










本文正在参与 “拥用源 – Apache DolphinScheduler有奖征稿活动”
海豚调度dolphinscheduler目前是 Apache 顶级项目,作为国内优秀的开源项目,它的架构设计理念会有很多值得我们学习和借鉴。
海豚调度dolphinscheduler是分布式易扩展的可视化DAG工作流任务调度系统
本文会包含如下内容:
- 海豚调度任务执行过程中master与worker的交互过程
- 如何处理过程中的异常
本篇文章适合人群:架构师、技术专家以及对任务调度非常感兴趣的高级工程师
本文以海豚1.3.5的源代码进行分析的。
1. master与worker的消息处理器
DolphinScheduler的master与worker是不同的JVM进程,正常情况下部署在不同的服务器中,master与worker是基于netty实现RPC交互的,共用到7个消息处理器
处理器在WorkerServer和MasterServer启动时,注册到NettyRemotingServer的NettyServerHandler中processors集合中
在netty channel的接收到channelRead数据,并转换为Command时,由NettyServerHandler中的processReceived方法,根据commandType交给对应的处理器处理。
| 所属进程名称 | 处理器名称 | 功能描述 |
|---|---|---|
| MasterServer | TaskAckProcessor | 处理TaskExecuteAckCommand消息,将消息添加到TaskResponseService的任务响应队列中 |
| MasterServer | TaskResponseProcessor | 处理TaskExecuteResponseCommand消息,将消息添加到TaskResponseService的任务响应队列中 |
| MasterServer | TaskKillResponseProcessor | 处理TaskKillResponseCommand消息,并在日志中打印消息内容 |
| WorkerServer | TaskExecuteProcessor | 处理TaskExecuteRequestCommand消息,并发送TaskExecuteAckCommand到master,提交任务执行 |
| WorkerServer | DBTaskAckProcessor | 处理DBTaskAckCommand消息,针对执行成功的,从ResponceCache中删除 |
| WorkerServer | DBTaskResponseProcessor | 处理DBTaskResponseCommand消息,针对执行成功的,从ResponceCache中删除 |
| WorkerServer | TaskKillProcessor | 处理TaskKillRequestCommand消息,调用kill -9 pid杀死任务对应的进程,并向master发送TaskKillResponseCommand消息 |
2. master与worker的交互
DolphinScheduler的master与worker是不同的JVM进程,正常情况下部署在不同的服务器中,master与worker是基于netty实现RPC交互的,整个过程都是异步的。
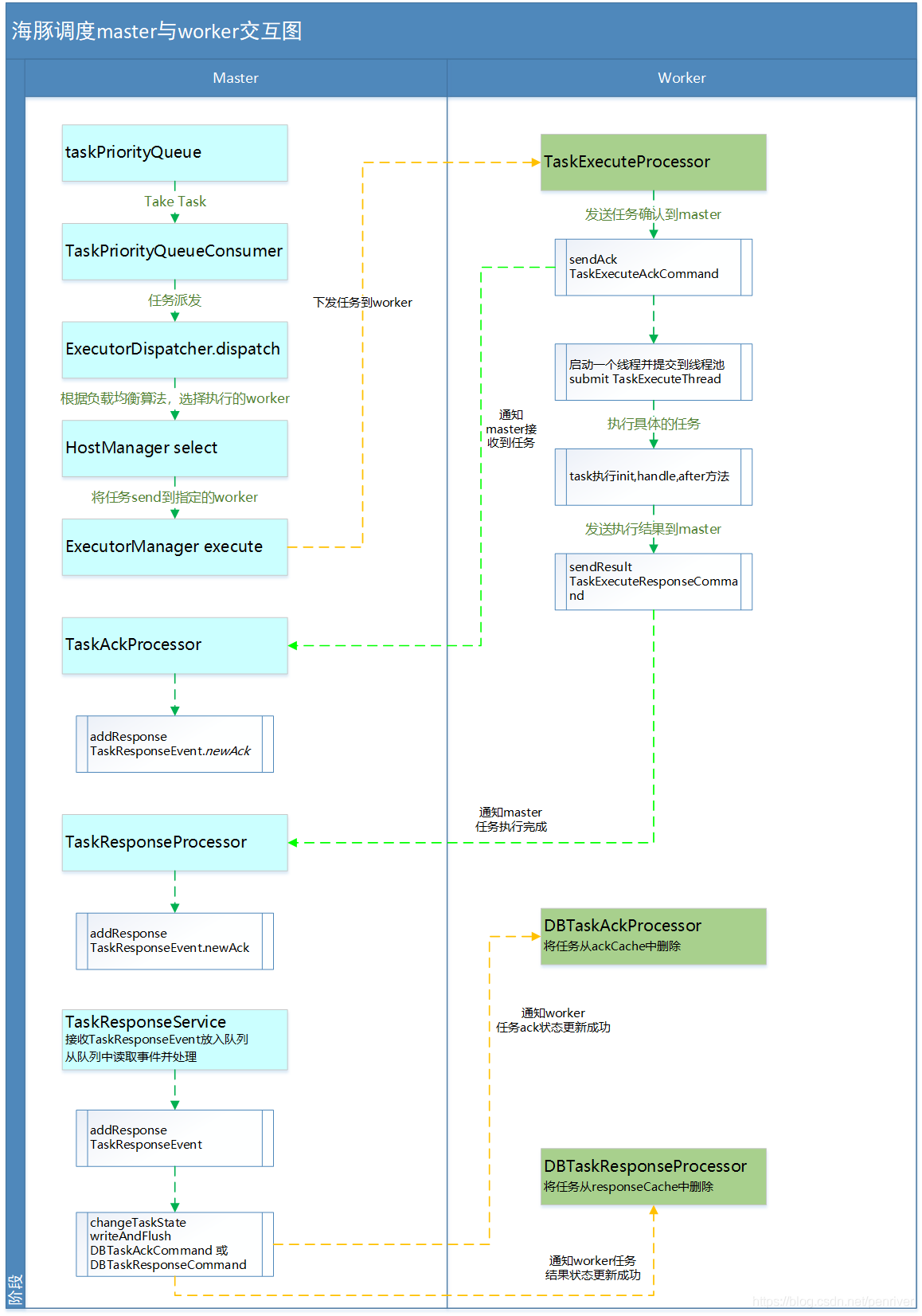
正常的交互流程如下图:
- MasterServer根据流程定义产生的DAG进行任务切分,将每个任务放在MasterBaseTaskExecThread的子类中进行执行。
只有MasterTaskExecThread子类在将Callable提交到线程池,调用call方法时,执行submitWaitComplete方法,
提交就是将任务加到任务优先级队列中taskPriorityQueue - TaskPriorityQueueConsumer线程从taskPriorityQueue队列,根据fetchTaskNum【通过master.dispatch.task.num指定】参数,获取fetchTaskNum个任务信息,然后针对这批任务进行派发。在任务派发前构建ExecutionContext
- ExecutorDispatcher派发任务
- 使用配置文件中指定的负载均衡算法,选择执行任务的worker
- 将任务下发(send)到指定的worker执行。
- TaskExecuteProcessor接收到TaskExecuteRequestCommand后,发送任务确认消息【TaskExecuteAckCommand】到master,并启动一个TaskExecuteThread执行这个任务,任务执行完成后发送执行结果到master
- TaskAckProcessor接收到TaskExecuteAckCommand后,构建一个ACK类型的TaskResponseEvent,放到TaskResponseService的任务响应队列中
- TaskResponseProcessor接收到TaskExecuteResponseCommand后,构建一个ACK类型的TaskResponseEvent,放到TaskResponseService的任务响应队列中
- TaskResponseService线程将接收到的TaskResponseEvent放到任务响应队列中,并从列表中take TaskResponseEvent, 根据Event任务,进行任务状态的更新
如果是ACK EVENT,则更新任务实例的执行开始时间、执行worker、ExecutePath及logPath等信息,更新完成后发送DBTaskAckCommand到worker
如果是RESULT EVENT,则更新任务实例的执行结束时间、ProcessId、AppIds等信息,更新完成后发送DBTaskResponseCommand到worker
10. DBTaskAckProcessor接收到DBTaskAckCommand消息后,如果ExecutionStatus为SUCCESS,则将任务从ackCache中删除
11. DBTaskResponseProcessor接收到DBTaskResponseCommand消息后,如果ExecutionStatus为SUCCESS,则将任务从responeCache中删除
12. 在MasterTaskExecThread的submitWaitComplete方法中,会循环检查任务实例是否完成,在执行完步骤11后,则此任务实例完成,将循环也将退出
13. 针对派发失败的任务,添加到failedDispatchTasks,在这批任务派发完毕后,重新将失败的任务添加到taskPriorityQueue,如果taskPriorityQueue中的任务数小于失败的任务数,则程序休眠1秒
3. 交互异常情况处理
3.1 任务下发到worker失败与重试
- 将任务send到具体的worker时,如果失败,会重试3次,如果三次都失败,则将此worker节点从任务对应的任务组worker列表中删除,并从剩下的worker中选择第一
- 如果失败,则重复步骤1
- 如果任务组worker列表中所有worker都在重试3次后失败,则任务下发失败
- 将失败的任务添加到failedDispatchTasks列表中,因为master是按批处理任务,在这批任务派发完毕后,重新将失败的任务添加到taskPriorityQueue,如果taskPriorityQueue中的任务数小于失败的任务数,则程序休眠1秒
//TaskPriorityQueueConsumer 117行
if (!failedDispatchTasks.isEmpty()) {
for (String dispatchFailedTask : failedDispatchTasks) {
taskPriorityQueue.put(dispatchFailedTask);
}
// If there are tasks in a cycle that cannot find the worker group,
// sleep for 1 second
if (taskPriorityQueue.size() <= failedDispatchTasks.size()) {
TimeUnit.MILLISECONDS.sleep(Constants.SLEEP_TIME_MILLIS);
}
}
//NettyExecutorManager 109行
Host host = context.getHost();
boolean success = false;
while (!success) {
try {
doExecute(host,command);
success = true;
context.setHost(host);
} catch (ExecuteException ex) {
logger.error(String.format("execute command : %s error", command), ex);
try {
failNodeSet.add(host.getAddress());
Set<String> tmpAllIps = new HashSet<>(allNodes);
Collection<String> remained = CollectionUtils.subtract(tmpAllIps, failNodeSet);
if (remained != null && remained.size() > 0) {
host = Host.of(remained.iterator().next());
logger.error("retry execute command : {} host : {}", command, host);
} else {
throw new ExecuteException("fail after try all nodes");
}
} catch (Throwable t) {
throw new ExecuteException("fail after try all nodes");
}
}
}3.2 任务ack及result上报重试
worker在接收到TaskExecuteRequestCommand命令后,会向master发送任务确认消息;worker在任务执行完成后,也会向master发送任务执行完成消息;在发送消息前,会调用ResponceCache的cache方法将方法缓存。
RetryReportTaskStatusThread线程每隔5分钟,判断responceCache中ackCache和responseCache中是否为空,如果不为空,则将命令TaskExecuteAckCommand或TaskExecuteResponseCommand重新发送到master节点















 2812
2812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











