主题模型
 关注
关注
 分享
分享
Unigram、LSA、PLSA主题模型
LSA和其SVD实现
PLSA模型及PLSA的EM算法
LDA隐含狄利克雷分布
LDA的python实现及参数选择
LDA主题模型的评估
主题模型可视化
LDA的缺陷和改进
基于知识的主题模型
-柚子皮-
╰☆ゞ不染纤尘,不忘初心ゞ☆╮
展开
专栏收录文章
- 默认排序
- 最新发布
- 最早发布
- 最多阅读
- 最少阅读
-
参数估计:文本分析的参数估计方法
http://blog.csdn.net/pipisorry/article/details/51482120文本分析的三类参数估计方法-最大似然估计MLE、最大后验概率估计MAP及贝叶斯估计。参数估计参数估计中,我们会遇到两个主要问题:(1)如何去估计参数的value。(2)估计出参数的value之后,如何去计算新的observation的概率,即进行回归分析和预测。首先定义一些符号:数据集X中原创 2016-05-23 17:36:47 · 16321 阅读 · 2 评论 -
Spark:聚类算法之LDA主题模型算法
http://blog.csdn.net/pipisorry/article/details/52912179Spark上实现LDA原理LDA主题模型算法[主题模型TopicModel:隐含狄利克雷分布LDA ]Spark实现LDA的GraphX基础在Spark 1.3中,MLlib现在支持最成功的主题模型之一,隐含狄利克雷分布(LDA)。LDA也是基于Gra原创 2016-10-25 17:04:28 · 17025 阅读 · 3 评论 -
主题模型TopicModel:通过gensim实现LDA
http://blog.csdn.net/pipisorry/article/details/46447561使用python gensim轻松实现lda模型。gensim简介Gensim是一个相当专业的主题模型Python工具包。在文本处理中,比如商品评论挖掘,有时需要了解每个评论分别和商品的描述之间的相似度,以此衡量评论的客观性。评论和商品描述的相似度越高,说明评论的用语比较官方,不带太多感情原创 2015-06-10 22:27:18 · 26521 阅读 · 5 评论 -
随机采样和随机模拟:吉布斯采样Gibbs Sampling
http://blog.csdn.net/pipisorry/article/details/51373090吉布斯采样算法详解为什么要用吉布斯采样什么是sampling?sampling就是以一定的概率分布,看发生什么事件。举一个例子。甲只能E:吃饭、学习、打球,时间T:上午、下午、晚上,天气W:晴朗、刮风、下雨。现在要一个sample,这个sample可以是:打球+下午+晴朗。...原创 2016-05-12 00:24:21 · 111461 阅读 · 26 评论 -
马尔科夫模型 Markov Model
http://blog.csdn.net/pipisorry/article/details/46618991生成模式(Generating Patterns)1、确定性模式(Deterministic Patterns):确定性系统 考虑一套交通信号灯,灯的颜色变化序列依次是红色-红色/黄色-绿色-黄色-红色。这个序列可以作为一个状态机器,交通信号灯的不同状态都紧跟着上一个状态。...原创 2015-06-24 10:34:20 · 122913 阅读 · 3 评论 -
主题模型TopicModel:LDA编程实现
http://blog.csdn.net/pipisorry/article/details/45771045LDA的python实现LDA的c/c++实现原创 2015-05-16 20:53:35 · 15562 阅读 · 1 评论 -
主题模型TopicModel:主题模型LDA的应用
http://blog.csdn.net/pipisorry/article/details/45665779应用于推荐系统在使用LDA(Latent Dirichlet Allocation)计算物品的内容相似度时,我们可以先计算出物品在话题上的分布,然后利用两个物品的话题分布计算物品的相似度。比如,如果两个物品的话题分布相似,则认为两个物品具有较高的相似度,反之则认为两个物品的相似原创 2015-05-12 10:10:16 · 21319 阅读 · 0 评论 -
knowledge_based topic model - AMC
http://blog.csdn.net/pipisorry/article/details/43271429ABSTRACT Topic modeling has been widely used to mine topics from documents. However,a key weakness of topic modeling is that it原创 2015-01-29 14:59:28 · 3412 阅读 · 1 评论 -
knowledge_based topic model - 基于知识的主题模型概述
http://blog.csdn.net/pipisorry/article/details/44040701LDA (Bleiet al., 2003)术语Mustlink states that two words should belong to the same topicCannot-link states that two words sho原创 2015-03-03 17:23:07 · 3265 阅读 · 2 评论 -
主题模型TopicModel:LDA的缺陷和改进
http://blog.csdn.net/pipisorry/article/details/45307369LDA的缺陷和改进1. 短文本与LDAICML论文有理论分析,文档太短确实不利于训练LDA,但平均长度是10这个数量级应该是可以的,如peacock基于query 训练模型。有一些经验技巧加工数据,譬如把同一session 的查询拼接,同一个人的twitter原创 2015-04-27 10:57:16 · 32683 阅读 · 5 评论 -
主题模型TopicModel:主题模型可视化
http://blog.csdn.net/pipisorryBrowse LDA Topic ModelsThis package allows you to create a set of HTML files to browse a topic model.It creates a word cloud and time-graph per topic, and annotat原创 2015-04-29 19:20:33 · 9180 阅读 · 0 评论 -
主题模型TopicModel:LDA主题模型的评估
LDA主题模型好坏的评估,判断改进的参数或者算法的建模能力。Blei先生在论文《Latent Dirichlet Allocation》实验中用的是Perplexity值作为评判标准。一、Perplexity定义http://en.wikipedia.org/wiki/Perplexityperplexity是一种信息理论的测量方法,b的perplexity值定义为基于b的原创 2015-01-06 17:05:04 · 32192 阅读 · 0 评论 -
主题模型TopicModel:LDA参数推导、选择及注意事项
http://blog.csdn.net/pipisorry/article/details/42129099LDA参数LDA求参推导中国科学技术信息研究所徐硕老师的PDF,对LDA,TOT,AT模型如何使用gibbs sampling求参进行了细致推导,并依据求参结果给出伪代码。地址:http://blog.sciencenet.cn/blog-611051-582492.html参数alpha原创 2014-12-24 21:14:13 · 32721 阅读 · 3 评论 -
主题模型TopicModel:LDA中的数学模型
了解LDA需要明白如下数学原理:一个函数:gamma函数四个分布:二项分布、多项分布、beta分布、Dirichlet分布一个概念和一个理念:共轭先验和贝叶斯框架两个模型:pLSA、LDA(文档-主题,主题-词语)一个采样:Gibbs采样原创 2015-01-13 10:16:52 · 9680 阅读 · 3 评论 -
主题模型TopicModel:隐含狄利克雷分布LDA
http://blog.csdn.net/pipisorry/article/details/42649657主题模型LDA简介隐含狄利克雷分布简称LDA(Latent Dirichlet allocation),是一种主题模型,它可以将文档集中每篇文档的主题按照概率分布的形式给出。同时它是一种无监督学习算法,在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主题的数量k即可。此外LDA的原创 2015-01-12 21:07:07 · 53899 阅读 · 13 评论 -
EM算法原理详解
http://blog.csdn.net/pipisorry/article/details/42550815EM算法有很多的应用,最广泛的就是GMM混合高斯模型、聚类、HMM、基于概率的PLSA模型等等。本文详细讲述EM算法的由来、EM算法的实现思路、EM算法解决PLSA和LDA的方法。概述、EM是一种解决存在隐含变量优化问题的有效方法。EM的意思是“Expectation Maximizati原创 2015-01-09 09:44:36 · 51656 阅读 · 8 评论 -
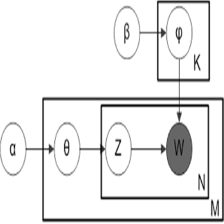
主题模型TopicModel:PLSA模型及PLSA的EM推导
基于概率统计的PLSA模型,并且用EM算法学习模型参数。PLSA的概率图模型如下其中D代表文档,Z代表隐含类别或者主题,W为观察到的单词,表示单词出现在文档的概率,表示文档中出现主题下的单词的概率,给定主题出现单词的概率。并且每个主题在所有词项上服从Multinomial 分布,每个文档在所有主题上服从Multinomial 分布。整个文档的生成过程是这样的:(1) 以的概率选中文原创 2015-01-09 20:59:44 · 12022 阅读 · 0 评论 -
主题模型TopicModel:Unigram、LSA、PLSA模型
http://blog.csdn.net/pipisorry/article/details/42560693主题模型历史Papadimitriou、Raghavan、Tamaki和Vempala在1998年发表的一篇论文中提出了潜在语义索引。1999年,Thomas Hofmann又在此基础上,提出了概率性潜在语义索引(Probabilistic Latent Semantic Inde...原创 2015-01-09 20:49:55 · 27548 阅读 · 11 评论 -
主题模型TopicModel:LSA(隐性语义分析)模型和其实现的早期方法SVD
LSA and SVDLSA(隐性语义分析)的目的是要从文本中发现隐含的语义维度-即“Topic”或者“Concept”。我们知道,在文档的空间向量模型(VSM)中,文档被表示成由特征词出现概率组成的多维向量,这种方法的好处是可以将query和文档转化成同一空间下的向量计算相似度,可以对不同词项赋予不同的权重,在文本检索、分类、聚类问题中都得到了广泛应用,在基于贝叶斯算法及KNN算法的ne原创 2015-01-09 20:40:55 · 18554 阅读 · 3 评论