






目录
数据来源
滴滴国际部2020年2月数据分析实习生笔试题
内容:2018年3月5日-2018年3月11日期间100名巴西乘客的订单基础信息
字段释义
| 字段 | 中文名称 | 解释 |
|---|---|---|
| order_id | 订单ID | 呼叫订单识别号 |
| passenger_id | 乘客ID | 乘客识别号 |
| call_time | 呼叫时间 | 乘客从应用上发出需要用车的请求的时间点(北京时间) |
| grab_time | 应答时间 | 司机点击接单的时间点(北京时间) |
| cancel_time | 取消时间 | 司机或者乘客取消订单的时间(北京时间) |
| finish_time | 完单时间 | 司机点击到达目的地的时间点(北京时间) |
指标释义
| 指标名称 | 含义 | 统计口径 |
|---|---|---|
| 应答率 | 呼叫订单被应答的比例 | 应答订单/呼叫订单 |
| 完单率 | 呼叫订单被完成率 | 完成订单/呼叫订单 |
| 呼叫应答时间 | 被应答订单从呼叫到被应答平均时长 | 被应答订单从呼叫到被应答时长总和/被应答订单数量 |
其他信息
巴西比中国慢11小时
加载包
import numpy as np
import pandas as pd
import datetime
加载数据
data = pd.read_csv('dididata.csv')
data.head()
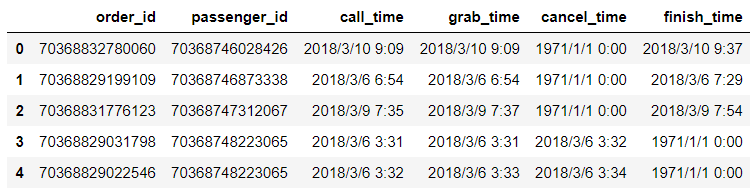
数据预处理
# 查看各字段格式
data.info()

4个时间数据为object,需要将其改为datetime
data['call_time'] = pd.to_datetime(data['call_time'])
data['grab_time'] = pd.to_datetime(data['grab_time'])
data['cancel_time'] = pd.to_datetime(data['cancel_time'])
data['finish_time'] = pd.to_datetime(data['finish_time'])
data.info()

没有空值,说明未应答、未取消、未完成的订单时间不是以空值存储,检查后发现这些数据是记为1971-01-01 00:00:00
将其替换为空值,便于后续分析
data.loc[data['grab_time']=='1971-01-01 00:00:00','grab_time']= np.nan
data.loc[data['cancel_time']=='1971-01-01 00:00:00','cancel_time'] = np.nan
data.loc[data['finish_time']=='1971-01-01 00:00:00','finish_time']= np.nan
data.info()
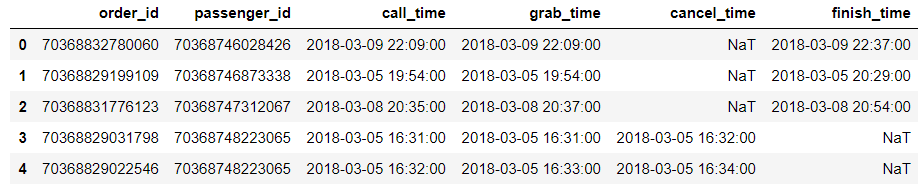
巴西比中国慢11小时,将表中北京时间转换为巴西时间
data['call_time']-=datetime.timedelta(hours=11)
data['grab_time']-=datetime.timedelta(hours=11)
data['cancel_time']-=datetime.timedelta(hours=11)
data['finish_time']-=datetime.timedelta(hours=11)
data.head()
问题
1 订单的应答率、完单率分别是多少?
print('应答率:',data['grab_time'].count()/data['call_time'].count())
print('完单率:',data['finish_time'].count()/data['call_time'].count())
应答率: 0.7239057239057239
完单率: 0.4713804713804714
2 呼叫应答时间多长?
diff = (data['grab_time']-data['call_time']).sum()/data['grab_time'].count() # 获取平均时间,得到numpy.timedelta64 纳秒时间差
diff = diff / np.timedelta64(1,'m') # 将 纳秒 转换为 分钟
print('呼叫应答时间:',diff,'分钟')
呼叫应答时间: 0.7255813953333333 分钟
3 呼叫量最高的是哪一个小时(当地时间)?呼叫量最少的是哪一个小时(当地时间)?
data.groupby(data['call_time'].dt.hour).call_time.count().sort_values(ascending=False)
call_time
18 40
20 25
23 21
19 21
14 20
16 18
13 15
9 14
0 14
15 13
12 12
22 10
10 10
21 10
8 9
17 8
7 8
11 8
5 7
6 6
4 3
1 3
3 1
2 1
Name: call_time, dtype: int64
呼叫量最高的是18时,呼叫量最少的是2时和3时。(当地时间)
4 呼叫订单第二天继续呼叫的比例有多少?
(1)按订单数计算
# 新增一列呼叫日期的天数,方便计算
data['day'] = data['call_time'].dt.day
# 将表根据passenger_id进行左连接
data2 = data.merge(data,on='passenger_id',how='left')
# 筛选出第二次呼叫比第一次呼叫晚一天的数据
data2 = data2[(data2['day_y']-data2['day_x'])==1]
# 为避免前一天有多个订单,造成第二天的订单重复计算,对第二天的订单号进行去重
print('结果为:',data2.drop_duplicates(subset=['order_id_y']).order_id_x.count() / data.day.count())
结果为: 0.32996632996632996
(2)按乘客数计算
# 在连接好的表中,对乘客id进行去重,得到第二天继续呼叫乘客数
result = data2.drop_duplicates(subset='passenger_id').passenger_id.count() / data.drop_duplicates(subset='passenger_id').passenger_id.count()
print('结果为:',result)
结果为: 0.3472222222222222
5 如果要对表中乘客进行分类,你认为需要参考哪一些因素?
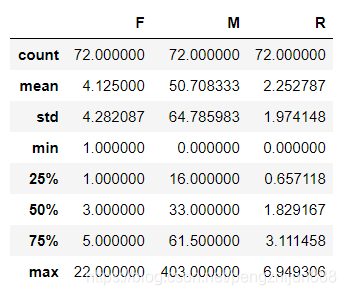
基于已有的表格中数据,可以用RFM模型对用户进行分类,
R:乘客上一次打车距离3月11日的时间间隔
F:乘客在数据期间的打车频率
M:打车消费金额(表中无打车金额,可以用完成订单总时长代替)
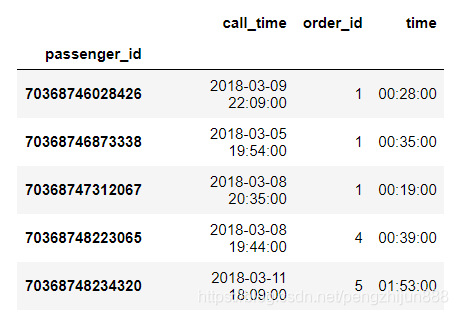
data['time'] = data['finish_time'] - data['call_time']
rfm = data.groupby('passenger_id').aggregate({
'call_time': max,
'order_id': 'count',
'time': sum
})
rfm.head()
rfm['R'] = (rfm['call_time'].max() - rfm['call_time'])/np.timedelta64(1,'D')
rfm['time'] = rfm['time']/np.timedelta64(1,'m')
rfm.rename(columns={'order_id':'F','time':'M'},inplace=True)
rfm.head()
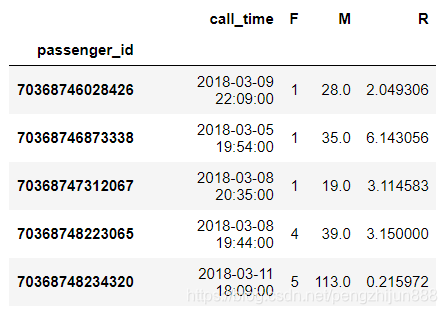
rfm.describe()
def RFM(x):
level = x.apply(lambda x:'1' if x>0 else '0')
label = level['R']+level['F']+level['M']
d = {
'011':'重要价值客户',
'001':'重要发展客户',
'111':'重要保持客户',
'101':'重要挽留客户',
'010':'一般价值客户',
'000':'一般发展客户',
'110':'一般保持客户',
'100':'一般挽留客户'
}
result = d[label]
return result
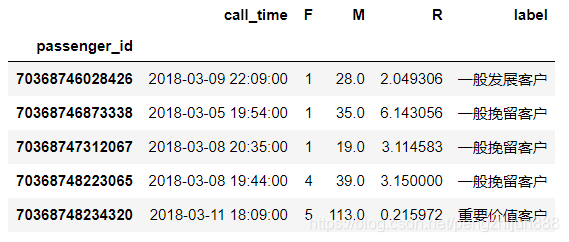
rfm['label'] = rfm[['R','F','M']].apply(lambda x:(x-x.mean())).apply(RFM,axis=1)
rfm.head()
rfm.groupby(['label']).aggregate({
'F':'count',
'M':sum
})
一般挽留客户和一般发展客户比较多,都是21人;
重要价值客户有13人,乘车时长远高于其他客户群














 911
911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









