






拿到了全国的NDVI数据,但数据量庞大,不利于处理,所以写了以下代码将数据筛选出一定经纬度范围内,再进行后续研究。文件格式如下:
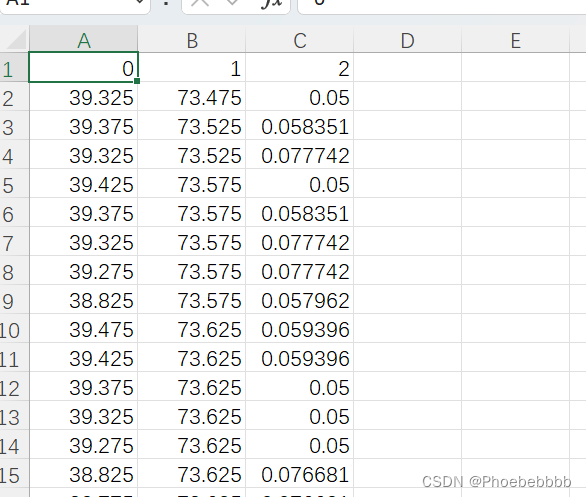
表格中0、1、2列分别代表纬度、经度、NDVI值。
为什么有两个代码,是因为在读取数据的时候,1-9月和10-12月的识别方式不同,但我没有学会解决方法,只能分两部分提取。
import pandas as pd
import os
year = 1982
month = 1
while year <= 2020:
while month <= 12:
month_length = str(month)
if len(month_length)==1:
month = str(0) + str(month)
time_index = os.path.join(str(year) + str(month))
data_ = pd.read_csv(r'G:/Python_/NDVI_CSV/' + time_index + '.csv')
out_path = os.path.join("G:/Python_/NDVI_NJ/" + time_index + '.csv')
print('processing ' + time_index + ' !!!')
data_new = data_[data_['0'] < 54]
data_new = data_[data_['0'] > 42]
data_new = data_new.sort_values(by=['0','1'], ascending=True)
data_new = data_new[data_new['1'] < 132]
data_new = data_new[data_new['1'] > 118]
data_new.to_csv(out_path)
month += 1
year += 1
month = 1import pandas as pd
import os
year = 1982
month = 10
while year <= 2020:
while month <= 12:
time_index = os.path.join(str(year) + str(month))
data_ = pd.read_csv(r'G:/Python_/NDVI_CSV/' + time_index + '.csv')
out_path = os.path.join("G:/Python_/NDVI_NJ/" + time_index + '.csv')
print('processing ' + time_index + ' !!!')
data_new = data_[data_['0'] < 54]
data_new = data_[data_['0'] > 42]
data_new = data_new.sort_values(by=['0','1'], ascending=True)
data_new = data_new[data_new['1'] < 132]
data_new = data_new[data_new['1'] > 118]
data_new.to_csv(out_path)
month += 1
year += 1
month = 10















 713
713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









