






一、激活函数
激活函数是深度学习神经网络模型的重要组成部分,旨在使神经网络模型能够更好地拟合数据分布,输出更为准确的结果。激活函数通常分为线性激活函数和非线性激活函数,因此激活函数的类型决定了网络该层的输出是线性的还是非线性的,并且激活函数的选择也对神经网络性能、模型收敛速率起到了很大的影响作用。本文章主要介绍三种常用的非线性激活函数。
- Sigmoid激活函数:
Sigmoid函数的图像如下图所示,其函数曲线在坐标轴上呈现"S"型,经典的S型分布是正态分布的累积分布函数,由于神经网络当中的变量、数据样本分布通常具有正态分布的特性,因此需要Sigmoid函数加入网络模型当中辅助神经网络更好地拟合数据分布。使用Sigmoid的另外一个原因在于该函数的值域为[0,1],可以用于输出预测概率值。因此通常可以用于计算熵、概率分布以及多分类等。
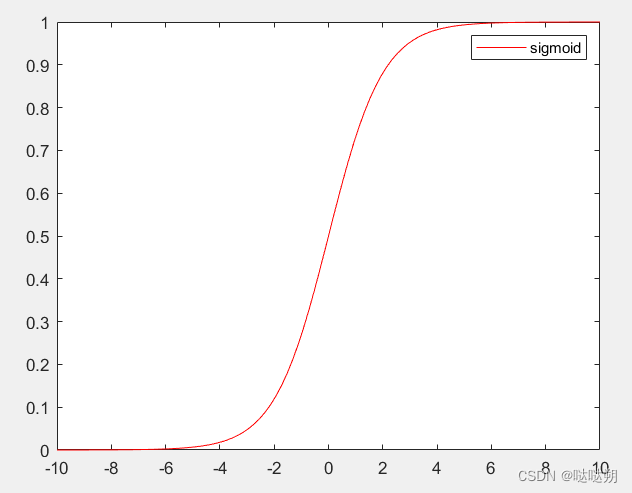
Sigmoid函数具有以下优势:
- 平滑梯度,防止输出值“跳跃”;输出值在0到1之间,对每个神经元的输出进行归一化处理;
- 明确的预测——当输入高于2或低于-2时,趋向于将输出值(预测)带到曲线的边缘,非常接近1或0。
Sigmoid函数的缺陷也非常明显,会发生梯度消失现象。对于非常高或者非常低的输入值,预测值几乎是没有变化的,均是非常接近1或者0,这就有可能导致梯度消失的问题,使神经网络模型停止学习或因学习太慢而无法做出准确的预测。另外,在仿真实验当中,Sigmoid函数的输入和输出具有不同的维度单位,输入是随机变量,输出是概率,不同维度的单位不应该相互叠加。因此,Sigmoid函数的典型应用是在神经网络模型层的末端,这样Sigmoid函数就不会给神经网络增加太多的复杂性。
2.Tanh激活函数:
Tanh函数的形状也是类似于"S"型,起函数图像如下图所示,从函数的取值范围可以看出,Tanh函数是一个经过缩放的Sigmoid函数。通过计算可以知道,,该函数的值域范围是[-1,1]。并且Tanh函数的输出是以零为中心,损失的收敛会相对容易。但是Tanh函数同样存在着梯度消失的问题。

3.ReLU激活函数:
ReLU激活函数又叫线性整流单元函数,其图像如下图所示,ReLU函数是一个分段函数,输入为正时直接输出,输入为负时则函数值为零。通过在神经网络中使用ReLU函数可以降低训练的难度,让模型收敛的更好,得到一个较好的性能。ReLU函数的优点在于:
- 计算效率高,可以是网络更快的收敛。相较于Sigmoid和Tanh函数,ReLU函数的导数明显更好求,因此在求梯度反向传播过程中计算量更小,网络模型收敛更快。
- 增加网络的非线性,作为非线性激活函数,ReLU函数加入到神经网络中可以使得网络能够更好地拟合非线性映射。
- 防止梯度消失,ReLU函数是一种非饱和激活函数,相对于Sigmoid和Tanh激活函数,ReLU激活函数不存在梯度消失现象。
- 使网络模型具有稀疏性,由于该激活函数小于0的部分值为0,大于0的部分才有值,因此可以使网络具有一定的稀疏性,减少过拟合。
尽管ReLU 激活函数克服了梯度消失问题,但是当输入的数据趋近于零或者为负时,会导致梯度为零,使得神经网络无法进行反向传播,无法继续学习。
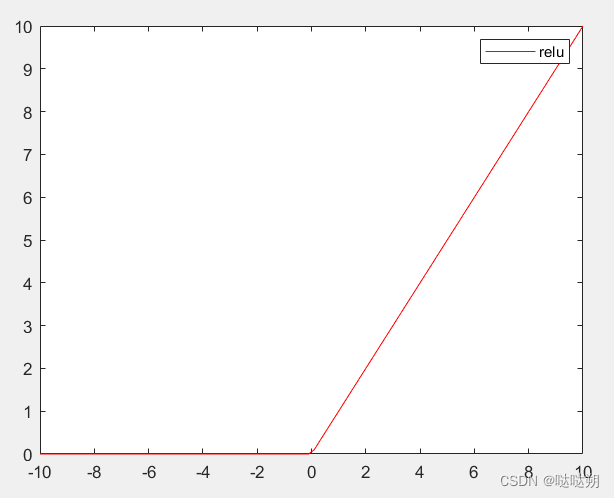
关于ReLU函数是否是一种线性激活函数呢?ReLU函数似乎具有线性函数的特性,在x轴的正半轴它是一个线性函数,在x轴的负半轴也是一个线性函数,那么可以认为ReLU函数是一个线性函数吗?答案是不能,ReLU函数依然是一个非线性的函数,尽管从分段上来看都是线性的,但是ReLU函数的整体不是线性的,因此ReLU函数也是一个非线性函数,同样可以起到输入数据从线性到非线性的转换作用。
针对上述问题我们有以下几点解释:
- 相对于浅层的机器学习,比如经典的三层神经网络,用它作为激活函数的话,那表现出来的性质肯定是线性的。但是在深度学习里,少则几十,多则上千的隐藏层,虽然,单独的隐藏层是线性的,但是很多的隐藏层表现出来的就是非线性的。
- 什么是线性网络呢,如果把线性网络看成一个大的矩阵M。那么输入样本A和B,则会经过同样的线性变换MA,MB(这里A和B经历的线性变换矩阵M是一样的)。的确对于单一的样本A,经过由ReLU激活函数所构成神经网络,其过程确实可以等价是经过了一个线性变换M1,但是对于样本B,在经过同样的网络时,由于每个神经元是否激活(0或者Wx+b)与样本A经过时情形不同了(不同样本),因此B所经历的线性变换M2并不等于M1。因此,ReLU构成的神经网络虽然对每个样本都是线性变换,但是不同样本之间经历的线性变换M并不一样,所以整个样本空间在经过ReLU构成的网络时其实是经历了非线性变换的。
- 此外,不同样本的同一个feature,在通过ReLU构成的神经网络时,流经的路径不一样(ReLU激活值为0,则堵塞;激活值为本身,则通过),因此最终的输出空间其实是输入空间的非线性变换得来的。
- 更极端化一些,根据微元法的思想,所有的函数曲线都可以看做是由很小的线性单元组成,那么可以说所有的曲线都是线性的吗,诸如Sigmoid和Tanh,当然是不可以的,因此ReLU依然是非线性激活函数。
二、损失函数
损失函数也是深度学习模型训练当中至关重要的一环, 一般来说,深度学习模型的目标函数是为了减小真实值与预测值之间的误差,误差越小则说明两者之间的差距越小,模型预测的结果越接近真实值,模型性能也就越好。通常,在深度学习当中,这样的目标函数称为成本函数或者损失函数,由损失函数计算出的值简称为“损失(loss)”。损失函数具有重要的作用,因为它必须如实地将模型的各个方面精简为一个单一的数字,用该数字的改善来衡量模型性能的改善。损失函数的选择往往决定了模型能否达到我们想要的性能结果,能否执行我们需要的任务,下面介绍两种常用的损失函数:
- 均方误差(Mean Squared Error,MSE)损失函数:
MSE函数是回归模型中常用到的损失函数,例如股价预测、非线性函数逼近等问题。MSE损失函数通常适用于计算真实数据和预测数据之间平方差的平均数,并且MSE函数的值永远非负,因为其总是对误差进行平方,公式如下:
其中,是预测值,
是真实值,
为样本数。假设输入数据是服从正态分布并分布在一个平均值周围,并且需要额外惩罚异常值时,MSE是很好的选择。MSE对异常值是敏感的,在给定几个输入特征值相同的例子下,最优预测将是这些异常值差的平方的均值,其缺点是如果某个异常值的值非常大,那么该函数的平方部分就会放大该误差。
- 交叉熵(Cross-Entropy,CE)函数:
CE函数可以是训练分类模型的损失函数,其又称为对数损失或log损失。它旨在量化两个概率分布之间的差异,它将每个类别的预测概率与真实概率相比较并计算与真实概率分布的差距大的分数,当小的差异接近0。惩罚本质上是对数的,当大的差异接近1时产生时产生小的分数。在训练过程中,利用交叉墒损失来调整模型权重。其目标是最小化损失,即损失越小模型越好,CE函数表示为:
对于个类别,
是第
个样本的真实标签,
是第
个样本的softmax概率值。
*本文部分内容来源网络,如有侵权烦请联系删除~














 1522
1522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









