








1 层次分析法简介
1.1 概念
层次分析法(Analytic Hierarchy Process,AHP):是一种定性和定量相结合的、系统的、层次化的分析方法。
这种方法的特点就是在对复杂决策问题的本质、影响因素及其内在关系等进行深入研究的基础上,利用较少的定量信息使决策的思维过程数学化,从而为多目标、多准则或无结构特性的复杂决策问题提供简便的决策方法。是对难以完全定量的复杂系统做出决策的模型和方法。
1.2 原理
层次分析法的原理:层次分析法根据问题的性质和要达到的总目标,将问题分解为不同的组成因素,并按照因素间的相互关联影响以及隶属关系将因素按不同的层次聚集组合,形成一个多层次的分析结构模型,从而最终使问题归结为最低层(供决策的方案、措施等)相对于最高层(总目标)的相对重要权值的确定或相对优劣次序的排定。
1.3 分析步骤
层次分析法的步骤,运用层次分析法构造系统模型时,大体可以分为以下四个步骤:
- 建立层次结构模型;
在深入分析实际问题的基础上,将有关的各个因素按照不同属性自上而下地分解成若干层次,同一层的诸因素从属于上一层的因素或对上层因素有影响,同时又支配下一层的因素或受到下层因素的作用。最上层为目标层,通常只有1个因素,最下层通常为方案或对象层,中间可以有一个或几个层 次,通常为准则或指标层。当准则过多时(譬如多于9个)应进一步分解出子准则层- 最高层(目标层):决策的目的、要解决的问题;
- 中间层(准则层或指标层):考虑的因素、决策的准则;
- 最低层(方案层):决策时的备选方案;
- 构造判断(成对比较)矩阵;
构造成对比较阵。从层次结构模型的第2层开始,对于从属于(或影响)上一层每个因素的同一层诸因素,用成对比较法和1—9比较尺度构造成对比较阵,直到最下层(见下图) - 层次单排序及其一致性检验;
- 层次总排序及其一致性检验;
计算某一层次所有因素对于最高层(总目标)相对重要性的权值,称为层次总排序。
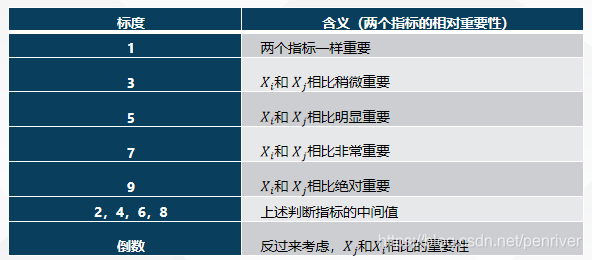
1.4 涉及的定义及公式
1.4.1 定理

1.4.2 定义一致性指标 CI

1.4.3 随机一致性指标 RI
![为了衡量 [公式] 的大小,引入随机一致性指标 [公式] 。方法为随机构造500个成对比较矩阵 [公式] ,则可得一致性指标 [公式]](https://i-blog.csdnimg.cn/blog_migrate/c95be3542bf3842addac0edf44f5fd60.png)
1.4.4 定义一致性比率 CR

1.4.5 一致性检验
利用一致性指标和一致性比率<0.1及随机一致性指标的数值表,对A 进行检验的过程。
2 源代码
2.1 python代码演示计算过程
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
RI_dict = {1: 0, 2: 0, 3: 0.58, 4: 0.90, 5: 1.12, 6: 1.24, 7: 1.32, 8: 1.41, 9: 1.45}
# 矩阵
A_arr = [[1, 1/2, 4, 3, 3],
[2, 1, 7, 5, 5],
[1/4, 1/7, 1, 1/2, 1/3],
[1/3, 1/5, 2, 1, 1],
[1/3, 1/5, 3, 1, 1]]
def main():
# 矩阵
A = np.array(A_arr)
a_sum0 = A.sum(axis=0)
B = A / a_sum0
print('新矩阵:')
print(B)
b_sum = B.sum(axis=1)
print('新矩阵行和: %s' % b_sum)
W = b_sum.sum()
w_arr = []
for w in b_sum:
w_arr.append(w / W)
print('W: %s' % w_arr)
AW = []
for a in A:
aa = a * w_arr
AW.append(aa.sum())
print('AW: %s' % AW)
result = np.array(AW) / np.array(w_arr)
print('AW/W: %s' % result)
row = result.shape[0]
Max = result.sum() / row
print('λMax: %s' % Max)
CI = (Max - row) / (row - 1)
print('CI: %s' % CI)
CR = CI / RI_dict[row]
print('CR: %s' % CR)
if __name__ == '__main__':
main()
2.2 层次分析python封装源码
import numpy as np
def get_tezheng(array):
'''
get the max eigenvalue and eigenvector
:param array: judgement matrix
:return: max eigenvalue and the corresponding eigenvector
'''
# 获取最大特征值和对应的特征向量
te_val, te_vector = np.linalg.eig(array)
list1 = list(te_val)
max_val = np.max(list1)
index = list1.index(max_val)
max_vector = te_vector[:, index]
return max_val, max_vector
def RImatrix(n):
'''
get RI value according the the order
:param n: matrix order
:return: Random consistency index RI of a n order matrix
'''
n1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]
n2 = [0, 0, 0.52, 0.89, 1.12, 1.26, 1.36, 1.41, 1.46, 1.49, 1.52, 1.54, 1.56, 1.58, 1.59, 1.60]
d = dict(zip(n1, n2))
return d[n]
def consitstence(max_val, RI, n):
'''
use the CR indicator to test the consistency of a matrix.
:param max_val: eigenvalue
:param RI: Random consistency index
:param n: matrix order
:return: true or false, denotes whether it meat the validation of consistency
'''
CI = (max_val - n) / (n - 1)
if RI == 0:
return True
else:
CR = CI / RI
if CR < 0.10:
return True
else:
return False
def minMax(array):
result = []
for x in array:
x = float(x - np.min(array)) / (np.max(array) - np.min(array))
result.append(x)
return np.array(result)
def normalize_vector(max_vector):
'''
normalize the vector, the sum of elements is 1.0
:param max_vector: a eigenvector
:return: normalized eigenvector
'''
vector = []
for i in max_vector:
vector.append(i.real)
vector_after_normalization = []
sum0 = np.sum(vector)
for i in range(len(vector)):
vector_after_normalization.append(vector[i] / sum0)
vector_after_normalization = np.array(vector_after_normalization)
return vector_after_normalization
def get_weight(matrix_array,n):
'''
get weight vector according to personal score.
:param score: a list, the item is the score range 1 to 10 means the importance of each sub-indicator.
:return: a list, the item is the weight range 0.0 to 1.0.
'''
max_val, max_vector = get_tezheng(matrix_array)
RI = RImatrix(n)
if consitstence(max_val, RI, n) == True:
feature_weight = normalize_vector(max_vector)
return feature_weight
else:
return [1 / n] * n
def get_judgement_matrix(scores):
'''
get judgement matrix according to personal score.
:param scores: a list, the item is the score range 1 to 10 means the importance of each sub-indicator.
:return: judgement matrix, item range 1 to 9.
- more: in judgement matrix:
1 means two sub-indicators are the same important.
3 means the first sub-indicator is a little important than another one.
5 means the first sub-indicator is apparently important than another one.
7 means the first sub-indicator is strongly significant than another one.
9 means the first sub-indicator is extremely significant than another one.
and 2, 4, 6, 8 are in the middle degree.
'''
# 评分1——10
length = len(scores)
array = np.zeros((length, length))
for i in range(0, length):
for j in range(0, length):
point1 = scores[i]
point2 = scores[j]
deta = point1 - point2
if deta < 0:
continue
elif deta == 0 or deta == 1:
array[i][j] = 1
array[j][i] = 1
else:
array[i][j] = deta
array[j][i] = 1 / deta
return array
A_arr = [[1, 2, 1.0 / 3, 3],
[1.0 / 2, 1, 1.0 / 3, 2],
[3, 3, 1, 4],
[1.0 / 3, 1.0 / 2, 1.0 / 4, 1]]
get_weight(A_arr,4)
参考
层次分析法(AHP)
https://github.com/iLiuChang/AHP
层次分析法
Python实现AHP(层次分析法)


















 5838
5838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











