









Python实战案例:图书借阅系统TF-IDF的计算
图书借阅系统一般是对图书的借书还书进行管理的图书馆管理系统。对于这样的系统,什么样的图书是用户比较感兴趣的,然后在藏书方面进行数量的增加,什么样的图书用户关注度不佳,那么在藏书方面进行数量的减少。这不是单单只靠书的名字来确定的一个结果,最主要的还是对内容的提练,而对数据分析而言就是对关键词的提取。TF-IDF意思是词频/逆词逆,更好的理解词频/逆词频最好还是回归到项目中,因此,这里用图书借阅系统的图书目录表的分析来具体解释TF/IDF的理解,也就是词频/逆词频的具体应用。
一、《图书目录表》的读取和数据清洗
对于《图书目录表》是一个excel表格,可以用pandas模块对《图书目录表》进行读取,读取后的效果如下图所示。

从图中的效果看,分为了3个字段,图书ID,书名和图书分类号,这里面对计算词频/逆词频有用的字段是书名和图书分类号,使用loc方法把book中的数据只保留这两个字段的内容。具体代码及效果如下图所示。
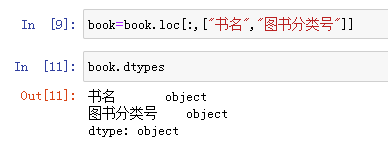
从图中结果看,book.loc[;,[“书名",”图书分类号"]]这样的语句就是只取列名为“书名”和“图书分类号”的列值赋值给book。这样book中的数据就只包括“书名”和“图书分类号”这两个列的数据,又由于“书名”和“图书分类号”是object型数据,即字符串数据,所以需要字符串的两边把空格去掉,这是一般文本处理的时候都需要使用的手段,strip()方法就是实现去除文本字符串两端的空格,把“书名”和“图书分类号”字段都做为字符串需要调用strip()去除,对于“图书分类号”一般情况下遵循“I247.57/12”这样的规则意义:从左到右的字符含义:I表示文学,2表示中国,4表示小说,7表示现代小说,7表示新体长篇、中篇小说,斜杠/后面的12表示的是书在书架上的位置。为了表示方便,每三个数字之间用一个点隔开。“I”是字母,表示《中国图书馆图书分类法》,关于这个方法,实际上有一个简表,可以从网上下载得知,分类法简法内容大致如下图所示。

这也是图书管理项目中图书馆管理的一个专业度所在。只要符合A-Z中任一个字母加上一些数字串的样式,都可以做为图书分类号的正确编号,对于“书名”或“图书分类号”字段为空的数据进行删除,用drop_duplicates()方法实现,这里分析词频的时候,把文学类的图书去掉,不供参考,文学类的图书多以分类为主,词频/逆词频可以单独去分析,除了文学类的图书以外,其它图书的词频/逆词频更能反映专业度上或者其它领域上的图书的藏书参考,文学类图书往往是比较特殊的分析,有着大众的受众群,可以单独分析。这样经过去掉“书名”和“图书分类号”两侧的空格,“图书分类号”的匹配操作、“书名”和“图书分类号”去空以及过滤掉“文学”的图书分类,最后重排索引值的相关语句及执行后效果如下图所示。

这样,就完成了对《图书目录表》数据的清洗阶段。
二、TF-IDF的计算
下面需要计算TF-IDF,这里需要使用jieba分词库。因为去除文学后,有一些专业词汇,所以需要jieba分词加载用户定义词库,用户定义词库的txt文件内容如下。
从图中的结果上看,用户自定义的词库就是增加一些专业词汇。利用jieba分词添加用户自定义专业词汇的语句是jieba.load_userdict,其实现效果如下图所示。

接下来利用jieba中analyse模块的extract_tags(x)提取“书名”字段的关键词,提取后通守stack()变成竖列,重新分配索引,用rename取一个维度的名称,比如叫“词条”, 这样相当于book这个表中就有了“词条”这个维度列,可以把“书名”这个维度列删除。使用的具体语句如下。
import jieba.analyse
words=book.drop("书名",axis=1).join(pandas.DataFrame(jieba.analyse.extract_tags(x) for x in book["书名"]).stack().reset_index(level=1,drop=True).rename("词条"))
执行该语句后的结果如图所示。

书名被分词,就需要计算词频,即某个词在文章中出现的次数除文章的总词数。具体公式表示为
![]()
根据公司,是要计算一个文章的总词数,如果利用dwcount字段来表示每个jieba分词的词条数为1,那么对这个字段进行分组,再求sum()和值,按“图书分类号”分组,再按“词条”分组,sum()的求和就是这个词条在这个“图书分类号”中出现的次数,这时的dwcount字段存储的数据也是某个词在文章中出现的次数,执行语句以及执行后的结果如下图所示。

对于词频计算的另一个参数文章的总词数,可以通过下面的语句获得。
![]()
然后就可以通过words[“dwcount”]与words[“wtotal”]来计算tf的值。代码语句可以通过下图表示。
![]()
最终,tf的运行结果如图所示。

接下来继续计算IDF,根据IDF的公式。如下。
![]()
分母采用加1的换算,是为了避免零分母。
根据公式,求出总文档数,代码语句可以通过下图表示。
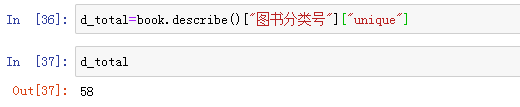
从结果上看,图书分类号中的文档数是58篇,也就是总文档数58。
下面再计算“包含该词的文档数”,其实就是按词条分组统计该词条下的count()值。代码语句可以通过下图表示。
![]()
由此,idf可以运用公式算出,代码语句通过下图表示。

最终计算TF-IDF可以将tf和idf的结果做乘积。即:
TF-IDF = TF x IDF
结果如下图所示。

三、TF-IDF的理解
对于某些文章,如果直接将统计词频后的特征做为文本分类的输入,会发现有一些问题。比如有一些文本,如"JAVA","分布式"和“微服务”只能在一些专业的文献中出现,而“程序“可能在多篇文章中出现。似乎看起来这个文本与”程序“这个特征更关系紧密。但是实际上”程序“是一个非常普遍的词,往往是一个统称,几乎所有的文本都会用到,因此虽然它的词频很高,但是重要性却比“JAVA”,“分布式”、“微服务”要低的多。如果向量化特征仅仅用词频表示就无法反应这一点,TF-IDF可以反映这一点,不但对某个词在单个文本中的词频做衡量的维度,在全部文本中的出现频率也可以做维度上的衡量。
TF-IDF是Term Frequency - Inverse Document Frequency的缩写,即“词频-逆文本频率”。它由TF和IDF两部分组成。
TF(词频): TF就是前面说到的词频,也就是文本中各个词的出现频率统计。
假定存在一份有N个词的文件A,其中“粉丝”这个词出现的次数为T。那么
![]()
所以表示为: 某一个词在某一个文件中出现的频率。
IDF反映一个词在所有文本中出现的频率,如果一个词在很多的文本中出现,这个词可能不能反映文档的特点,那么它的IDF值应该低。而反过来如果一个词在比较少的文本中出现,那么它的IDF值应该高。
TF-IDF(词频-逆向文件频率):表示的词频和逆向文件频率的乘积.
比如: 假定存在一份有N个词的文件A,其中“粉丝这个词出现的次数为T。那么
![]()
且“粉丝”这个词,在W份文件中出现,而总共有X份文件,那么
![]()
而:
![]()
这里发现,‘粉丝’,这个出现在W份文件,W越小 TF-IDF越大,也就是这个词越有可能是该文档的关键字,而不是习惯词(类似于:‘的’,‘是’,‘不是’这些词),而TF越大,说明这个词在文档中的信息量越大。















 1610
1610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









