







最近在做一个聊天记录的分析,想要构建一个指标,标记出每个人的连续发言条数,中间犯过好几次错误,总是算错,后来在才哥这篇帖子的启发下,想到了一个解决方案,而且会很简单。后来做完才发现才哥在最后已经把方法写出来了……
- 直接上实现方法
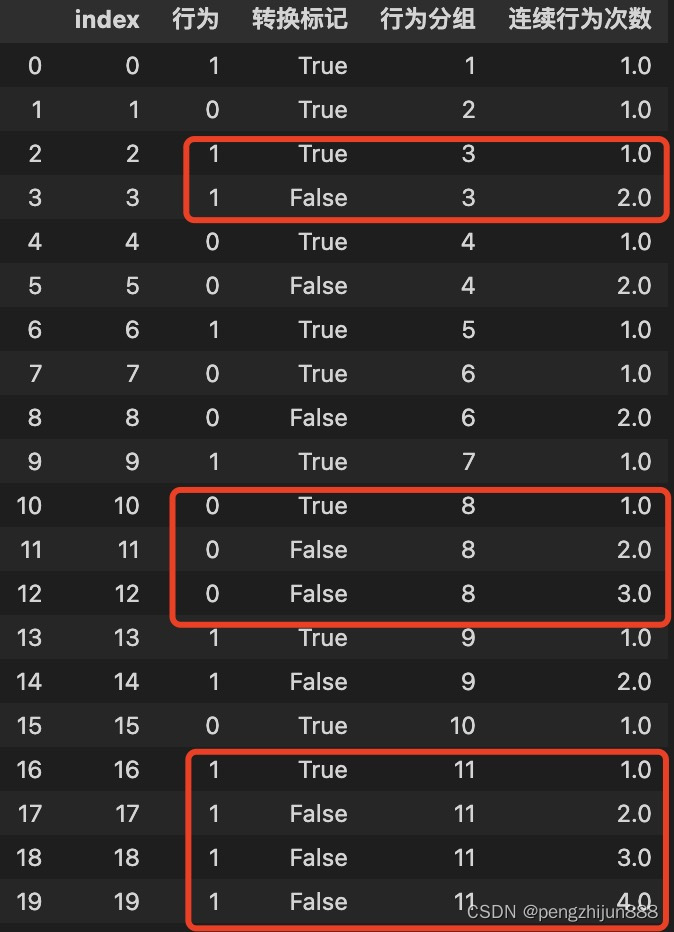
假设我们现在要对如下的行为,统计连续行为的发生次数。可以看到在‘连续行为次数’这一列中,计算出了每组连续行为的连续次数,而且只用了3行代码,而且还很好理解计算过程!
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randint(0,2,20), columns=['行为']).reset_index()
df['转换标记'] = df['行为']!=df['行为'].shift() # 识别信号,判断行为是否发生了改变
df['行为分组'] = df['转换标记'].cumsum() # 辅助列,根据识别信号,对相邻的相同行为进行分组,便于计算每组相同行为的连续发生次数
df['连续行为次数'] = df.groupby(['行为分组'])['index'].rank(method='dense') # 根据行为分组,使用窗口函数对每条行为标记连续发生次数
display(df)
这里用了一个比较巧妙且符合人脑逻辑的方法对连续行为进行标注,比较难的可能就是最后的窗口函数的排序。先放个链接凑活着解释一下窗口函数的排序(rank)。















 3146
3146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









