






近期,小米 AI 实验室大模型团队和清华大学计算机系刘洋老师团队联合提出了面向工具检索的全新重排序框架 ToolRerank,并被 LERC-COLING 2024主会长文录取。
LERC-COLING 是两大计算语言学领域具有国际影响力的组织语言资源协会(ELRA)和国际计算语言学委员会(ICCL)联合举办的会议,合并了 LERC 和 COLING 这两个会议,是自然语言处理和人工智能领域具有广泛影响力的国际会议之一。该会议将于2024年5月20日至25日在意大利都灵召开。

大语言模型作为 AI agent,包括四大核心功能:规划、工具、执行和记忆。其中工具能力能够让大语言模型调用大量已知接口或者模型,极大扩展了大语言模型的能力边界。大语言模型的工具调用能力能够广泛应用到小米的产品中。
以 HyperOS 为例,大模型通过调用系统底层和 IoT 接口,能够让用户仅仅通过简单的自然语言命令,实现对于系统的操作和智能家居的控制。ToolRerank 是小米大模型团队在这一方向上的一次探索,希望在不重新训练模型的情况下,就能实现调用新工具的能力。
一、研究背景
近年来,大语言模型在不同的任务上都取得了良好的泛化能力。然而,大语言模型仍然无法有效地解决某些类型的问题。例如,在没有外部资源辅助的情况下,大语言模型通常无法回答与最新事件有关的问题。此外,大语言模型也很难准确回答数学问题和用低资源语言编写的问题。而在这些问题上,前人其实已经积累了大量工具。因此,许多研究提出了工具学习的方法,尝试利用外部工具扩展大语言模型的能力。
实现工具学习的一种方法是在大语言模型的输入中提供 API 文档的信息,让大语言模型调用工具解决用户的请求。然而,提供的文档数量受到大语言模型的上下文长度的限制,因此在工具数量很多的情况下使用这种方法非常困难。
为了解决这个问题,一种可能的方法是微调大语言模型,使其能在不提供文档的情况下使用工具。然而,当工具库频繁更新时,这种方法不太方便,因为每次都需要重新微调模型。相比之下,基于检索的方法可以根据用户请求从工具库中检索出合适的工具,即使不重新训练模型,也可以使用之前未见过的新工具。因此,本工作中,我们主要针对基于检索的方法进行改进。
关于工具学习,目前已经提出的检索方法主要包括三类:基于 BM25的方法、基于大语言模型的方法和基于双编码器模型的方法。然而,这些方法都有它们的局限性。
基于 BM25的方法利用字面相似度进行检索,因此通常无法理解 API 文档和用户请求在语义逻辑上的关系,导致检索效果不佳。
基于大语言模型的方法利用大语言模型判断工具是否适合解决用户请求,因此检索效率受制于大语言模型的推理速度。
基于双编码器模型的方法使用两个独立的编码器,计算用户请求和 API 文档之间的余弦相似度,然后根据余弦相似度的高低选择合适的工具。虽然这种方法能够取得效率和检索性能之间的平衡,但在用户请求和 API 文档之间缺乏细粒度的交互,因此其性能对于工具学习来说仍然不完美。综上所述,如何有效地实现工具检索仍然是一个挑战。
为了解决这一问题,我们提出借鉴信息检索领域中的重排序方法,在不显著降低检索效率的同时提高检索的性能。所谓重排序,是指用一个性能更好但计算复杂度更高的模型对检索出的少量候选结果根据相关性进行重新排序,以得到更准确的检索结果。通常而言,我们可以使用交叉编码器进行重排序,使用户请求和 API 文档之间可以进行细粒度的交互。然而,这种重排序方法未能充分考虑工具学习的特点,导致其效果对于工具检索来说并非是最优的,因此我们充分考虑了工具学习的特点,提出了针对工具检索的重排序框架 ToolRerank,以提高工具检索的性能。
二、挑战与动机
在信息检索领域广泛使用的基于交叉编码器的重排序方法通常将检索到的固定数量的候选结果进行重新排序。然而,这种方法运用到工具检索时有以下两个挑战:
未能考虑大模型已知的和新增的工具的区别:在工具学习中,工具库并非是固定不变的,有可能会根据需要添加新的工具,但重排序模型在已知的和新增的工具上的行为有一定的差异,如图1所示。具体地,对于已知的工具,重排序模型的性能在候选结果的数量较少时较好;对于新增的工具,重排序模型的性能在候选结果的数量较多时较好;
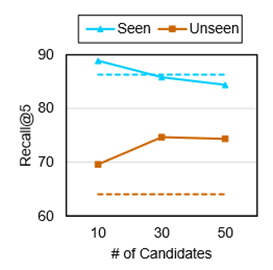
图1 候选结果数量对重排序模型性能的影响
未能考虑工具库的结构:如图2所示,工具库通常存在一定的结构,一个工具中可能会包含多个 API。在现实中,某些请求用同一个工具的不同 API 就能解决(单工具请求;single-tool query),这种情况下检索结果最好是集中在同一个工具。另外一些请求需要用来自不同工具的 API 才能解决(多工具请求;multi-tool query),这种情况下检索结果最好是分散在不同的工具。
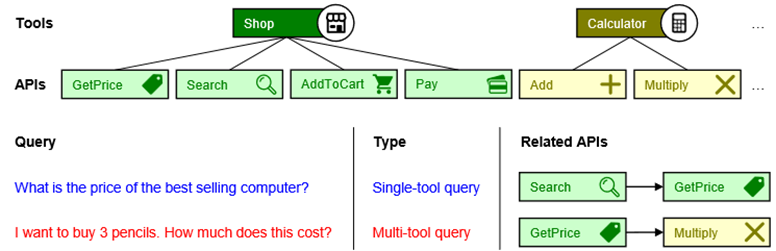
图2 工具库结构示意图
然而,重排序模型本身无法将这些问题纳入考虑,因此其性能对工具检索来说并非是最优的。因此,为了应对上述挑战,我们需要关注以下两个关键因素:
重排序方法应当能够应对已知的和新增的工具的区别,以适应重排序模型在已知的和新增的工具上的行为差异;
重排序方法应当充分考虑工具库的结构,使细粒度的检索结果更集中(对单工具请求)或更分散(对多工具请求)。
三、ToolRerank 框架介绍
如图3所示,我们的 ToolRerank 框架根据用户请求给出细粒度的检索结果,其主要包含两个关键技术模块:
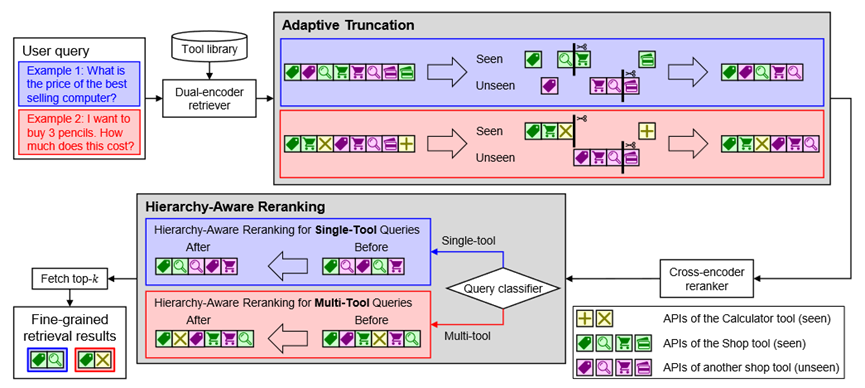
图3 ToolRerank 框架示意图
适应性截断(Adaptive Truncation):我们对于粗粒度的检索结果中,属于已知的和新增的工具的候选项分别在不同位置处进行截断,然后将截断后的结果合并后给基于交叉编码器的重排序模型进行重排序。
具体地,属于已知工具的候选项的截断位置比属于新增工具的候选项的截断位置更靠前。因此当用户请求主要与已知工具有关时,给重排序模型提供的候选项数量较少;而当用户请求主要与新增工具有关时,给重排序模型提供的候选项数量较多。因此适应性截断可以更好地适应重排序模型在已知的和新增的工具上的不同行为;
结构有关的重排序(Hierarchy-Aware Reranking):我们在使用基于交叉编码器的重排序模型进行重排序后,再根据用户请求属于单工具请求还是多工具请求,对检索结果进行进一步的重排序。
具体地,我们首先用一个分类模型对请求进行分类。然后根据分类模型给出的结果,采用不同的重排序策略进行重排序。如果分类模型认为用户请求是单工具请求,则会使排在前面的检索结果更加集中;如果分类模型认为用户请求是多工具请求,则会使排在前面的检索结果更加分散。因此结构有关的重排序可以更好地适应工具库的结构。
四、实验
我们在 ToolBench 数据集上进行实验,该数据集包含6个子集:I1-Inst、I2-Inst、I3-Inst、I1-Tool、I1-Cat 和 I2-Cat。其中 I1-Inst、I2-Inst 和 I3-Inst 主要与已知工具有关,I1-Tool、I1-Cat 和 I2-Cat 主要与新增工具有关。I1-Inst、I1-Tool、I1-Cat 中的用户请求属于单工具请求,I2-Inst、I3-Inst 和 I2-Cat中的用户请求属于多工具请求。
对比的基线方法包括:BM25、DPR(基于双编码器模型的检索,无重排序)、Rerank-{10, 30, 50}(基于交叉编码器的重排序方法,候选项个数固定)。如图4所示,实验结果表明,我们提出的 ToolRerank 框架显著提高了工具检索的性能。
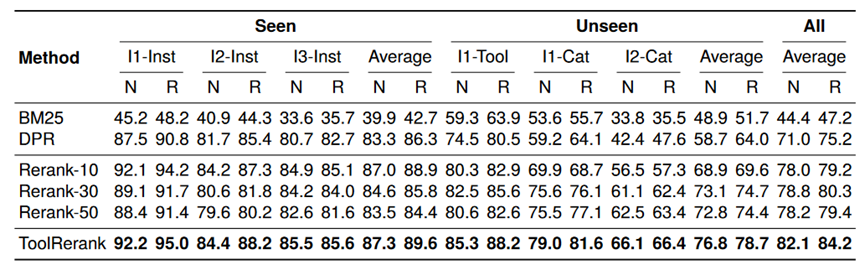
图4 实验结果
为验证我们的方法对工具学习性能的影响,我们使用检索到的工具,让 ToolLLaMA 模型解决用户请求,并测试通过率(Pass Rate)和获胜率(Win Rate)。实验结果表明,我们提出的 ToolRerank 框架提高了通过率和获胜率,进一步说明了 ToolRerank 框架的优势。然而,相比直接提供标准答案中的工具时(Oracle)的获胜率,ToolRerank 的获胜率仍然显著偏低,说明重排序方法仍然有较大的改进空间。
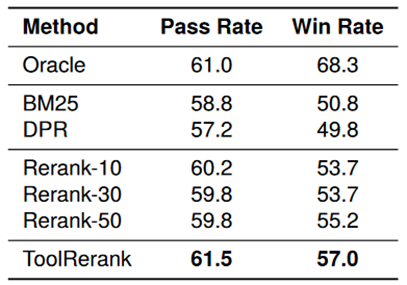
图5 检索方法对工具学习性能的影响
为了直观地说明 ToolRerank 是如何提高工具检索的性能的,我们还进行了两个实例分析。对于图6中的单工具请求,有一个正确的 API “/get_movies_by_year”在使用交叉编码器进行重排序后排在第22位,但它所属工具“IMDB_API”与排在第一位的“/get_movies_by_director”相同,因此 ToolRerank 将“/get_movies_by_year”的排名提前到了第4位,使排名靠前的检索结果更好地集中在“IMDB_API”这个工具。
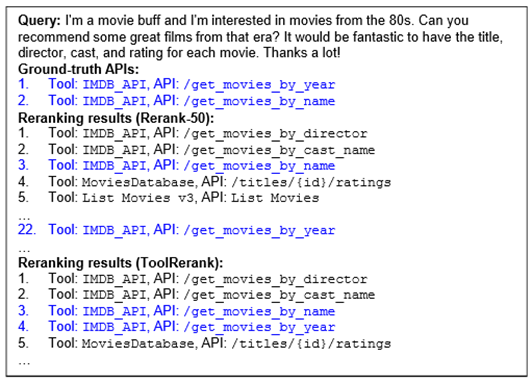
图6 单工具请求的实例分析
对于图7中的多工具请求,有一个正确的 API “Analyze V2”在使用交叉编码器进行重排序后排在第9位,但排在第2-8位的 API 全部都和二维码(QR code)相关,因此我们认为它们的功能彼此之间都很相似。为了避免在排名靠前的检索结果中集中出现太多功能相似的 API,我们只保留下了排名在第2-4位的三个与二维码相关的 API,剩下的都排到后面,使得“Analyze V2”的排名提前到了第5位,避免了在排名靠前的检索结果中与二维码相关的 API 过多地集中出现。
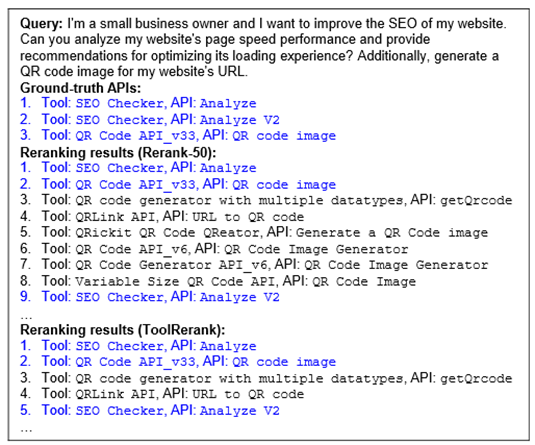
图7 多工具请求的实例分析
五、总结
我们提出了用于工具检索的重排序框架 ToolRerank。针对已知的和新增的工具之间的区别,以及工具库的结构特点,分别提出了适应性截断和结构有关的重排序这两个关键技术模块。在 ToolBench 数据集上的实验结果表明,ToolRerank 显著提高了工具检索的性能,进而也提高了大语言模型的工具学习性能。
论文已开源:https://arxiv.org/abs/2403.06551
END




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









