







 本文详细介绍了GPU渲染管线的组成,包括顶点着色器、几何着色器、像素着色器等阶段,以及可编程着色器的进化历史。通过对《Real-Time Rendering 3rd》第三章的提炼,读者可以了解GPU如何实现渲染过程中的可配置性和可编程性,以及不同阶段的功能和特点。
本文详细介绍了GPU渲染管线的组成,包括顶点着色器、几何着色器、像素着色器等阶段,以及可编程着色器的进化历史。通过对《Real-Time Rendering 3rd》第三章的提炼,读者可以了解GPU如何实现渲染过程中的可配置性和可编程性,以及不同阶段的功能和特点。
本文由@浅墨_毛星云 出品,转载请注明出处。
文章链接: http://blog.csdn.net/poem_qianmo/article/details/71978861
这篇文章是解析计算机图形学界“九阴真经总纲”一般存在的《Real-Time Rendering 3rd》系列文章的第三篇。将带来RTR3第三章内容“Chapter 3 The Graphics Processing Unit 图形处理器”的总结、概括与提炼。
这章的主要内容是介绍GPU渲染管线的组成,以及可编程着色的进化史,顶点、几何、像素三种可编程着色器。
本文总字数7.3k,分为全文内容思维导图、原书核心内容分章节提炼、本章内容提炼总结三个部分来呈现。
一、全文内容思维导图
1.章节框架思维导图
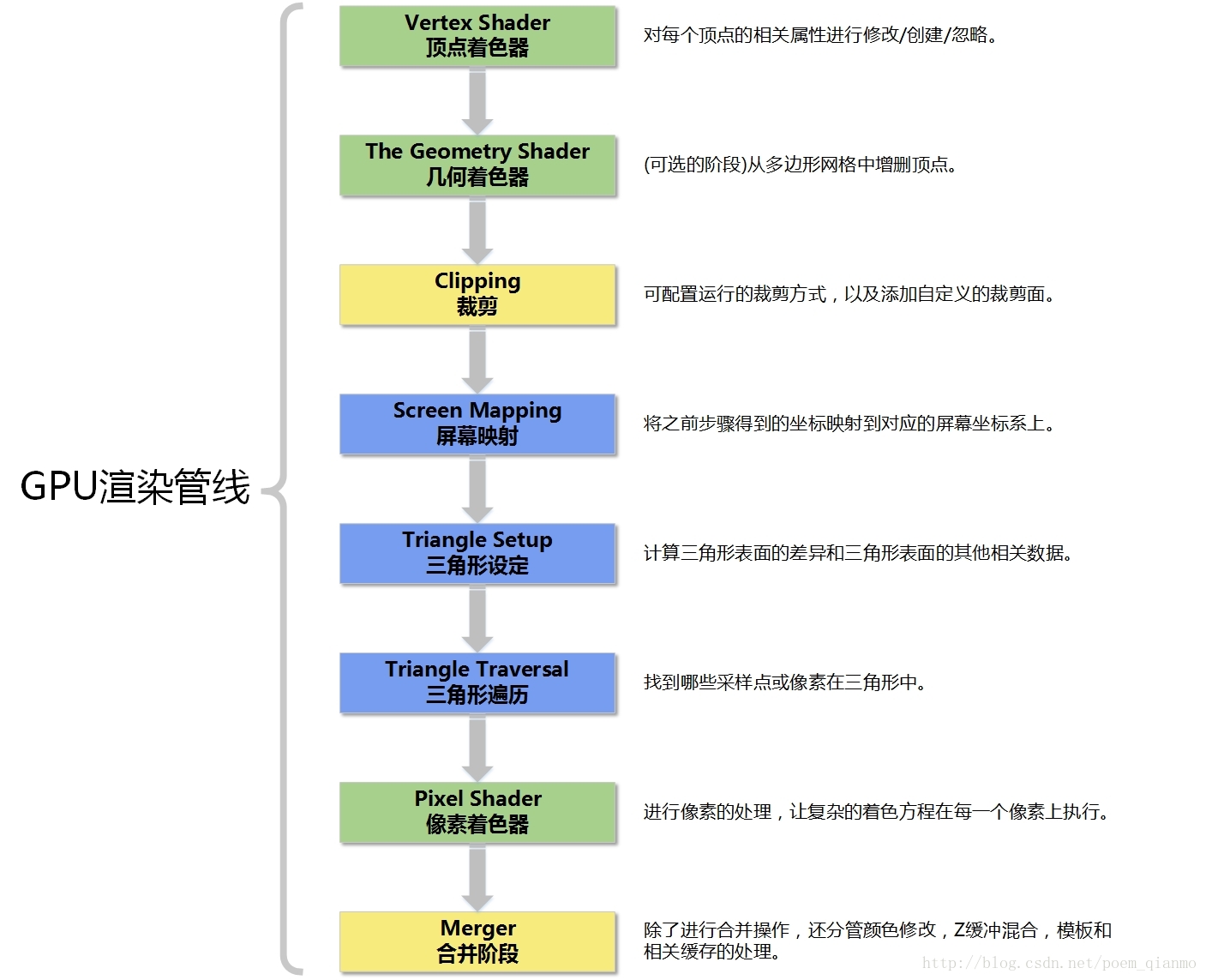
2. GPU渲染管线流程图
其中:
- 绿色的阶段都是完全可编程的。
- 黄色的阶段可配置,但不可编程。
- 蓝色的阶段完全固定。
二、原书核心内容分节提炼
3.1 GPU管线概述
- 第一个包含顶点处理,面向消费者的图形芯片(NVIDIA GeForce256)发布于1999年,且NVIDIA提出了图形处理单元(Graphics Processing Unit ,GPU)这一术语,将GeForce256和之前的只能进行光栅化处理的图形芯片相区分。在接下来的几年中,GPU从可配置的固定功能管线演变到了支持高度可编程的管线。直到如今,各种可编程着色器依然是控制GPU的主要手段。为了提高效率,GPU管线的一部分仍然保持着可配置,但不是可编程的,但大趋势依然是朝着可编程和更具灵活性的方向在发展。
- GPU实现了第二章中描述的几何和光栅化概念管线阶段。其被分为一些不同程度的可配置性和可编程性的硬件阶段。如图3.1 所示
图3.1 GPU实现的渲染管线
上图中,不同颜色的阶段表示了该阶段不同属性。其中:


 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















评论 6

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包








