






这是一个学习大模型的Demo,使用的都是开源的项目,这里也开源分享
开源大模型学习、Hugging Face、图生文
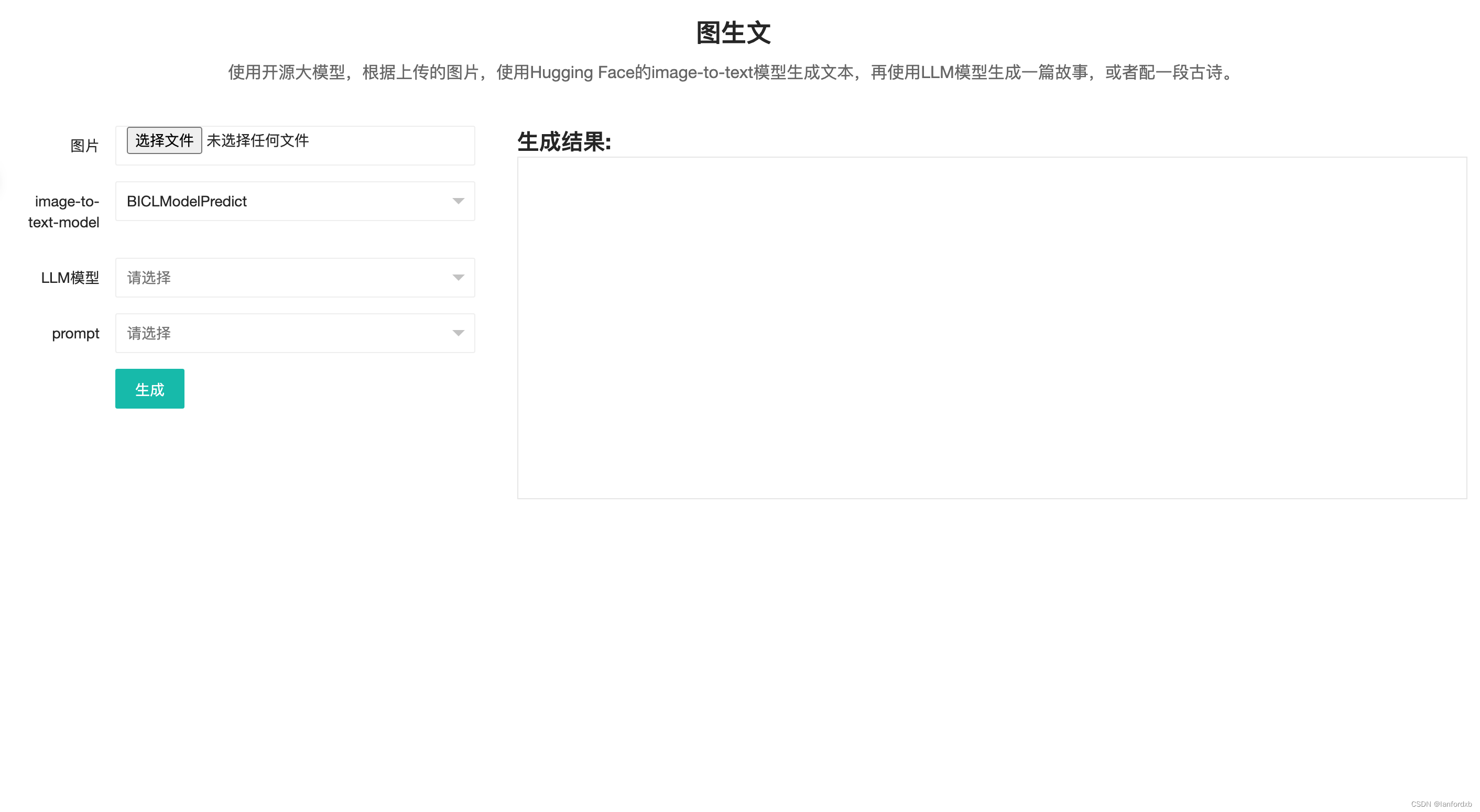
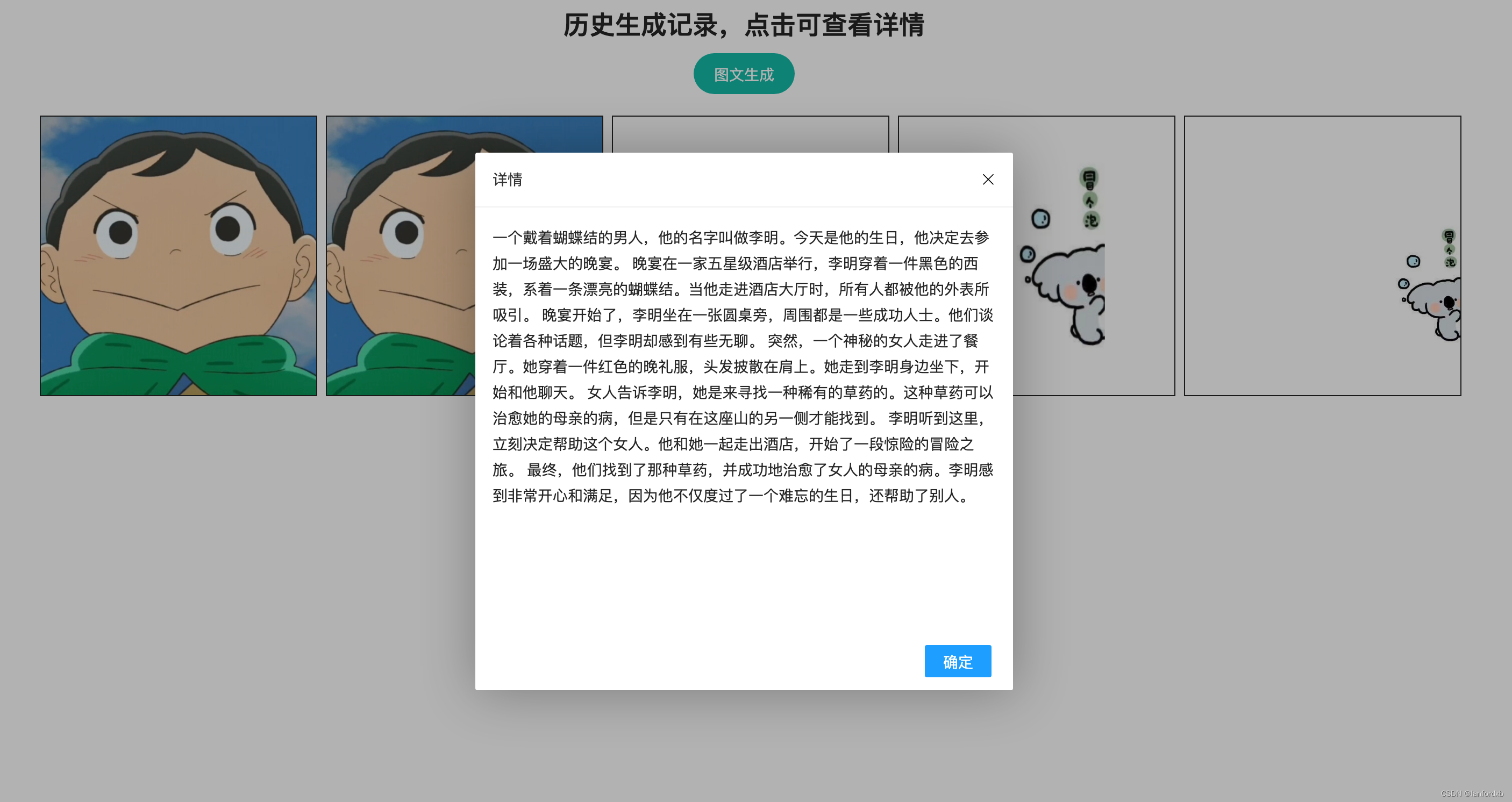
主要功能是上传任意一种图片,通过大模型对图片解析,生成图片的描述,然后在使用LLM模型生成故事或者诗词。
主要技术:
Django
langchain
pytorch
Salesforce/blip-image-captioning-large
LLM
支持多种LLM的扩展,目前支持chatgpt、讯飞
更多详情描述参考github
github地址: pangxiaobin/ImageToTextProject


#python[话题]# #大模型应用[话题]# #开源项目[话题]# #Github[话题]# #LLM[话题]#















 1886
1886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









