







leveldb是一个单节点的k/v数据存储系统,它的特点是写操作非常快而读操作则会慢一些。整个系统的结构图如下所示:
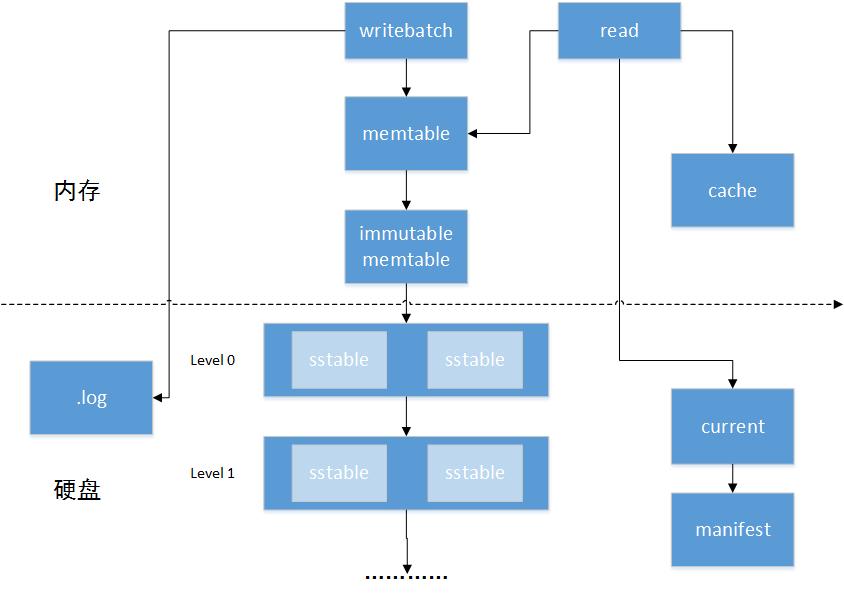
下面结合我自己的理解,分析一下整个leveldb工作的原理
转换流程:
如图中所示,memtable和immutable memtable以及cache是存储在内存中的数据,其中memtable和immutable memtable的结构是一样的,都是在skiplist的数据结构外包装了一层接口的数据,区别就是immutable memtable是只读的。memtable的数据在满足一定条件的前提下会转化为immutable memtable的数据,immutable memtable的数据则通过compaction转化为硬盘中level0的数据,level0的数据也会通过compaction向更高层的level转换,其中,每个level的数据都是以多个sstabl*e的数据格式存储的。除了这些主要的数据结构,*cache是用来缓存最近用到的sstable的索引和内容,用来提高查找速度的模块。current和manifest则用来存储所有sstable的相关索引。
写操作:
用户通过db提供的api把多个要写的k/v数据整理成一个writebatch格式的数据,来写入。首先writebatch往硬盘上的.log文件里顺序写入,然后再默认按照k的字典序往memtable中插入。因为是往硬盘中的.log中顺序写入,所以速度也比较快,而且.log会根据大小和版本的变化自动删除旧的.log文件。而在memtable中,k/v是按照skiplist的形式组织的,有序插入的时间复杂度为logn,所以速度也非常快。
读操作:
当用户要求读取db中某个k的value时,首先db会在memtable中查找,如果没找到,则继续往下在immutable memtable中查找,如果没找到,则在cache中找,如果还没有则从硬盘中的低level往高level的数据块中依次寻找知道找到为止。
合并操作:
即后台操作compaction,这个操作分成两块,第一部分是内存数据到level0的compaction,第二部分是硬盘中sstable的compaction。这两个操作主要结构差不多,这里和在一起讲。db内部对每一块数据有个打分的机制,分数的高低跟这块数据的大小和访问次数等有关,当得分达到一定值得时候,db就会对这块数据进行compaction。因为数据都是按照k的字典序排列的,所以compaction的过程其实就是一个归并排序的归并过程。
优化部分:
1. 对于k/v数据的存储,db中采用了protocal buffer 里的变长整形编码方法节省空间。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。可以参考这里http://www.ibm.com/developerworks/cn/linux/l-cn-gpb/
2. sstable 存储数据采用前缀压缩和snappy压缩。
3. sstable 中有索引的存在,加速了查找。
4. 整个db采用多层的level的组织结构,使得较新的数据总是存储在最前面,看起来像是一个n层的cache,优雅而又快速。















06-13
 1038
1038
1038
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









