(Hello Jorld, strBuilder.toString())”)。

图3 basic prompt v.s. 初始测试生成器中的提示
· 迭代测试优化器(iterative test refiner) 通过迭代的方式修复初始测试生成器所生成测试中的编译错误。每次迭代都会依次执行两个步骤:(i)首先通过在验证环境中编译生成的测试来验证测试的正确性;(ii)其次根据编译过程中的错误消息和与编译错误相关的额外代码上下文构建提示。将构建好的提示输入到ChatGPT当中,以获得更加完善的测试。该修复过程不断重复直到生成的测试能够成功编译或达到最大迭代次数。图4展示了一个迭代测试优化器如何在两次迭代中修复了测试用例中的编译错误的例子。

图4 迭代测试优化器的提示示例
2.2 ChatTester效果评估

表5 ChatTester的有效性评估
如表5所示,与ChatGPT相比,ChatTester生成测试的编译率和执行通过率有了大幅提升。其中,ChatTester-是ChatTester移除迭代提升器的对照组方法。因此,ChatTester 、ChatTESTER-、ChatGPT三者之间的差距,也同时说明了ChatTester中迭代细化器和初始测试生成器这两个部分的有效性。
03
结尾
整体来说,基于大规模语言模型(如ChatGPT)的单元测试生成是一个具有潜力的方向。开发者不再需要手写单元测试的场景在不远的未来也许并不是梦。如何更好地将外部工具(编译、执行、分析信息)与大模型在测试生成场景下结合、如何构建更好的提示输入、以及如何将大模型在测试生成领域中微调,都会是未来进一步提升大模型测试生成能力的重要研究方向。
复旦大学 CodeWisdom团队
作者| 袁志强 娄一翎 刘名威 彭鑫
排版| 孙婕
审核| 娄一翎 彭鑫














 830
830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









