






1 决策树
1.1 构造决策树
上节说到连续数据构造决策树的特征值需要自己寻找,比如二分类的散点图绘制的决策边界可视为一次构造决策树次数,其实决策边界两边可能都包含其他类别的节点,然后可对决策边界两边的趋于继续递归绘制决策边界,以此类推,会形成一个二叉树。最后构造完树后,如果每个叶节点包含的数据点类别只有一类,称这个叶节点是纯的(pure)。预测的话,就用待预测数据点从根节点一直走到叶节点
1.2 控制决策树复杂度
如果将决策树构造的每个叶节点都为纯叶节点,决策树会很复杂,且可能将模型过拟合
防止过拟合策略有两种:预剪枝和后剪枝
预剪枝的方法例如限制树最大深度,限制叶节点最大数目,规定一个节点中数据最小的数量防止继续划分
scikit-learn的决策树在DecisionTreeRegression和DecisionTreeClassifier中实现,scikit-learn中只实现了预剪枝,没实现后剪枝
在乳腺癌数据看下预剪枝效果,训练决策树模型,然后调用score对训练集和测试集预测准度
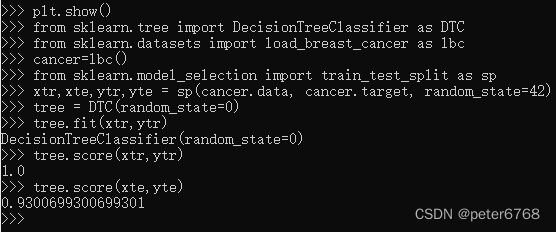
看score得分,因为为纯叶节点,训练集100%,测试集95%,有点过拟合,减少过拟合程度可降低训练集准度并提高测试集准度
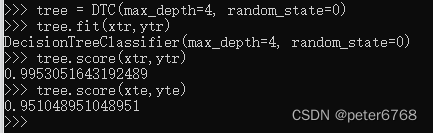
现在限制树最大深度为4,再看下
1.3 分析决策树
1.3.1 可视化
可用sklearn.tree.export_graphviz方法将树可视化


1.4 树的特征重要性
数据有很多特征时,构造树时可能用了某些特征,有些特征影响因素较大,怎么看哪些特征影响大?可用特征重要性查看每个特征的影响程度,值在0-1之间,0表示完全不影响,1表示完全影响,所有特征值的特征重要性之和为1

将特征重要性的可视化看下


当一个特征的特征重要性小,不能说明特征值没啥作用,可能是这个特征没被选中,另一个特征包含了相似的特征而被选中。
当某个特征的特征重要性大时,只能看出影响较大,但不能看出特征是怎样影响结果的


用2000年前ram价格预测2000年后ram价格,选DecisionTreeRegression和LinearRegression模型进行预测,结果如上图。决策树最终叶节点难预测回归,且无法预测未来趋势,但可以方便预测有限状态结果,如分类,但线性模型可预测回归未来状态
1.5 优缺点
优点
预剪枝可以防止过拟合
决策树得到的模型很容易可视化
决策树不受数据放缩影响,决策树不需要特征预处理,比如归一化和标准化,
缺点
即使做了预剪枝和后剪枝也常过拟合,泛化性能较差,因此往往用决策树集成代替单棵决策树
2 决策树集成
集成可以合并多个机器学习算法,已有两种经证明的集成模型对大量数据的分类和回归问题有效,两个集成模型都以决策树为基础,分别是随机森林和梯度提升决策树
2.1 随机森林
概念 随机森林是很多决策树的集合,每棵树和其他树都不太一样
逻辑 每棵树的预测可能相对较好,但存在过拟合风险,如果构造很多树,每棵树预测都很好,但以不同方式过拟合,可以通过取这些树平均值降低过拟合,可减少过拟合也可维持模型预测能力,数学可严格证明
构造树的逻辑 随机选取特征进行构造,可确保每颗树不尽相同
随机森林的树随机化方法 1通过选择用于构造树的数据点 2 通过每次划分测试的特性
构造随机森林方法 1 确定要构造的树数量 2对数据进行自动采样 3从n个样本有放回地随机取n个数据点,这样会导致有的数据点取不到(大概三分之一)
为什么随机森林可确保每棵树的独特性 1每棵树构造采用自动采样,即从样本随机选n个样本,书上说约三分之一数据选不到,保证了样本随机性 2选的样本里假设共有k个特征,训练模型时规定从特征里选max_feature个特征,在每个节点训练时,从max_feature个特征里随机选一个特征的样本子集,在此子集中随机找一个特征寻找最佳划分,保证了树的不同性
对一组两个特征数据集进行随机森林构造
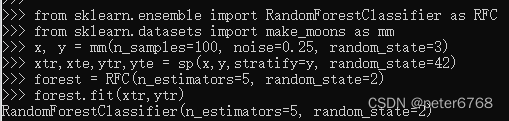


随机森林看着比每一刻树的过拟合程度都要小
没进行任何参数调节情况下,随机森林准度约为97%,比线性模型和单决策树都要好,可以调节max_features或像单决策树那样预剪枝,但默认参数的随机森林就可得到很好的泛化结果
看下随机森林在乳腺癌数据集的准确度,然后看下模型特征重要性,看下训练模型主要用了哪些特征值



对比单决策树和决策森林特征重要性,发现决策森林考虑了更多特征,应该更全面
2.2 调参
需要调n_estimators和max_features,也可以包括预剪枝(如max_depth)
n_estimators 越大越好(决策树个数),因为越多,最后取平均值时对某些特征过拟合降低的就越多,不过耗cpu和内存也更多
max_features 较小时,可降低过拟合,分类问题,默认值是sqrt(n_features),即特征数开平方,回归问题,默认等于n_features,增大max_features或max_leaf_nodes有时也可提升性能
max_depth 决策树深度
2.3 优缺点
优点 随机森林是最广泛的机器学习方法之一,不需要反复调参和过多数据缩放即可获得很好的结果
缺点 随机森林教费时(可通过n_jobs规定使用内核数优化时间),有的决策树可能较深;对稀疏矩阵表现不够好,线性模型可能更合适;随机森林可用于大型数据,但需要更多的时间和内存,如果时间和内存较重要,可以考虑更经济的线性模型。
3 核支持向量机(kernelized SVM)
区别 相比于线性SVM,kernelized SVM可推广复杂模型,是一种扩展
能干啥 对2特征值的非线性关系样本,无法用线性SVM准确获得决策边界,但核支持向量机可以
原理 核支持向量机将决策边界弄成样本特征值的函数,通过将已有特征值处理成新特征值,然后用线性模型拟合(例如二维非线性分类样本点,可以添加一个维度特征值,然后在三维可用线性模型分类)
方法 1多项式核:计算某些特征值n次方 2径向基函数核(radial basic function, RBF),也叫高斯核,有点复杂先不解释了
支持向量 决策边界周围的部分样本点,注意是点,不是线
预测原理 测量新样本点到支持向量点的距离,然后根据支持向量特征重要性算出
看下kernelized SVM长啥样
def test_plot_3d_boundary_RBF(self):
x, y = self.handcraft
svm = SVC(kernel='rbf', C=10, gamma=0.1).fit(x, y)
mglearn.plots.plot_2d_separator(svm, x, eps=.5)
mglearn.discrete_scatter(x[:, 0], x[:, 1], y)
sv = svm.support_vectors_
sv_label = svm.dual_coef_.ravel() > 0
mglearn.discrete_scatter(sv[:, 0], sv[:, 1], sv_label, s=15, markeredgewidth=3)
plot.xlabel('feature 0')
plot.ylabel('feature 1')
plot.show()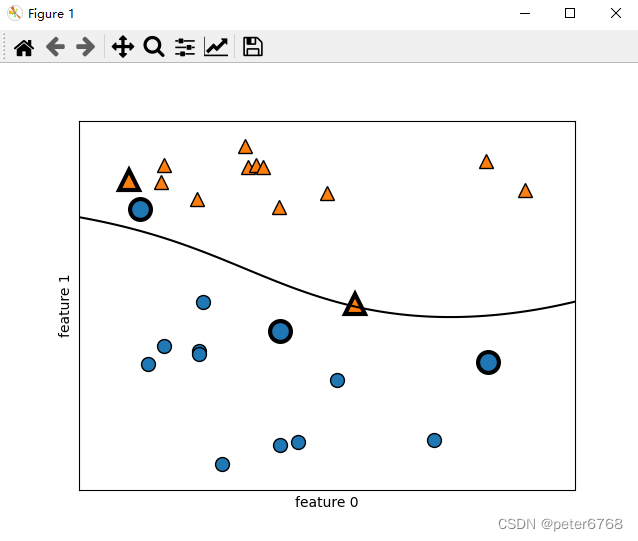
3.1 调参
调节C和gamma,看边界变化
C低,正则化强,容易过拟合,会尽力正确拟合每个点;C高,正则化弱,不会追求每个点正确
新点到支持向量点距离由高斯核给出
![]()
gamma大,高斯核半径小,gamma小,高斯核半径大
gamma大,或C小,都会导致过拟合
def test_plot_2d_boundary_adjust_params(self):
fig, axes = plot.subplots(3, 3, figsize=(15, 10))
for ax, C in zip(axes, [-1, 0, 3]):
for a, gamma in zip(ax, range(-1, 2)):
mglearn.plots.plot_svm(log_C=C, log_gamma=gamma, ax=a)
axes[0, 0].legend(['class 0', 'class 1', 'sv class 0', 'sv class 1'], ncol=4, loc=(.9, 1.2))
plot.show()
看下RBF核在乳腺癌数据的表现
def test_predict_cancer(self):
xtr, xte, ytr, yte = train_test_split(self.cancer.data, self.cancer.target, random_state=0)
svc = SVC(C=1, gamma=1/len(self.cancer.feature_names)).fit(xtr, ytr)
print(f'kernelized SVM train: {svc.score(xtr, ytr)}, test: {svc.score(xte, yte)}')
发现过拟合了,因为数据没放缩。为啥要放缩?因为核支持向量机对参数较敏感,主要是要求所有特征值有相似的变化范围,即当数据集不同特征值范围不一样时,对模型影响较大(如feature 0在1-2之间,feature 1范围在200-2000之间),可通过数据预处理解决该问题
3.2 数据预处理
怎么做 即对每个特征值范围放缩,使所有特征值范围相近,一般可将所有值放缩到0-1之间
放缩后看下乳腺癌数据集上kernelized SVC效果
def test_pre_deal_cancer_data(self):
xtr, xte, ytr, yte = train_test_split(self.cancer.data, self.cancer.target, random_state=42)
min_tr = xtr.min(axis=0)
range_tr = (xtr - min_tr).max(axis=0)
xtr_scale = (xtr - min_tr) / range_tr
xte_scale = (xte - min_tr) / range_tr
svc = SVC().fit(xtr_scale, ytr)
print(f'kernelized SVC after data scale. train: {svc.score(xtr_scale, ytr)}, test: {svc.score(xte_scale, yte)}')

相比于没放缩,进步了很多,但此时还欠拟合,需要调C和gamma提高准确度
3.3 优缺点
4 神经网络(深度学习)
书里只说了一个算法,可用于回归和分类,多层感知机(multilayer perceptron,MLP),MLP有时被称为前馈神经网络,有时也简称为神经网络
4.1 神经网络模型
模型 可视为广义线性模型,执行多层处理后得到结论,公式同线性模型公式,原理可参考下图,第一个是线性模型logisticRegression,第二个是MLP模型(多层感知机模型,multilayer perception, MLP)




MLP和LogisticRegression的区别在于,需要学习更多的系数:input到hidden layer的系数和hidden layer到output的加权权重系数
技巧 对一个hidden layer处理完后,对结果用一个非线性函数(校正非线性函数relu或正切函数tan)对hidden layer的每个h[index]取值,最后进行加权平均,公式如下

需要设置的一个参数是hidden layer中节点个数,也可以添加多个hidden layer
4.2 调参
看下不同激励函数(relu,tanh)和不同隐节点数量下的分类决策边界效果
def test_plot_mlp_boundary(self):
xtr, xte, ytr, yte = train_test_split(*self.moon, random_state=3)
fig, axes = plot.subplots(2, 2, figsize=(10, 10))
func = 'relu'
for node_num, ax in zip([10, 10, 100, 100], axes.ravel()):
mlp = MLP(solver='lbfgs', activation=func, random_state=0, hidden_layer_sizes=[node_num]).fit(xtr, ytr)
mglearn.plots.plot_2d_separator(mlp, xtr, fill=True, alpha=.3, ax=ax)
mglearn.discrete_scatter(xtr[:, 0], xtr[:, 1], ytr, ax=ax)
ax.set_title(f'hidden node num: {node_num}, activate func: {func}')
ax.set_xlabel('feature 0')
ax.set_ylabel('feature 1')
func = 'tanh' if func == 'relu' else 'relu'
plot.tight_layout()
plot.show()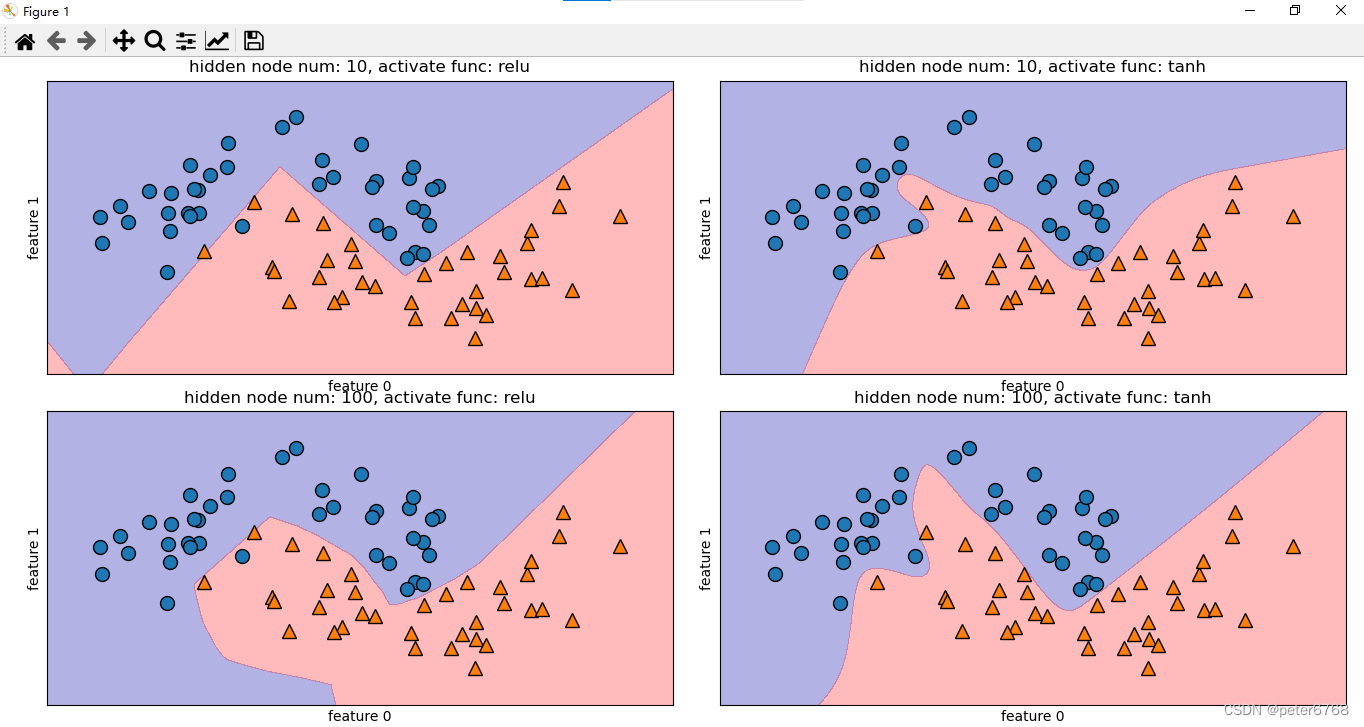
默认情况下,MLP有100个隐节点,可以减少数量,仍可以获得较好的结果
默认非线性函数是relu
控制模型复杂度参数很多,一般有隐层个数,隐层中隐单元数,正则化参数alpha(正则化减少过拟合)等
注意 网络初始化参数不同时,即使参数相同但随机种子不同,也可能得到完全不同的决策边界;但如果神经网络够大,复杂度设置合理,则结果不会相差太多
4.2.1 数据放缩
神经网络也需要对数据进行放缩,对比下放缩前后的效果
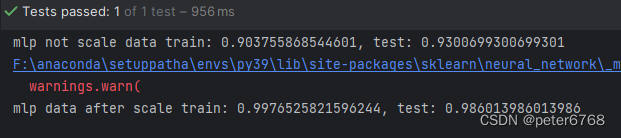
def test_predict_cancer_mlp(self):
# data not scaled
xtr, xte, ytr, yte = train_test_split(self.cancer.data, self.cancer.target, random_state=42)
mlp = MLP(random_state=42).fit(xtr, ytr)
print(f'mlp not scale data train: {mlp.score(xtr, ytr)}, test: {mlp.score(xte, yte)}')
# after scale data
xtr_mean = xtr.mean(axis=0)
xtr_std = xtr.std(axis=0)
xtr_scale = (xtr - xtr_mean) / xtr_std
xte_scale = (xte - xtr_mean) / xtr_std
mlp = MLP(random_state=42).fit(xtr_scale, ytr)
print(f'mlp data after scale train: {mlp.score(xtr_scale, ytr)}, test: {mlp.score(xte_scale, yte)}')放缩后准确度有明显提升,但警告提示超过最大迭代次数,增加即可。增加了仅可提升训练集性能,不提升测试集性能,看下增加迭代次数后的效果
mlp = MLP(random_state=42, max_iter=1000).fit(xtr_scale, ytr)
print(f'mlp scaled data iter 1000 train: {mlp.score(xtr_scale, ytr)}, test: {mlp.score(xte_scale, yte)}')
加点正则看效果,默认好像就是带正则的
mlp = MLP(random_state=42, alpha=1, max_iter = 1000).fit(xtr_scale, ytr)
print(f'mlp scaled 1000 iter alpha 1 train: {mlp.score(xtr_scale, ytr)}, test: {mlp.score(xte_scale, yte)}')
5 分类器的不确定度估计
监督模型.score方法可给出准确度,但没有置信度,sklearn有两个函数(模型的方法)可获取置信度:decision_function, predict_proba,大多数分类器都有至少一个函数,很多分类器两个都有
5.1 决策函数
主要是decision_function这个方法
可以给出一个输入样本对应的函数返回值,有正负号,正号表示正类,负号表示负类,数值大小没啥意义,热图有助于可视化,0表示决策边界
用途 绘制决策边界可以再来一个图绘制decision_function函数执行结果的热图信息量更多
5.2 预测概率
主要是predict_proba这个方法
该方法输出是每个类别的概率,输出比decision_function的输出更容易理解,他的shape始终是(n_samples, 2),2表示正类和反类的概率,加起来等于1,第一个是反类概率,第二个是正类概率,注意顺序,都是第一个反类,第二个正类
5.3 多分类问题不确定度
decision_function和predict_proba同样适用于多分类问题
6 总结
5最好1最差
| 模型 | 耗时 | cpu和内存 | 准确度 | 调参 | 稀疏矩阵 | 大量数据 | 多特征 | 泛化 |
| knn | 3 | 3 | 3 | 4 | 1 | 2 | 2 | |
| ridge&lasso | 4 | 3 | 3 | 4 | 4 | |||
| 线性SVM | ||||||||
| logistic | ||||||||
| 决策树 | 4 | 5 | 1 | |||||
| 决策森林 | 2 | 2 | 4.5 | 2 | ||||
| 梯度分类器 | 2 | 4 | 2 | 2 | ||||
| 核支持向量机 | 2 | 4.5 | 2 | 2 | ||||
| 神经网络 | 2 | 3 | 2 |















 993
993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









