









是在抱歉, 最近工作比较忙(比较懒), 文章好久没更新了. 思索了5分钟, 还是决定好好写.
(文章主要内容是自己通过看源码了解的, 写的不好多多包涵)
背景介绍
LSM算法全称是Log-Structure Merge Tree, 日志结构化合并树.
该算法起源于谷歌发表的 “BigTable”论文, 为了解决写多读少场景(比如消息队列消息落盘)
levelDB是基于LSM算法实现的一个数据库. levelDB提供了更好的写操作吞吐量, 因为它通过消去随机的本地更新操作 , 以文件顺序读写来实现快速写入的.(新增/删除/修改操作都是一条新增记录)
当然, 随机读写慢的另外一个原因跟硬盘有关, 如果线上机器都使用SSD, 随机读写也会很快…(只要你有钱)
(SSD内部维护了一个映射表, 所以搜索数据很快, 但SSD比较贵, 相对容量低,硬盘坏了数据难以恢复)
(普通硬盘HDD随机操作慢(寻道时间/延迟时间) , 顺序读写快 , 便宜, 适合线上大规模部署)
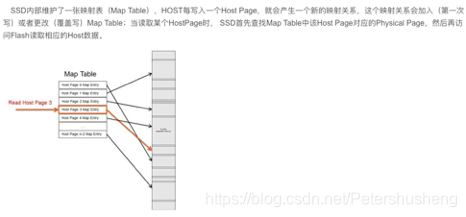

一般线上使用的都是普通硬盘, 好了, 对于写多读少并且数据量比较大的情况, 技术选型时可以考虑levelDB(博主并不是DBA ,没有对比过与mongoDB的区别)
levelDB整体数据流图
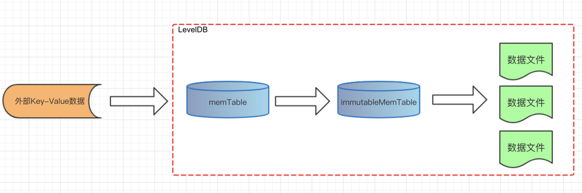
levelDB存储的是非结构化的数据.
数据写入流程如下:
- 业务代码调用api将key-value 数据写入到levelDB中.
- levelDB先使用memTable接收(memTable使用ConcurrentSkipListMap实现(自行百度))
- 当memTable的数据达到一定的阈值时, memTable指针会指向一块新的数据, 然后将immutableMemTable指针指向旧的那块内存. (避免影响客户端写入数据)
- immuTableMemTable指向的内存数据不为空时, 就会触发内存数据写入到文件中.(Sorted Strings Table文件, 简称SSTable文件)
SSTable文件时分层的, 内存数据写入到低level文件, 低层ssTable文件达到一定条件时, 会被压缩到高层level的ssTable文件中.
查询数据时访问流程(记住要考): memTable-> immuTableMemTable -> level文件(低层level0 层文件-> level N层文件)
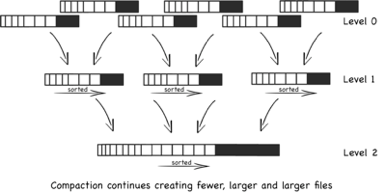
数据写入内存:
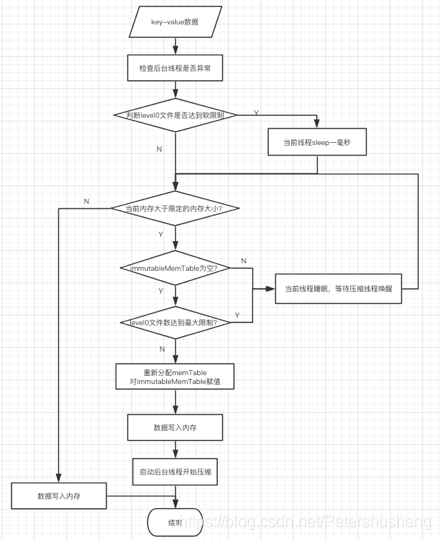
流程图中有几个关键点:
1.判断level0文件是否达到软限制是判断文件数量是否等于8.当达到该文件数量时, 每次数据写入都会sleep 1ms(每次写入只sleep一次)
2.“levelDB文件达到最大限制?” 是判断level0文件数是否达到12 , 如果达到12, 说明文件压缩已经跟不上数据接收了. 这个时候接收外部数据的线程就被sleep了.
内存数据写入文件流程
数据写入文件时并不一定就写到level0层的文件.会有条件判断来决定能写到第几层的ssTable文件.(交叉: 某块数据的最小值和最大值, 跟另一块数据的最小最大值是否有交集, 有交集则称为交叉)
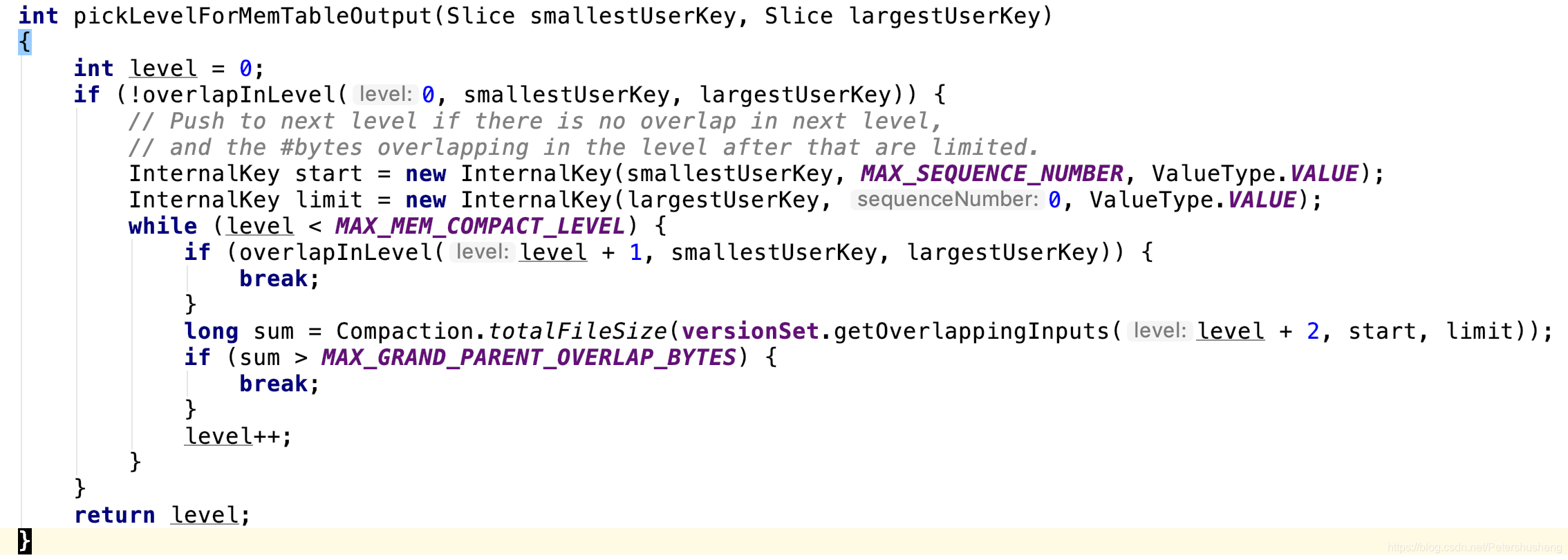
流程图和代码都是用来描述内存数据应该写入到哪个level的.(刚写了一堆废话, 最终还是决定删掉一坨文字, 画个流程图吧…)
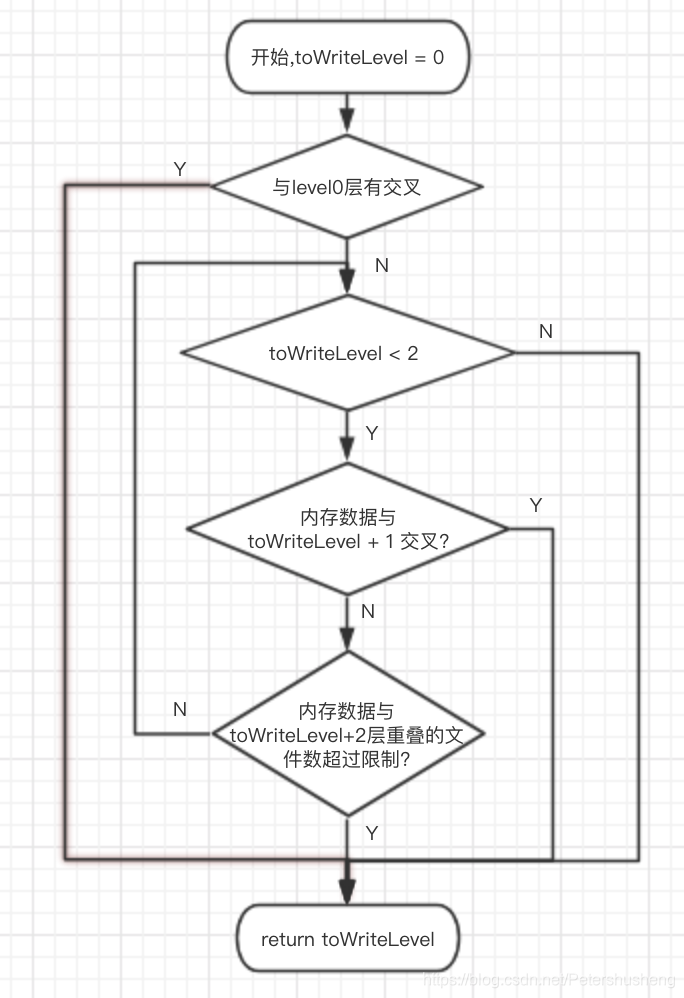
按照上图挑选出将要写入的level后 , 将数据写入到对应的level文件中, 并将immutableMemTable引用置空.
ssTable文件满足压缩的条件
1.针对level0层, 总文件数/ 4 >=1
2.针对其他level层, 每层总size/每层的限定总size >= 1 则满足压缩条件
3.某个文件被查询一定次数后, 则满足压缩条件(每个ssTable文件在创建时会设定查询次数, 当达到查询次数时满足压缩条件)
满足压缩条件并不一定就会被压缩, 还要比较紧急程度.最紧急的层级会被先压缩. (下面代码的score最大则最紧急)
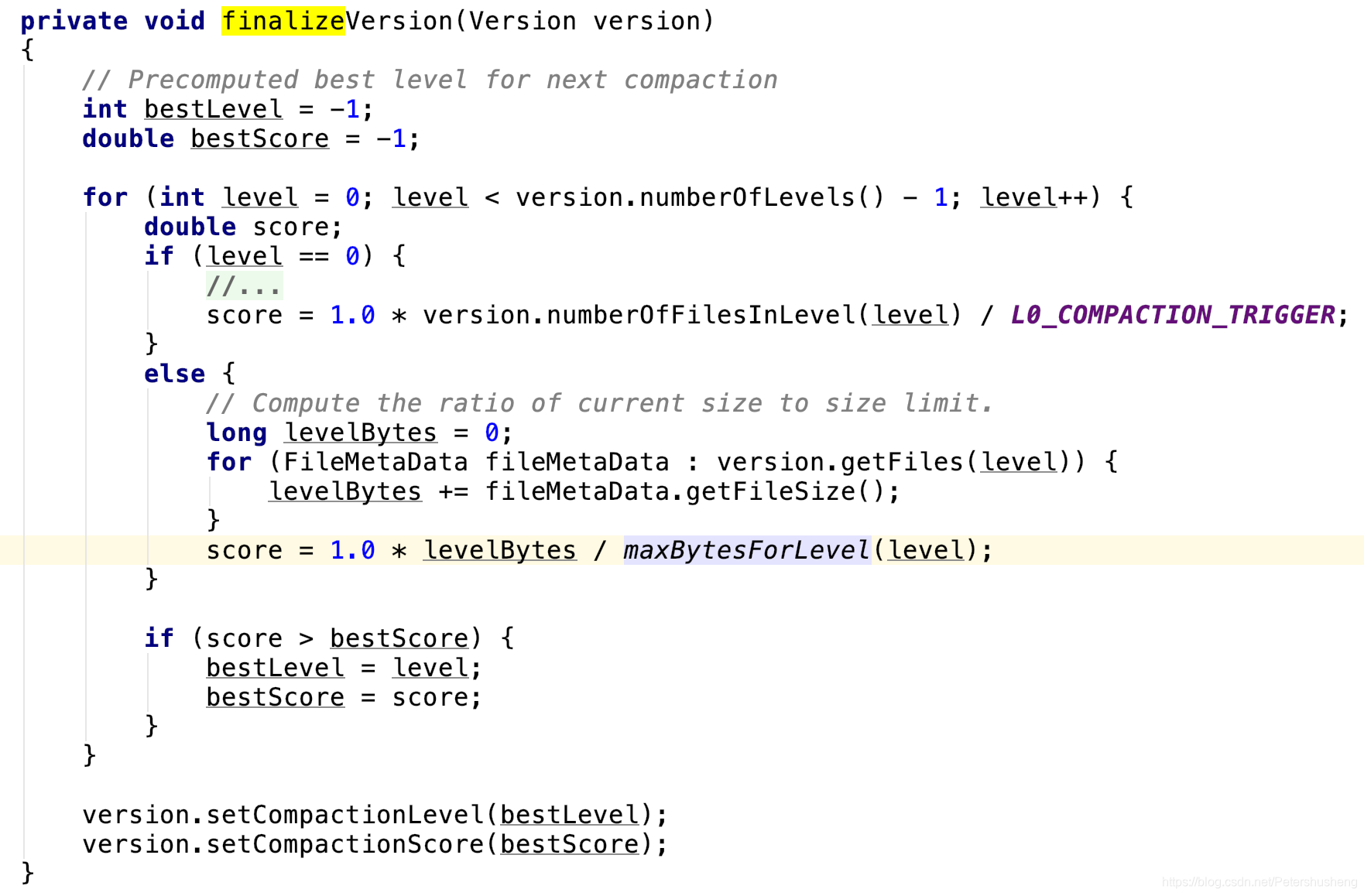
压缩文件的筛选
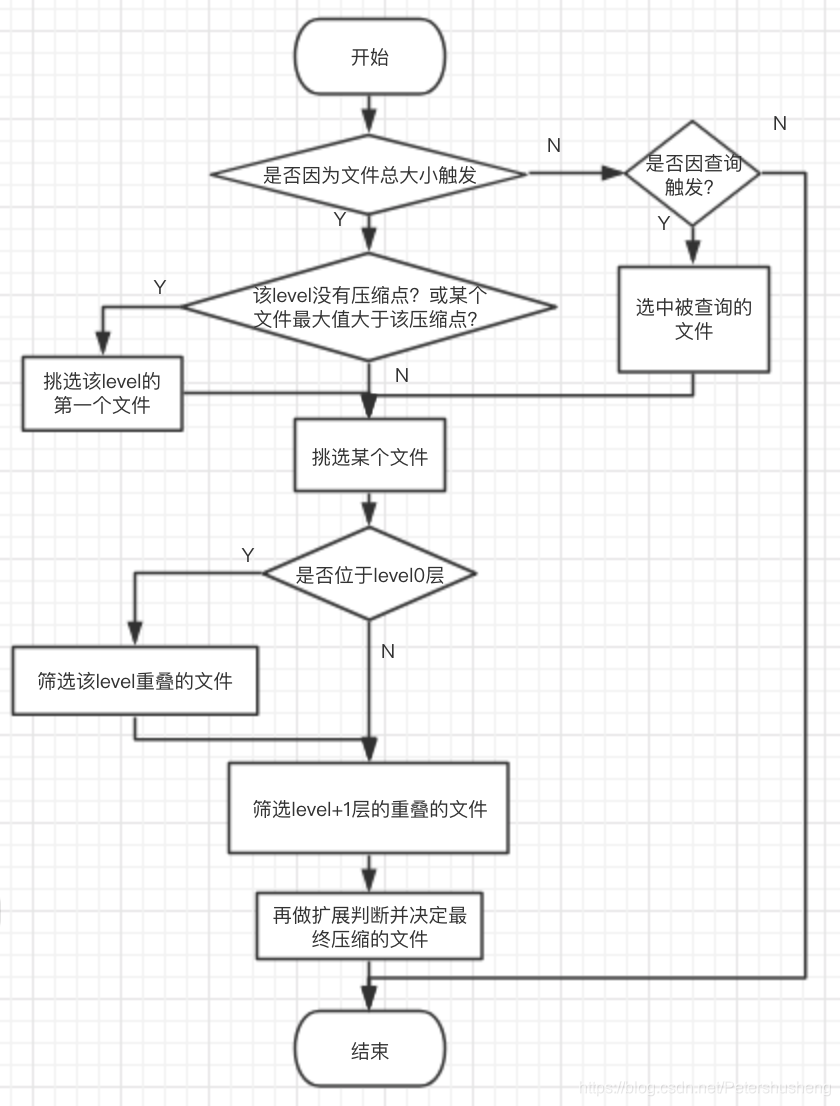
(流程图也很复杂, 心累 , 慢慢理解吧, 我已经尽自己努力讲的通俗些了)
要点:
- level1及以上的层次, 每次被压缩后, db会标记一个压缩点levelPoint, 避免每次压缩该层次的时候压缩重复的文件.
- 如果是压缩level0 , 则选择level0层的交叉文件进行压缩.
- 如果是压缩level1或者以上level , 则选择压缩点levelPoint后的第一个文件.
- 选中待压缩的level的文件后, 就选择level +1 层的交叉的文件.然后level层文件和level+1层的被选中文件一起压缩并在level+1层生成新的被压缩文件.
下面介绍如何选择文件(贪心):
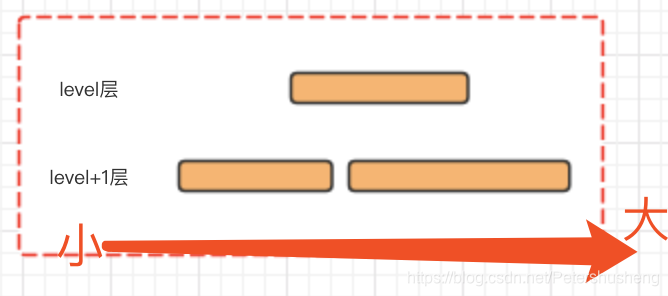
1.(如下图)如果待压缩的level层只有一个文件, 但level+1层重叠的文件有两个, 那么这三个文件会被选中压缩, 生成新的文件会放在level+1层(但压缩后的文件不一定只有一个)(数据从左到右依次增大)
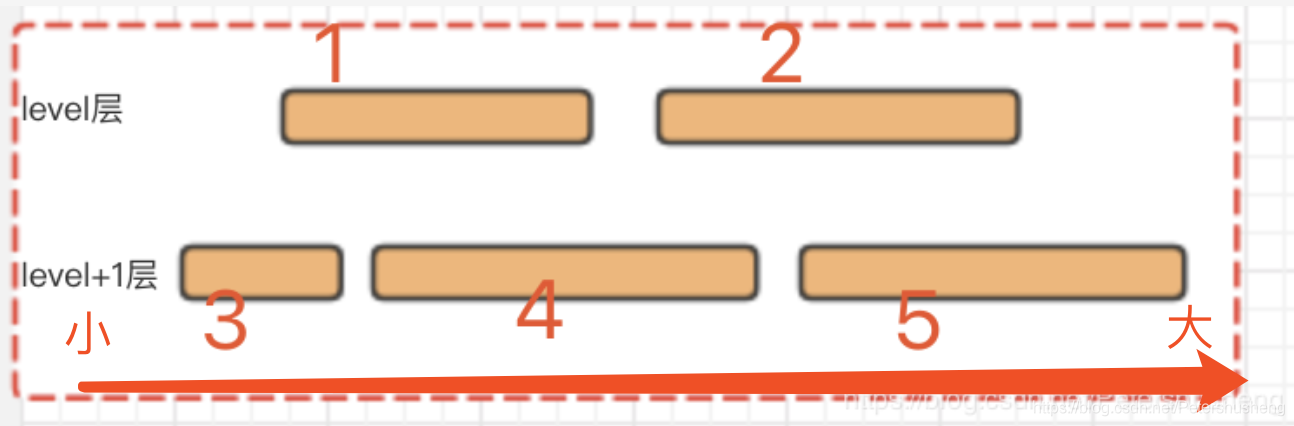
2.(如下图)待压缩的是level层.如果被选中的是2号文件, 选择level+1层交叉文件时就会选中4/5两个文件(这三个文件时必选的了), (贪心时刻)db会尝试固定level+1文件数情况下, 尽可能多地选择level层文件. (然而, 如果将1号文件选择进来了, 那么3号文件又要被选中了 , 这样将导致无穷无尽的文件被选中…), 所以这种情况下就只能选择2/4/5这三个文件进行压缩了.
- 如果level层选中的是1号文件, 在选择level +1层时根据交叉选中3和4文件, 这个时候会贪心地尽可能多选level层文件, 就会选到2号, 因为level层被选文件是1,2, 跟level+1层交叉的文件还是3, 4.level+1层被选的文件不变. 那么1/2/3/4号文件都会被选中.
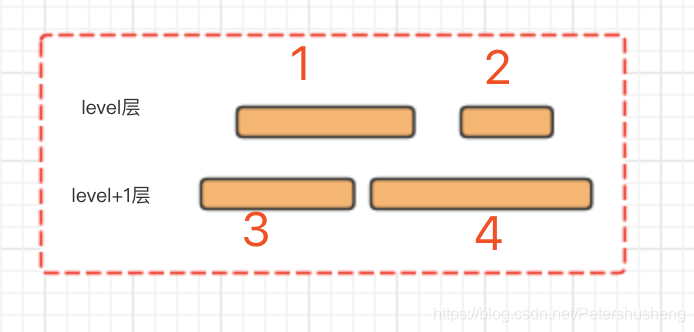
- 如果level层选中的是1号文件, 在选择level +1层时根据交叉选中3和4文件, 这个时候会贪心地尽可能多选level层文件, 就会选到2号, 因为level层被选文件是1,2, 跟level+1层交叉的文件还是3, 4.level+1层被选的文件不变. 那么1/2/3/4号文件都会被选中.
压缩–简单易懂
- 偶尔会遇到level层只有一个文件并且被选中, 但是level+1层却没有文件, 并且level+2层的文件总size < 20M时. 则直接将level层文件移动到level+1层了事…
压缩–正常压缩
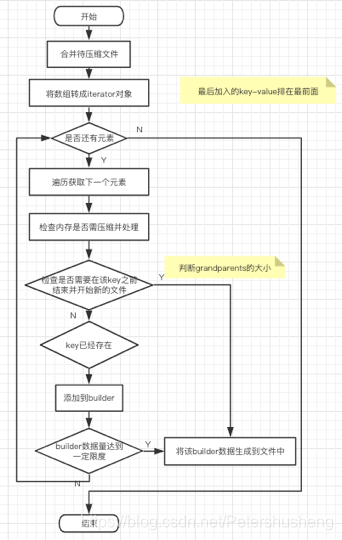
将已选中的文件进行压缩, 相同key时保留最新的key(因为level和level+1层文件有交叉, 就会有相同key的情况, level层的key比level+1层的key更新) .
按照key进行排序. 写到文件中, 当文件大小达到一定限制时, 结束该文件并写到一个新的文件(但是都写到level+1层)
好了. levelDB的文件写入到压缩过程都在这里了. 写了2个小时…(如果看到这里了. 顺手点个赞? )
(与mysql不同, levelDB的索引数据是放在level的每个文件的后面的. 就是数据和文件合并在一起的.)














 975
975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









