







在基于RK33XX的嵌入式语音应用中,因为实时语音业务需求,项目基于linux4.4.179内核打入了rt181实时补丁,系统测试中业务工作正常,但在系统日志中偶尔出现异常问题:”BUG: scheduling while atomic...”,经过一番努力最终定位解决。
1 背景知识
1.1 linux实时补丁带来的系统差异性
Linux内核打完PREEMPT_RT实时补丁后, 新的Linux-rt实时系统与原linux系统之间的主要差异性(之一):
- 普通 Linux的内核代码在执行期间通常是不可抢占的,特别是在内核临界区中(包括Spinlock自旋锁);
- 实时 Linux内核在大多数情况下是可抢占的(除了极少数临界区),系统使用可抢占的锁机制,允许在持有锁的情况下进行上下文切换。后面提到的“Spinlock_rt.h”文件就是实时补丁引入的,使得Spinlock自旋锁可以被抢占。
1.2 业务系统对ps和grep进程的调用
本项目的业务系统需要周期性(周期可配,如1秒或10秒)调用“CMD="ps aux|grep $PN |grep -v grep"”的bash脚本来对业务进程健康状态进行监控,这样系统就会比较频繁的调用ps和grep进程(包括进程退出),这在后续的系统告警日志会出现。
2 问题现象
该实时linux系统在连续运行一段时间(一般是几天)后,获取系统日志message,可以一定概率随机看到如下异常告警(摘录):
... ... ... ...(省略无关信息)
[389398.804459] BUG: scheduling while atomic: ps/29202/0x00000002
[389398.804467] Modules linked in:
[389398.804475] CPU: 0 PID: 29202 Comm: ps Tainted: G W O 4.4.179-rt181 #72
[389398.804476] Hardware name: FriendlyElec NanoPi M4B (DT)
[389398.804481] Call trace:
[389398.804497] [<ffffff8008089268>] dump_backtrace+0x0/0x248
[389398.804502] [<ffffff80080894d4>] show_stack+0x24/0x30
[389398.804508] [<ffffff8008421274>] dump_stack+0x9c/0xc0
[389398.804514] [<ffffff80080c99a0>] __schedule_bug+0x58/0x68
[389398.804523] [<ffffff8008b8d1a8>] __schedule+0x4c8/0x558
[389398.804526] [<ffffff8008b8d280>] schedule+0x48/0xe8
[389398.804531] [<ffffff8008b8ec38>] rt_spin_lock_slowlock+0x228/0x2c0
[389398.804536] [<ffffff8008b906cc>] rt_spin_lock+0x64/0x70
[389398.804544] [<ffffff80080edc78>] __wake_up+0x30/0x60
[389398.804549] [<ffffff80080f1aa4>] __percpu_up_read+0x44/0x50
[389398.804556] [<ffffff80080af39c>] exit_signals+0x1c4/0x240
[389398.804562] [<ffffff80080a1aec>] do_exit+0x94/0x9f8
[389398.804566] [<ffffff80080a24dc>] do_group_exit+0x3c/0xa0
[389398.804570] [<ffffff80080a2560>] __wake_up_parent+0x0/0x40
[395555.924872] BUG: scheduling while atomic: grep/3662/0x00000002
[395555.924881] Modules linked in:
[395555.924888] CPU: 2 PID: 3662 Comm: grep Tainted: G W O 4.4.179-rt181 #72
[395555.924890] Hardware name: FriendlyElec NanoPi M4B (DT)
[395555.924895] Call trace:
[395555.924909] [<ffffff8008089268>] dump_backtrace+0x0/0x248
[395555.924915] [<ffffff80080894d4>] show_stack+0x24/0x30
[395555.924921] [<ffffff8008421274>] dump_stack+0x9c/0xc0
[395555.924928] [<ffffff80080c99a0>] __schedule_bug+0x58/0x68
[395555.924936] [<ffffff8008b8d1a8>] __schedule+0x4c8/0x558
[395555.924940] [<ffffff8008b8d280>] schedule+0x48/0xe8
[395555.924945] [<ffffff8008b8ec38>] rt_spin_lock_slowlock+0x228/0x2c0
[395555.924950] [<ffffff8008b906cc>] rt_spin_lock+0x64/0x70
[395555.924957] [<ffffff80080edc78>] __wake_up+0x30/0x60
[395555.924962] [<ffffff80080f1aa4>] __percpu_up_read+0x44/0x50
[395555.924969] [<ffffff80080af39c>] exit_signals+0x1c4/0x240
[395555.924975] [<ffffff80080a1aec>] do_exit+0x94/0x9f8
[395555.924980] [<ffffff80080a24dc>] do_group_exit+0x3c/0xa0
[395555.924984] [<ffffff80080a2560>] __wake_up_parent+0x0/0x40
[395555.924988] [<ffffff8008082f70>] el0_svc_naked+0x24/0x28
... ... ... ...(省略无关信息)
2 原因分析
2.1 异常调用栈分析
从上述系统日志看,ps进程和grep进程分别在开机389398秒和395555秒时抛出“BUG: scheduling while atomic:...”的异常告警,而且都是在进程退出时触发的异常调度告警,虽然两段异常日志时间间隔近2小时(6157秒),但是异常告警时的函数调用栈过程基本一致:
“ps/grep进程退出”触发系统调用
=> (...)do_exit
=> exit_signals
=> percpu_up_read(先后调用preempt_disable和__percpu_up_read,参见2.2章节)
=>__percpu_up_read
=> __wake_up
=> spin_lock_irqsave(rt实时补丁调用rt_spin_lock,参见2.3章节)
=> rt_spin_lock
=> (...)schedule_debug
=>__schedule_bug(触发异常告警“BUG: scheduling while atomic”,参见2.4章节)
调用栈分析:
1)ps/grep进程在退出时会调用percpu_up_read函数(用于释放进程先前通过percpu_down_read函数获取的资源读取锁),设计上该函数不允许抢占(会调用preempt_disable使得后续过程变为不可抢占的临界区)。
2)后续调用过程“__wake_up=》spin_lock_irqsave”在非实时linux中是不可抢占的,但在打入实时补丁后,自旋锁spin_lock函数指向了可抢占的rt_spin_lock函数,最终触发了“BUG: scheduling while atomic:...”告警。
问题焦点在percpu_up_read函数的不可抢占设计与linux实时补丁中可抢占锁机制的冲突。
2.2 percpu_up_read函数介绍
如图1,内联函数percpu_up_read在调用__percpu_up_read之前,会先调用preempt_disable使得后续过程变为不可抢占的临界区。

图1 percpu_up_read函数
2.3 spin_lock_irqsave函数介绍
在实时补丁Spinlock_rt.h文件中,spin_lock_irqsave通过spin_lock重定义指向可以抢占的rt_spin_lock函数:
#define spin_lock(lock) rt_spin_lock(lock)
#define spin_lock_irqsave(lock, flags) \
do { \
typecheck(unsigned long, flags); \
flags = 0; \
spin_lock(lock); \
} while (0)
2.4 schedule_debug函数介绍
如图2,在linux内核core.c文件中,(cpu被抢占时)系统调度函数__schedule会调用schedule_debug函数对当前cpu的抢占值preempt_count进行合法性检查(in_atomic_preempt_off),如果preempt_count异常,则会触发系告警“BUG: scheduling while atomic”。
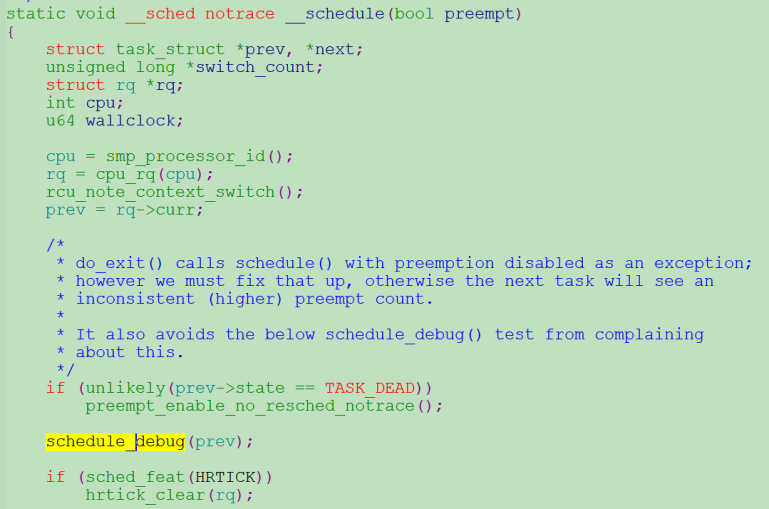
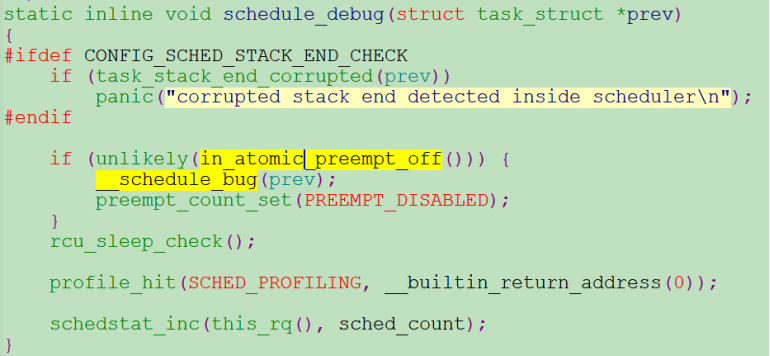

图2 __schedule_bug及相关调用函数
3 解决方案
根据前面的原因分析,解决问题的主要思路是打破percpu_up_read函数的不可抢占设计与linux实时补丁中可抢占锁机制之间的冲突,具体方案有两种:
- 局部性改进方案:改造__percpu_up_read函数,断开实时系统中对后续wake_up函数的调用。
- 全局性改进方案:改造实时补丁中rt_spin_lock实时自旋锁函数,增加对当前cpu的抢占值preempt_count的检查。
3.1 局部性改进方案
如下代码示例,局部性改造__percpu_up_read函数,当系统为实时系统时(即配置为CONFIG_PREEMPT_RT_FULL)改为调用一个新增的raw_wake_up函数(该函数使用不可抢占的原始自旋锁 raw_spin_lock_irqsave)避免被抢占。
void raw_wake_up(wait_queue_head_t *q)
{
unsigned long flags;
struct rt_mutex *rtlock = &q->lock.lock;
raw_spin_lock_irqsave(&rtlock->wait_lock, flags);
__wake_up_common(q, TASK_NORMAL, 1, 0, NULL);
raw_spin_unlock_irqrestore(&rtlock->wait_lock, flags);
}
void __percpu_up_read(struct percpu_rw_semaphore *sem)
{
//unsigned long flags;
smp_mb(); /* B matches C */
/*
* In other words, if they see our decrement (presumably to aggregate
* zero, as that is the only time it matters) they will also see our
* critical section.
*/
__this_cpu_dec(*sem->read_count);
/* Prod writer to recheck readers_active */
#ifdef CONFIG_PREEMPT_RT_FULL
raw_wake_up(&sem->writer);
#else
wake_up(&sem->writer);
#endif
}
3.2 全局性改进方案
全局性改造实时补丁中rt_spin_lock实时自旋锁函数的适应性,增加对当前cpu的抢占值preempt_count的检查,如果preempt_count不可抢占,则不允许进入被抢占模式;具体的代码修改这里略。
4 总结
实时系统产生异常告警的根本原因在内核中percpu_up_read函数的不可抢占设计与linux实时补丁中可抢占锁机制的冲突。
推荐的两种解决方案中,也是各有优缺点:
- 局部性方案:优点是针对性强,改动影响范围小,验证起来也相对容易;缺点是明显的头痛医头,没有彻底解决实时补丁中自旋锁变为可抢占模式后与原非实时linux的设计冲突问题。
- 全局性方案:有点是彻底解决实时补丁中自旋锁变为可抢占模式后与原非实时linux的设计冲突问题,缺点是机制性改动大,影响也大,需要严格测试验证才可以实用。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









