







在此之前,请先了解:
图片来源:【王树森】深度强化学习
Actor-Critic Methods:
actor是策略网络,用来控制agent运动。
critic是价值网络,给动作打分,可认为是裁判。
本次为价值学习和策略学习的结合。

用两个神经网络分别近似π函数和Qπ函数,然后用Actor-Critic Methods同时学习这两个神经网络。

设置两个近似函数:


得到近似函数:

构建策略网络:

输入为状态s,conv:卷积层,dense:一个或多个全连接层,softmax:激活函数
构建价值网络:

输入为a和s,s用conv,a用dense得到各自feature,然后拼接起来,再用全连接层得到一个实数,这就是在s的情况下,做出动作a的分数,可以判断在s的情况下,做出动作a的好坏。
两个网络可以共享或独自各自的卷积层。
Actor-Critic Methods可以同时让运动员做更高分数的动作,以及令裁判打分越来越精准。
训练方法:

策略网络训练π函数,θ为策略网络的参数。价值网络训练q函数,w为价值网络的参数。运动员靠裁判打的分数来更新自己的动作,也就是π通过q的打分来改进自己的动作,而q训练是为了让自己的打分更加接近上帝打的分,也就是更接近实际的奖励。
训练步骤:

第四步为用TD算法更新w,第五步policy gradient算法更新θ。
算法介绍分别在上面的链接 价值学习(TD)和策略学习(policy gradient) 。
这两幅图就是对算法的图解,其实就是两个算法的不断使用,思路和算法上面都写过了。

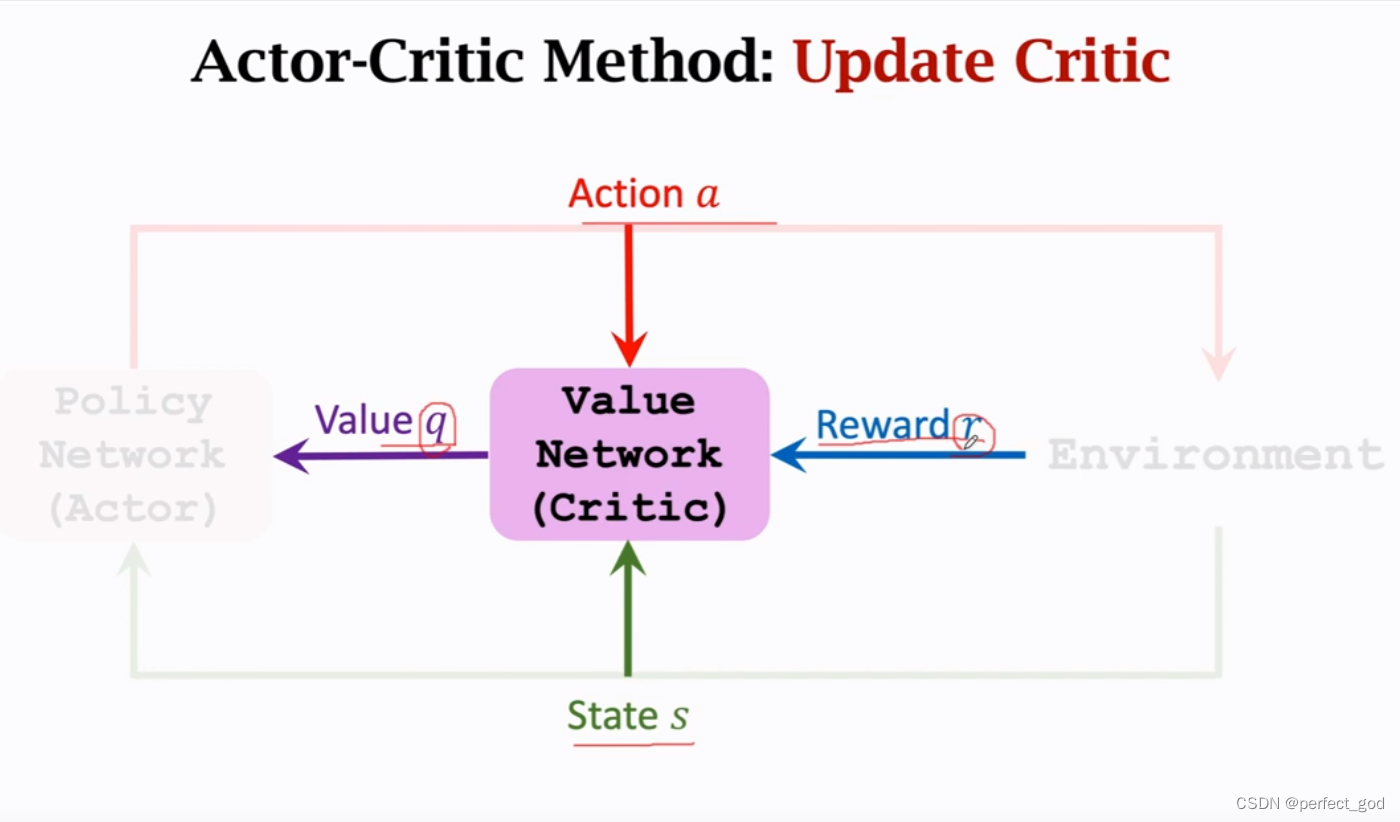
总结:

在第九步中qt用第五步的公式代替效果更好, 因为可以降低方差,收敛更快。















 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









