







要定义与tf.estimator一起使用的自定义模型,需要使用tf.estimator.Estimator。
tf.estimator.LinearRegressor()线性回归实际上是一个tf.estimator.Estimator的子类。
我们只是给Estimator提供了一个函数model_fn,它告诉tf.estimator如何评估预测,训练步骤和损失,而不是分类Estimator。

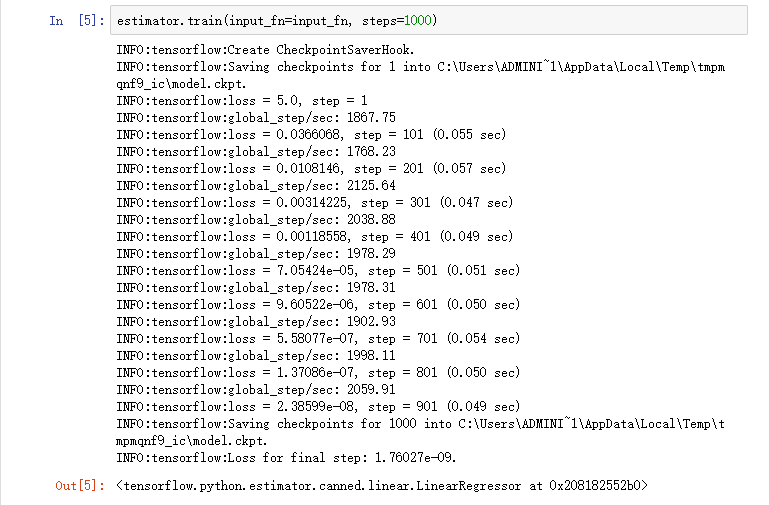
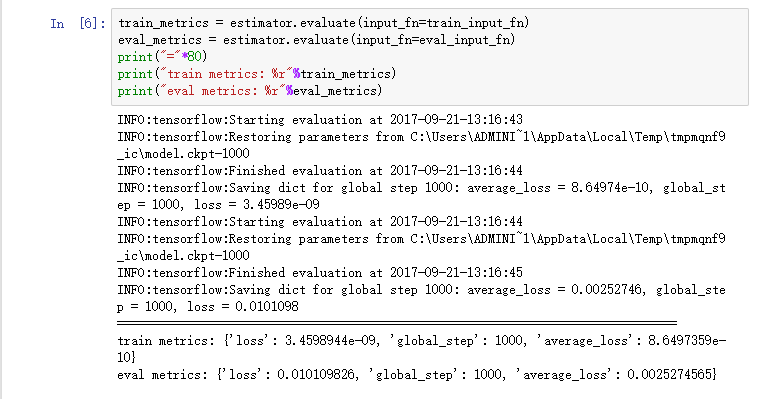
要定义与tf.estimator一起使用的自定义模型,需要使用tf.estimator.Estimator。
tf.estimator.LinearRegressor()线性回归实际上是一个tf.estimator.Estimator的子类。
我们只是给Estimator提供了一个函数model_fn,它告诉tf.estimator如何评估预测,训练步骤和损失,而不是分类Estimator。
 1255
1255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























