







在此之间,请先了解:强化学习专业名词解释
图片来源:【王树森】深度强化学习
deep Q-network(DQN):神经网络近似最佳Qπ函数(Q*),根据Q*得到当前最好的动作。
用Q(s,a;w)近似Q*(s,a)。w是参数。
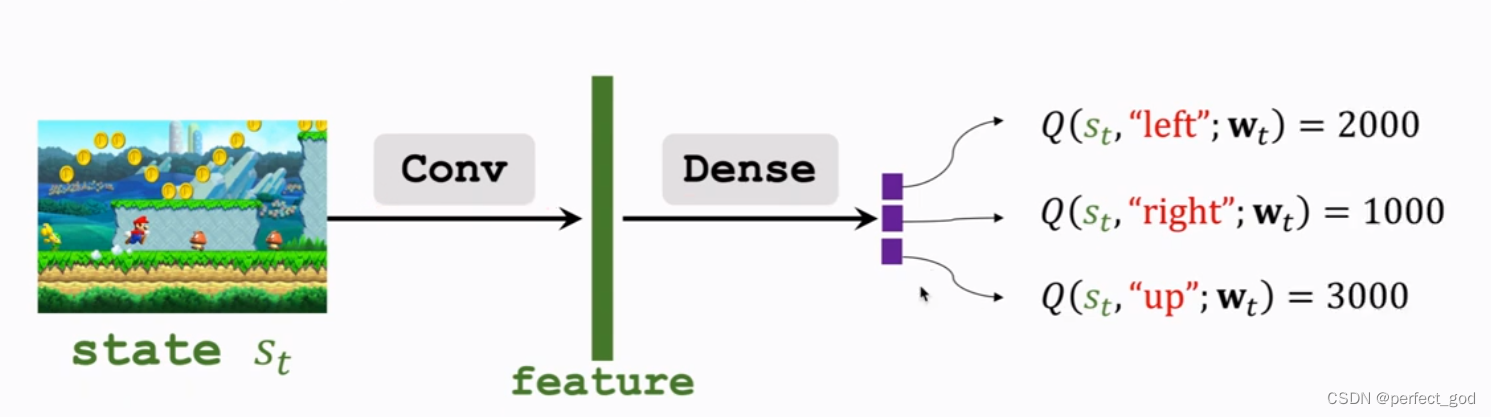
conv为卷积层,得到feature(特征),再用dense(全连接)得到每个动作对应的Q对应的分数,选择分数最高的。
训练DQN方法:
最常用的是TD算法(temporal difference learning):

模型预测从nyc到atlanta要1000分钟,实际860分钟。
因此有误差Loss ,对误差求w偏导,得到迭代式wt+1.
该example中需要完成完整的一次旅程才能更新参数,如何中途就可以呢?
eg:在前往Atlanta途中在dc位置汽车抛锚,如何不去了,回家了,就可以用nyc到dc的时间改善模型。因此假设nyc到dc花300分钟,模型预测还要600分钟,拿着九百分钟就是新的时间。
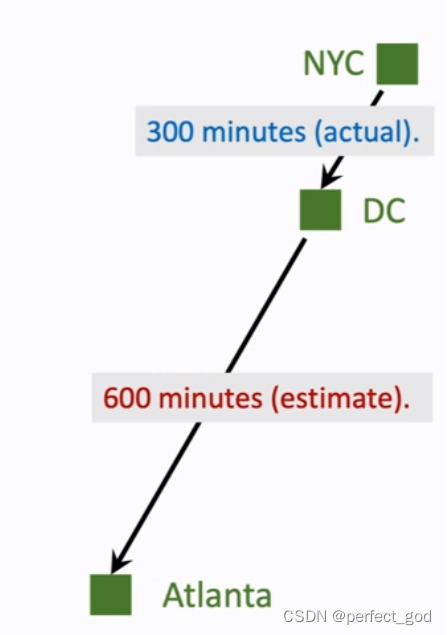

因此同理,用来训练DQN就是不需要打完游戏也可以训练参数。
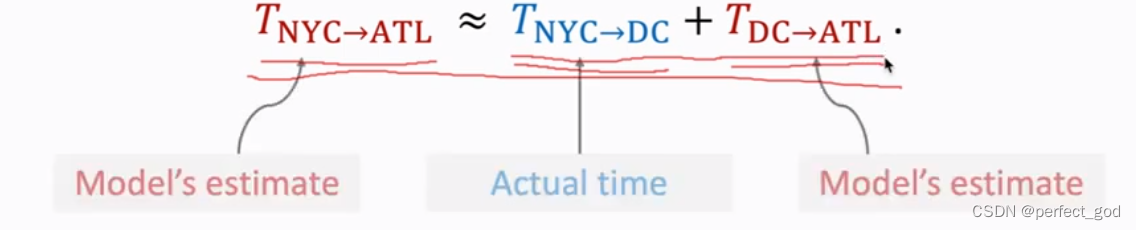
深度强化学习中,

Q(st,at;w)表示一开始对整个行程的预计时间。rt表示nyc到dc的实际时间。
Q(st+1,at+1;w)表示在dc到Atlanta的预计时间。未来的奖励不是那么重要,所以有y。
对该式的推导:
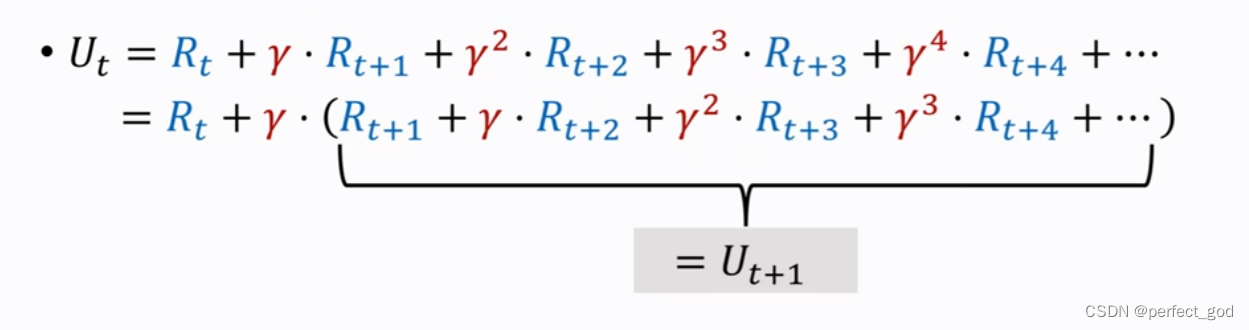
所以得到:

还知道Q是Ut的期望,所以有:

所以左边的可以认为是预测,右边的认为是实际。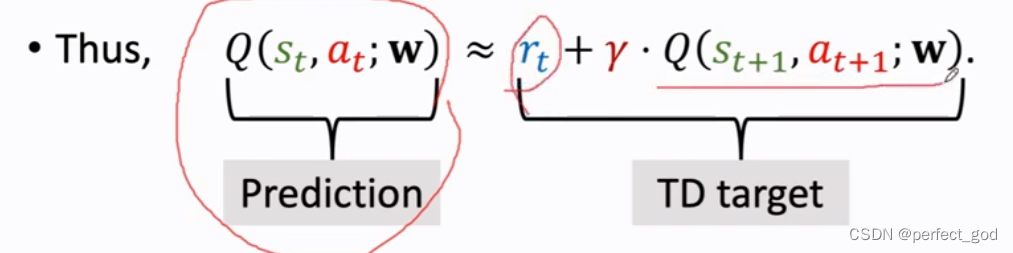
所以t时刻实际值为:
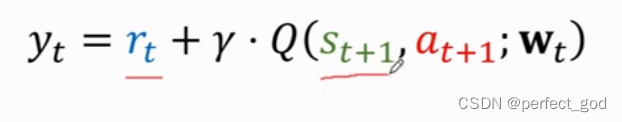
at+1由Qπ决定,选择能让Qπ最大的动作,也就是Q*。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









