









解析卷积神经网络——基础理论篇
第一章 卷机神经网络基础知识
1.1发展历程
卷积神经网络发展历史中的第一件里程碑事件发生在上世纪60年代左右的神经科学中,1959 年提出猫的初级视皮层中单个神经元的“感受野”概念,紧接着于1962年发现了猫的视觉中枢里存在感受野、双目视觉和其他功能结构,标志着神经网络结构首次在大脑视觉系统中被发现。

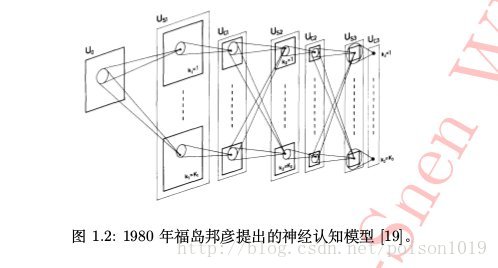
1980年前后,日本科学家福岛邦彦在之前两个人工作的基础上,模拟生物视觉系统并提出了一种层级化的多层人工神经网络,即“神经认知”,以处理手写字符识别和其他模式识别任务。神经认知模型在后来也被认为是现今卷积神经网络的前身。在福岛邦彦的神经认知模型中,两种最重要的组成单元是“s型细胞”和“c型细胞”,两类细胞交替堆叠在一起构成了神经认知网络。其中,s型细胞用于抽取局部特征,c型细胞则用于抽象和容错,如图所示,不难发现这与现今卷积神经网络中的卷积层和汇合层可一一对应。
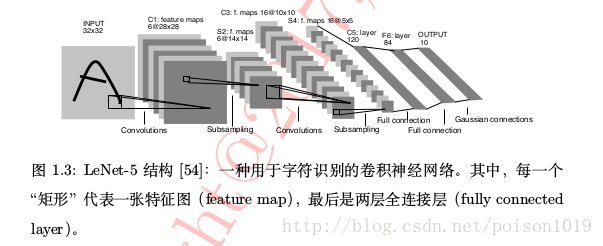
随后,Yann LeCun等人在1998年提出基于梯度学习的卷积神经网络算法,并将其成功用于手写数字字符识别,在那时的技术条件下就能取得低于1%的错误率。
2012年,在有计算机视觉界“世界杯”之称的ImageNet图像分类竞赛四周年之际,Geoffrey E. Hinton等人凭借卷积神经网络Alex-Net力挫日本东京大学、英国牛津大学VGG组等劲旅 ,且以超过第二名近12%的准确率一举夺得该竞赛冠军,霎时间学界业界纷纷惊愕哗然。自此便揭开了卷积神经网络在计算机视觉领域逐渐称霸的序幕,此后每年竞赛的冠军非深度卷积神经网络莫属。
直到2015年,在改进了卷积神经网络中的激活函数后,卷积神经网络在ImageNet 数据集上的性能(4.94%)第一次超过了人类预测错误率(5.1%)。深度卷积神经网络自2012年的一炮而红,到现在俨然已成为目前人工智能领域一个举足轻重的研究课题,甚至可以说深度学习是诸如计算机视觉、自然语言处理等领域主宰性的研究技术,同时更是工业界各大公司和创业机构着力发展力求占先的技术奇点。
1.2 基本结构
卷积神经网络是一种层次模型,其输入是原始数据,如图像、原始音频数据等。卷积神经网络通过卷积操作、汇合操作和非线性激活函数映射等一系列操作的层层堆叠,将高层语义信息逐层由原始数据输入层中抽取出来,逐层抽象,这一过程便是“前馈运算”。其中,不同类型操作在卷积神经网络中一般称作“层”:卷积操作对应“卷积层”,汇合操作对应“汇合层”等等。最终,卷积神经网络的最后一层将其目标任务(分类、回归等)形式化为目标函数 。通过计算预测值与真实值之间的误差或损失(loss),凭借反向传播算法将误差或损失由最后一层逐层向前反馈,更新每层参数,并再次前馈,如此往复,直至网络模型收敛,从而达到训练模型的目的。
计算机视觉应用中,卷机神经网络的数据层通常是:H行,w列,3个通道(RGB)的图像,记为x1。对应的第一层操作参数记为w1。
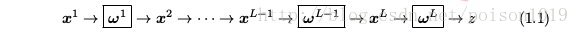
损失函数为
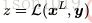
其中,函数 L(·) 中的参数即 ω L 。事实上,可以发现对于层中的特定操作,其参数 ω i 是可以为空的,如汇合操作、无参的非线性映射以及无参损失函数的计算等。实际应用中,对于不同任务,损失函数的形式也随之改变。
对于回归问题,常用的L2损失函数即可作为卷积网络的目标函数,
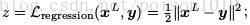
对于分类问题,网络的目标函数常采用!交叉墒损失函数,
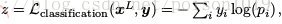
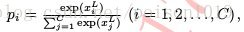
显然,无论回归问题还是分类问题,在计算 z 前,均需要通过合适的操作得到与 y 同维度的x L ,方可正确计算样本预测的损失/误差值。
1.3前馈运算
无论训练模型时计算误差还是模型训练完毕后获得样本预测,卷积神经网络的前馈运算都较直观。同样以图像分类任务为例,假设网络已训练完毕,即其中参数 ω 1 , … , ω L−1 已收敛到某最优解,此时可用此网络进行图像类别预测。预测过程实际就是一次网络的前馈运算: 将测试集图像作为网络输入 x 1 送进网络,之后经过第一层操作 ω 1 可得 x 2 ,依此下去……直至输出x L ∈ R C 。上一节提到,x L 是与真实标记同维度的向量。在利用交叉墒损失函数训练后得到的网络中,x L 的每一维可表示 x 1 分别隶属 C 个类别的后验概率。
1.4反馈运算
同其他许多机器学习模型(支持向量机等)一样,卷积神经网络包括其他所有深度学习模型都依赖最小化损失函数来学习模型参数。不过需指出的是,从凸优化理论来看,神经网络模型不仅是非凸函数而且异常复杂,这便带来优化求解的困难。该情形下,深度学习模型采用随机梯度下降法(SGD)和误差反向传播进行模型参数更新。
具 体 来 讲, 在 卷 积 神 经 网 络 求 解 时, 特 别 是 针 对 大 规 模 应 用 问 题,常采用批处理的随机梯度下降法。批处理的随机梯度下降法在训练模型阶段随机选取 n 个样本作为一批(batch)样本,先通过前馈运算得到预测并计算其误差,后通过梯度下降法更新参数,梯度从后往前逐层反馈,直至更新到网络的第一层参数,这样的一个参数更新过程称为一个“批处理过程”(mini-batch)。不同批处理之间按照无放回抽样遍历所有训练集样本,遍历一次训练样本称为“一轮”(epoch)。其中,批处理样本的大小(batch size)不宜设置过小。过小时,由于样本采样随机,按照该样本上的误差更新模型参数不一定在全局上最优(此时仅为局部最优更新),会使得训练过程产生振荡。而批处理大小的上限则主要取决于硬件资源的限制,如GPU显存大小。一般而言,批处理大小设为32,64,128或256 即可。
下面我们来看误差反向传播的详细过程。假设某批处


1.5 小结
- 本章回顾了卷积神经网络自 RN8N 年至今的发展历程;
- 介绍了卷积神经网络的基本结构,可将其理解为通过不同种类基本操作层的“堆叠”将原始数据表示不经任何人为干预直接映射为高层语义表示并实现向任务目标映射的过程——这也是为何深度学习被称作“端到端”学习或作为“表示学习”中最重要代表的原因;
- 介绍了卷积神经网络中的两类基本过程:前馈运算和反馈运算。神经网络模型通过前馈运算对样本进行推理和预测,通过反馈运算将预测误差反向传播逐层更新参数,如此两种运算依次交替迭代完成模型的训练过程。















 2091
2091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









