







本文将简单介绍机器学习的历史和基本概念。我们会看看第一个用算法描述的神经网络和适用于自适应线性神经元的梯度下降算法,这些知识不仅介绍了机器学习原理,还是后续文章中现代多层神经网络的基础。
如果你想看一下代码运行的实际效果,可到https://github.com/rasbt/pattern_classification查看IPython notebook版本。
前言
在当前技术环境下,机器学习是最热门最令人振奋的领域之一。多亏了机器学习,我们享用了稳定的垃圾邮件过滤器、便利的文本及语音识别、可靠的网络搜索引擎和高明的棋手,而且安全高效的自动驾驶汽车有望很快就会出现。
无可置疑,机器学习已经成为一个热门领域,但它有时候容易一叶障目(根据决策树得到随机森林)。所以,我认为值得在研究不同的机器学习算法时,除讨论其原理外,还要一步一步地实现这些算法,以此对其运行原理一探究竟。
若要概括说明机器学习是什么:“机器学习是研究让计算机无需显式编程即可具有学习能力的学科”(Arthur Samuel,1959)。机器学习以统计学,概率论,组合学和优化理论为基础,开发并利用算法来识别数据中的模式,由此来指引决策。
在本系列中,第一篇文章会介绍感知器和适应机(自适应线性神经元),其属于单层神经网络的范畴。感知器不仅是第一个以算法描述的学习算法[1],而且很直观,也容易实现。同时,它(被再次发现)是最先进的机器学习算法——人工神经元网络(也可称作“深入学习”)的绝好切入点。后续我们会知道,adline算法由perceptron算法改进而来,且给我们提供了一个很好的机会去了解机器学习中最流行的优化算法:梯度下降。
人工神经元和McCulloch-Pitts网络
感知器的最初概念可以追溯到Warren McCulloch和Walter Pitts在1943年的研究[2],他们将生物神经元类比成带有二值输出的简单逻辑门。以更直观的方式来看,神经元可被理解为生物大脑中神经网络的子节点。在这里,变量信号抵达树突。输入信号在神经细胞体内聚集,当聚集的信号强度超过一定的阈值,就会产生一个输出信号,并被树突传递下去。

Frank Rosenblatt 感知器
故事继续,在McCulloch和Walter Pitt研究后几年,Frank Rosenblatt第一个提出了感知器学习规则的概念[1]。其主要思想是:定义一个算法去学习权重值w,再将w乘以输入特特征,以此来确定神经元是否收到了刺激。在模式分类中,可以应用这个算法确定样本属于哪一个类。

将感知器算法置于机器学习的更广泛背景中:感知器属于监督学习算法类别,更具体地说是单层二值分类器。简而言之,分类器的任务就是基于一组输入变量,预测某个数据点在两个可能类别中的归属。本文不会过多的地讨论预测建模和分类的概念,但如果你想要更多的背景信息,请参阅我的前一篇文章”Introduction to supervised learning“。
单位阶跃函数
在我们深入研究用于学习人工神经元权值的算法之前,让我们来看一个简短的基本符号。在下面几节中,我们将二值分类中的“正类”和“负类”,分别表示为“1”和“-1”。然后,定义一个激活函数g(z) ,其输入为输入值x和权重w的线性组合(

其中

w是特征向量, x是训练数据集中的一个m维样本:


为了简化符号,将θ引入方程左侧并定义

得到

和

感知器学习规则
这可能看起来是一种极端简化的方法,但“阈值”感知器背后的思路是模拟大脑中单个神经元的工作方式::激活与否。总结前一节的要点:感知器接收多个输入信号,如果输入信号的和超过某个阈值则返回一个信号,否则就什么也不输出。让这些成为“机器学习”算法地是Frank Rosenblatt关于感知器学习规则的概念:感知器算法首先学习输入信号权值,然后得出线性决策边界,进而能够区分两个线性可分的类1和-1。

Rosenblatt最初的感知器规则相当简单,可总结为下面两步:
-
将权值初始化为0或小随机数。
-
对每一个训练样本
:
1. 计算输出值。
2. 更新权值。
输出值就是根据我们早先定义的阶跃函数预测的类标签(output =g(z)),并且,权值的更新可以更正式地写成

在每个增量中,权值的更新值可由如下学习规则得到:

其中 η表示学习速率(0.0和1.0间的常数),“target”表示真实标签,“output”表示预测标签。
需要注意的是,权值向量内的所有权值同步更新。具体来说,对于一个2维数据集,以如下方式描述更新:



在我们用Python实现感知器规则之前,让我们简单设想一下这种学习规则会多么简单。在感知器正确预测类标签的两个场景中,权值保持不变:


但是,若预测出错,权值会被分别“推向”正或负的目标类方向:


需要注意的是,只有当两个类线性可分才能保证感知器收敛。如果这两个类线性不可分。未避免死循环,我们可以设置一个训练集的最大训练次数,或者是设置一个可接受误分类个数的阈值。
用Python实现感知器规则
在本节中,我们将用Python实现简单的感知器学习规则以分类鸢尾花数据集。请注意,为阐述清晰,我省略了一些“安全检查”,若需要更“稳健”的版本,请参阅Github中的代码。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
import
numpy
as
np
class
Perceptron
(
object
)
:
def
__init__
(
self
,
eta
=
0.01
,
epochs
=
50
)
:
self
.
eta
=
eta
self
.
epochs
=
epochs
def
train
(
self
,
X
,
y
)
:
self
.
w_
=
np
.
zeros
(
1
+
X
.
shape
[
1
]
)
self
.
errors_
=
[
]
for
_
in
range
(
self
.
epochs
)
:
errors
=
0
for
xi
,
target
in
zip
(
X
,
y
)
:
update
=
self
.
eta
*
(
target
-
self
.
predict
(
xi
)
)
self
.
w_
[
1
:
]
+=
update
*
xi
self
.
w_
[
0
]
+=
update
errors
+=
int
(
update
!=
0.0
)
self
.
errors_
.
append
(
errors
)
return
self
def
net_input
(
self
,
X
)
:
return
np
.
dot
(
X
,
self
.
w_
[
1
:
]
)
+
self
.
w_
[
0
]
def
predict
(
self
,
X
)
:
return
np
.
where
(
self
.
net_input
(
X
)
>=
0.0
,
1
,
-
1
)
|
对于下面的示例,我们将从UCI Machine Learning Repository载入鸢尾花数据集,并只关注Setosa 和Versicolor两种花。此外,为了可视化,我们将只使用两种特性:萼片长度(sepal length )和花片长度(petal length)。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
import
pandas
as
pd
df
=
pd
.
read_csv
(
'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
,
header
=
None
)
# setosa and versicolor
y
=
df
.
iloc
[
0
:
100
,
4
]
.
values
y
=
np
.
where
(
y
==
'Iris-setosa'
,
-
1
,
1
)
# sepal length and petal length
X
=
df
.
iloc
[
0
:
100
,
[
0
,
2
]
]
.
values
%
matplotlib
inline
import
matplotlib
.
pyplot
as
plt
from
mlxtend
.
evaluate
import
plot_decision_regions
ppn
=
Perceptron
(
epochs
=
10
,
eta
=
0.1
)
ppn
.
train
(
X
,
y
)
print
(
'Weights: %s'
%
ppn
.
w_
)
plot_decision_regions
(
X
,
y
,
clf
=
ppn
)
plt
.
title
(
'Perceptron'
)
plt
.
xlabel
(
'sepal length [cm]'
)
plt
.
ylabel
(
'petal length [cm]'
)
plt
.
show
(
)
plt
.
plot
(
range
(
1
,
len
(
ppn
.
errors_
)
+
1
)
,
ppn
.
errors_
,
marker
=
'o'
)
plt
.
xlabel
(
'Iterations'
)
plt
.
ylabel
(
'Missclassifications'
)
plt
.
show
(
)
Weights
:
[
-
0.4
-
0.68
1.82
]
|


由图可知,第6次迭代后,感知器收敛并完美区分出了这两种花。
感知器存在的问题
尽管感知器完美地分辨出两种鸢尾花类,但收敛是感知器的最大问题之一。 Frank Rosenblatt在数学上证明了当两个类可由线性超平面分离时,感知器学习规则收敛,但当类无法由线性分类器完美分离时,问题就出现了。为了说明这个问题,我们将使用鸢尾花数据集中两个不同的类和特性。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# versicolor and virginica
y2
=
df
.
iloc
[
50
:
150
,
4
]
.
values
y2
=
np
.
where
(
y2
==
'Iris-virginica'
,
-
1
,
1
)
# sepal width and petal width
X2
=
df
.
iloc
[
50
:
150
,
[
1
,
3
]
]
.
values
ppn
=
Perceptron
(
epochs
=
25
,
eta
=
0.01
)
ppn
.
train
(
X2
,
y2
)
plot_decision_regions
(
X2
,
y2
,
clf
=
ppn
)
plt
.
show
(
)
plt
.
plot
(
range
(
1
,
len
(
ppn
.
errors_
)
+
1
)
,
ppn
.
errors_
,
marker
=
'o'
)
plt
.
xlabel
(
'Iterations'
)
plt
.
ylabel
(
'Missclassifications'
)
plt
.
show
(
)
|


|
1
|
print
(
'Total number of misclassifications: %d of 100'
%
(
y2
!=
ppn
.
predict
(
X2
)
)
.
sum
(
)
)
|
|
1
|
Total
number
of
misclassifications
:
43
of
100
|
尽管在较低的学习率情形下,因为一个或多个样本在每一次迭代总是无法被分类造成学习规则不停更新权值,最终,感知器还是无法找到一个好的决策边界。
在这种条件下,感知器算法的另一个缺陷是,一旦所有样本均被正确分类,它就会停止更新权值,这看起来有些矛盾。直觉告诉我们,具有大间隔的决策面(如下图中虚线所示)比感知器的决策面具有更好的分类误差。但是诸如“Support Vector Machines”之类的大间隔分类器不在本次讨论范围。

自适应线性神经元和Delta定律
诚然,感知器被发现时很受欢迎,但是仅仅几年后,Bernard Widrow和他的博士生Tedd Hoff就提出了自适应线性神经元(学习机)的概念。
不同于感知器规则,学习机的delta规则(也被称作学习机的“Widrow-Hoff规则”)基于线性激活函数而不是单位阶跃函数更新权值;在这里,这个线性激活函数g(z)仅作为恒等函数

梯度下降
作为一个连续函数,线性激活函数相对于单位阶跃函数最大的优点之一就是可微。这个特性使得我们可以定义一个最小化代价函数J(w)来更新权值。应用到线性激活函数中,我们可以将平方误差的和定义为其代价函数 J(w)(SSE),那么问题就等同于一般的最小二乘线性回归求最小代价函数。

(分数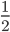
为了最小化SSE代价函数,我们将使用梯度下降算法,这是一种简单有效的优化算法,经常被用来寻找线性系统的局部最小值。
在讲解最有趣的部分前(微积分),让我们先考虑一个仅有单一权值的凸代价函数。如下图所示,我们可将梯度下降背后的原理描述成“下山”,直到到达局部或全局最小值。每一步我们都向梯度相反方向迈出一步,并且步长由学习率以及梯度的斜率共同决定。

现在,按照承诺,我们开始有趣的部分——推导学习机学习规则。如上文所述,每一次更新都由向梯度反向的那一步确定,所以,我们需要沿权值向量方向对代价函数的每一个权值求偏导数:
。
对SSE代价函数内的特定权值求偏导可由如下所示方法:

(t = target, o = output)
若将结果带入到学习规则内,可得:
 ,
,
最终,我们可以像感知器规则一样,让权值同步更新:
 。
。
虽然上述学习规则和感知器规则形式上相同,我们仍需注意两点主要不同:
在这里,输出量“o”是一个实数,并不是感知器学习规则中的类标签。
权值的更新是通过计算数据集中所有的样本(而不是随着每个样本的增加而更新),这也是此方法又被称作“批量”梯度下降。
实现梯度下降规则
现在,是时候用Python实现梯度下降规则了。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
import
numpy
as
np
class
AdalineGD
(
object
)
:
def
__init__
(
self
,
eta
=
0.01
,
epochs
=
50
)
:
self
.
eta
=
eta
self
.
epochs
=
epochs
def
train
(
self
,
X
,
y
)
:
self
.
w_
=
np
.
zeros
(
1
+
X
.
shape
[
1
]
)
self
.
cost_
=
[
]
for
i
in
range
(
self
.
epochs
)
:
output
=
self
.
net_input
(
X
)
errors
=
(
y
-
output
)
self
.
w_
[
1
:
]
+=
self
.
eta
*
X
.
T
.
dot
(
errors
)
self
.
w_
[
0
]
+=
self
.
eta
*
errors
.
sum
(
)
cost
=
(
errors
*
*
2
)
.
sum
(
)
/
2.0
self
.
cost_
.
append
(
cost
)
return
self
def
net_input
(
self
,
X
)
:
return
np
.
dot
(
X
,
self
.
w_
[
1
:
]
)
+
self
.
w_
[
0
]
def
activation
(
self
,
X
)
:
return
self
.
net_input
(
X
)
def
predict
(
self
,
X
)
:
return
np
.
where
(
self
.
activation
(
X
)
>=
0.0
,
1
,
-
1
)
|
实际上,想找到一个适合的学习速率实现理想收敛通常需要一些实验,所以,我们从画出两个不同学习速率的代价函数开始。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
ada
=
AdalineGD
(
epochs
=
10
,
eta
=
0.01
)
.
train
(
X
,
y
)
plt
.
plot
(
range
(
1
,
len
(
ada
.
cost_
)
+
1
)
,
np
.
log10
(
ada
.
cost_
)
,
marker
=
'o'
)
plt
.
xlabel
(
'Iterations'
)
plt
.
ylabel
(
'log(Sum-squared-error)'
)
plt
.
title
(
'Adaline - Learning rate 0.01'
)
plt
.
show
(
)
ada
=
AdalineGD
(
epochs
=
10
,
eta
=
0.0001
)
.
train
(
X
,
y
)
plt
.
plot
(
range
(
1
,
len
(
ada
.
cost_
)
+
1
)
,
ada
.
cost_
,
marker
=
'o'
)
plt
.
xlabel
(
'Iterations'
)
plt
.
ylabel
(
'Sum-squared-error'
)
plt
.
title
(
'Adaline - Learning rate 0.0001'
)
plt
.
show
(
)
|


上述两图通过描绘两个最普通的梯度下降问题,很好地强调了画出学习曲线的重要性。
1. 若学习速率过大,梯度下降将超过最小值并偏离。 2. 若学习速率过小,算法将需要过多的迭代次数才能收敛,并会更容易陷入局部最小中。

梯度下降也可解释为什么特征缩放对很多机器学习算法地重要性。如果特征在同一个数量级上,便可以更容易找到合适的学习速率、实现更快的收敛和防止权值过小(数值稳定)。
特征缩放的一般方法是标准化

其中,和
分别表示特征
的样本平均值和标准差。标准化后,特征具有单位方差并以均值为零中心分布。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# standardize features
X_std
=
np
.
copy
(
X
)
X_std
[
:
,
0
]
=
(
X
[
:
,
0
]
-
X
[
:
,
0
]
.
mean
(
)
)
/
X
[
:
,
0
]
.
std
(
)
X_std
[
:
,
1
]
=
(
X
[
:
,
1
]
-
X
[
:
,
1
]
.
mean
(
)
)
/
X
[
:
,
1
]
.
std
(
)
%
matplotlib
inline
import
matplotlib
.
pyplot
as
plt
from
mlxtend
.
evaluate
import
plot_decision_regions
ada
=
AdalineGD
(
epochs
=
15
,
eta
=
0.01
)
ada
.
train
(
X_std
,
y
)
plot_decision_regions
(
X_std
,
y
,
clf
=
ada
)
plt
.
title
(
'Adaline - Gradient Descent'
)
plt
.
xlabel
(
'sepal length [standardized]'
)
plt
.
ylabel
(
'petal length [standardized]'
)
plt
.
show
(
)
plt
.
plot
(
range
(
1
,
len
(
ada
.
cost_
)
+
1
)
,
ada
.
cost_
,
marker
=
'o'
)
plt
.
xlabel
(
'Iterations'
)
plt
.
ylabel
(
'Sum-squared-error'
)
plt
.
show
(
)
|



用梯度下降算法实现在线学习
上一节主要讨论“批量”梯度下降学习。“批量”更新即代价函数的最小化需要根据全部的训练数据集。若我们回想感知器规则,其权值需要随着每个单独的训练样本的更新而更新。这种方法也被称作“在线”学习,而实际上,这也是Bernard Widrow等人[3]第一次描述学习机的方式。
因为增量更新权值的过程近似于最小化代价函数,故其也被称作“随机”梯度下降。尽管由于本身的“随机”特性和“近似”方向(梯度),随机梯度下降方法貌似不如梯度下降,但它在实际应用中的确有一定的优势。因为在每个训练样本后更新得以立即应用,随机梯度下降收敛速度通常远远高于梯度下降;随机梯度下降更具计算效率,特别是针对大数据集。在线学习的另一个优势在于,当有新训练数据到来时,分类器能够即时更新,例如:web应用程序中,若存储不足,旧的训练数据即会被舍弃。在大规模机器学习系统中,使用所谓的“小批量(mini-batches)”方法作妥协也很常见,其具有比随机梯度下降更平稳的收敛过程。
为使内容完整,我们也将实现随机梯度下降学习机并证明它在线性可分的鸢尾花数据集上收敛。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
import
numpy
as
np
class
AdalineSGD
(
object
)
:
def
__init__
(
self
,
eta
=
0.01
,
epochs
=
50
)
:
self
.
eta
=
eta
self
.
epochs
=
epochs
def
train
(
self
,
X
,
y
,
reinitialize_weights
=
True
)
:
if
reinitialize_weights
:
self
.
w_
=
np
.
zeros
(
1
+
X
.
shape
[
1
]
)
self
.
cost_
=
[
]
for
i
in
range
(
self
.
epochs
)
:
for
xi
,
target
in
zip
(
X
,
y
)
:
output
=
self
.
net_input
(
xi
)
error
=
(
target
-
output
)
self
.
w_
[
1
:
]
+=
self
.
eta
*
xi
.
dot
(
error
)
self
.
w_
[
0
]
+=
self
.
eta
*
error
cost
=
(
(
y
-
self
.
activation
(
X
)
)
*
*
2
)
.
sum
(
)
/
2.0
self
.
cost_
.
append
(
cost
)
return
self
def
net_input
(
self
,
X
)
:
return
np
.
dot
(
X
,
self
.
w_
[
1
:
]
)
+
self
.
w_
[
0
]
def
activation
(
self
,
X
)
:
return
self
.
net_input
(
X
)
def
predict
(
self
,
X
)
:
return
np
.
where
(
self
.
activation
(
X
)
>=
0.0
,
1
,
-
1
)
ada
=
AdalineSGD
(
epochs
=
15
,
eta
=
0.01
)
ada
.
train
(
X_std
,
y
)
plot_decision_regions
(
X_std
,
y
,
clf
=
ada
)
plt
.
title
(
'Adaline - Gradient Descent'
)
plt
.
xlabel
(
'sepal length [standardized]'
)
plt
.
ylabel
(
'petal length [standardized]'
)
plt
.
show
(
)
plt
.
plot
(
range
(
1
,
len
(
ada
.
cost_
)
+
1
)
,
ada
.
cost_
,
marker
=
'o'
)
plt
.
xlabel
(
'Iterations'
)
plt
.
ylabel
(
'Sum-squared-error'
)
plt
.
show
(
)
|


后续内容
尽管本文涵盖了很多不同的主题,但这仅仅触及人工神经网络的表层。
后续的文章中,我们将会看到:动态调整学习速率的不同方法、多分类中的”One-vs-All”和“One-vs-One”概念、通过正则化引入附加信息来克服过拟合、多层神经网络和非线性问题的处理、人工神经元的不同激活函数以及像逻辑回归和支持向量机这样的相关概念。
















 2616
2616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









