







Spark Streaming的流处理基于时间间隔的批处理
这个世界上所有事情是由时间主宰的
Structured Streaming预计在Spark 2.3的时候成熟
认识Structured Streaming
以前输入输出是Input Output,现在是Input Table 和 Output Table。
看名字就知道多出了一个表,
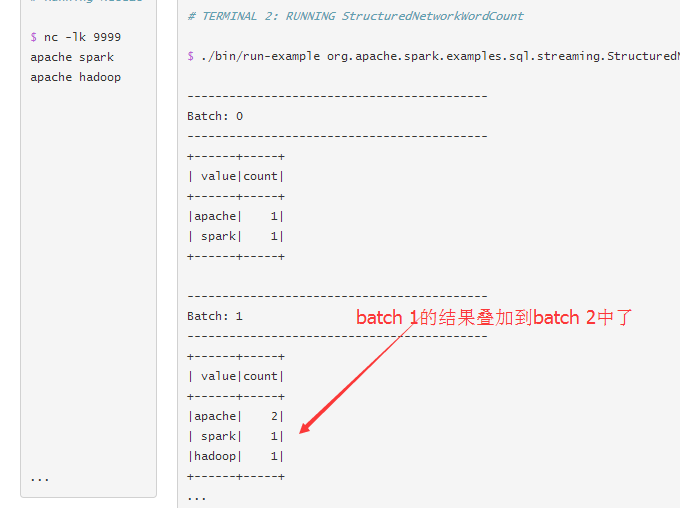
可以理解为输入的数据不直接用于计算而是先放到一个表里,那是一个增量表,输出结果也是这样,
先放到一个表里,这也是一样增量表,基于表的增量计算,可以叠加结果
这样的好处是可以把结果作为流处理数据服务中心!数据可以带有原始的时间戳。
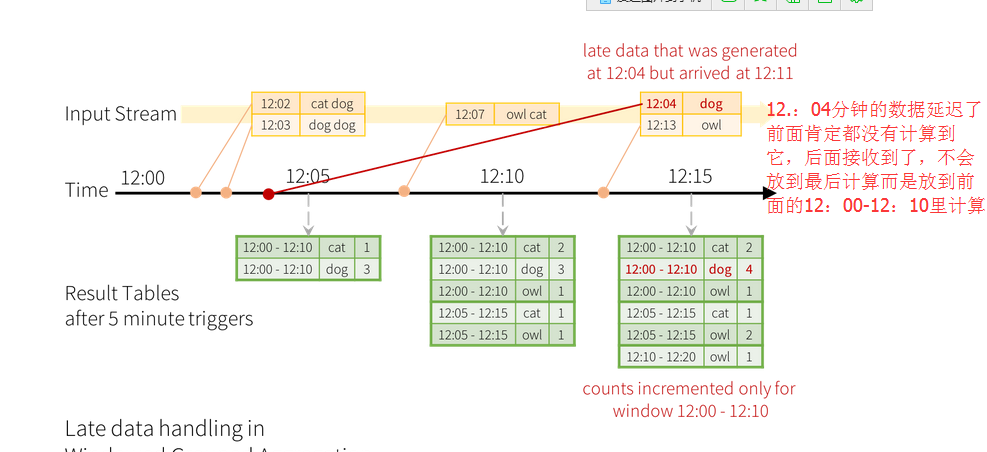
以前的sparkstreaming对于延后的数据的处理是将之放于最后的batch里处理的,
比如处理间隔是一个小时,一个小时前的数据由于网络等问题现在才接收到,
那就会把这数据放在这个小时的batch中处理,但是现在数据有了时间戳后,
就会将数据放在上个batch 来处理
ForeachWriter
以前对于写入数据库的数据,是先从各个节点收集数据到Driver,再从Driver写到数据库里面,
用的是foreach/foreachPartitioner。而现在有了ForeachWriter 这个方法
abstract class ForeachWriter[T] extends Serializable
里面有三个方法datasetOfString.write.foreach(new ForeachWriter[String] { def open(partitionId: Long, version: Long): Boolean = { // open connection } def process(record: String) = { // write string to connection } def close(errorOrNull: Throwable): Unit = { // close the connection } })因为已经继承自Serializable,所以是发送到每个Executor中,让每个Executor去连接数据库并写入数据。
这就实现了分布式地写入数据库中。(写的时候写入小表)从总体上而言,推出了一个新概念 Continuous Application
不管是Storm还是以前的Spark Streaming都不能保证离线处理数据的结果与流处理数据的结果是完全一 致的,但是Structured Streaming能保证这一点,因为是端对端的处理,Structured Streaming终将一统大数据流处理,从而确定Spark大数据的霸主地位 : )
以上内容部分来自[DT大数据梦工厂]首席专家Spark专家王家林老师的课程分享。感谢王老师的分享,更多精彩内容请扫描关注[DT大数据梦工厂]微信公众号DT_Spark















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









