









解析卷积神经网络——基础理论篇
*南京大学计算机系机器学习与数据挖掘所(LAMDA)在读博士魏秀参开放了一份较系统完整的 CNN 入门材料《解析卷积神经网络——深度学习实践手册》。这是一本面向中文读者轻量级、偏实用的深度学习工具书,内容侧重深度卷积神经网络的基础知识和实践应用。本书的受众为对卷积神经网络和深度学习感兴趣的入门者,以及没有机器学习背景但希望能快速掌握该方面知识并将其应用于实际问题的各行从业者。
全书共 14 章,除“绪论”外可分为2 个篇章:第一篇“基础理论篇”包括第1~4章,介绍卷积神经网络的基础知识、基本部件、经典结构和模型压缩等基础理论内容;第二篇“实践应用篇”包括第5~14章,介绍深度卷积神经网络自数据准备始,到模型参数初始化、不同网络部件的选择、网络配置、网络模型训练、不平衡数据处理,最终直到模型集成等实践应用技巧和经验。 本系列文章为本人读书学习的摘录以及思考,希望和志同者一起探讨学习(0.0)。*
书籍链接:
http://lamda.nju.edu.cn/weixs/book/CNN_book.pdf
https://pan.baidu.com/s/1pLcaFij
https://drive.google.com/file/d/1sa1aSzYrNtGzXbegL02JtbYw3z3ZE13m/view?usp=sharing
目录
基础理论篇
解析卷积神经网络 目录和绪论
第一章 卷机神经网络基础知识
第二章 卷机神经网络基本部件
第三章 卷积神经网络经典结构
实践应用篇
绪论
(我觉得是没有用的,看看就好。)
引言
阿尔法狗 4 : 1 大胜人类围棋的顶级高手李世石,使其迅速成为全世界热议的话题,也让人们牢牢记住了一个原本陌生的专有名词——“深度学习”(deep learning)。
什么是深度学习?
比起深度学习,“机器学习”一词应更耳熟能详。
机器学习(machine learning )是人工智能的一个分支,它致力于研究如何通过计算的手段,利用经验(experience)来改善计算机系统自身的性能。通过从经验中获取知识,机器学习算法摒弃了人为向机器输入知识的操作,转而凭借算法自身来学到所需所有知识。对于传统机器学习算法而言,“经验”往往对应以“特征”(feature)形式存储的“数据”(data),传统机器学习算法所做的事情便是依靠这些数据产生“模型”(model)。
但是“特征”为何?如何设计特征更有助于算法学到优质模型?……一开始人们通过“特征工程”(feature engineering)形式的工程试错性方式来得到数据特征。可是随着机器学习任务的复杂多变,人们逐渐发现针对具体任务生成特定特征不仅费时费力,同时还特别敏感,很难将其应用于另一任务。此外对于一些任务,人类根本不知道该如何用特征有效表示数据。例如,人们知道一辆车的样子,但完全不知道怎样设计的像素值配合起来才能让机器“看懂”这是一辆车。这种情况就会导致若特征“造”的不好,最终学习任务的性能也会受到极大程度的制约,可以说,特征工程决定了最终任务性能的“天花板”。聪明而倔强的人类并没有屈服:既然模型学习的任务可以通过机器自动完成,那么特征学习这个任务自然完全可以通过机器自己实现。于是,人们尝试将特征学习这一过程也用机器自动的“学”出来,这便是“表示学习”(representation learning)。
表示学习的发展大幅提高了很多人工智能应用场景下任务的最终性能,同时由于其自适应性使得人工智能系统可以很快移植到新的任务上去。“深度学习”便是表示学习中的一个经典代表。深度学习以数据的原始形态(raw data)作为算法输入,经过算法层层抽象将原始数据逐层抽象为自身任务所需的最终特征表示,最后以特征到任务目标的映射(mapping)作为结束,从原始数据到最终任务目标,“一气呵成”并无夹杂任何人为操作。如图所示,相比传统机器学习算法仅学得模型这一单一“任务模块”而言,深度学习除了模型学习,还有特征学习、特征抽象等任务模块的参与,借助多层任务模块完成最终学习任务,故称其为“深度”学习。
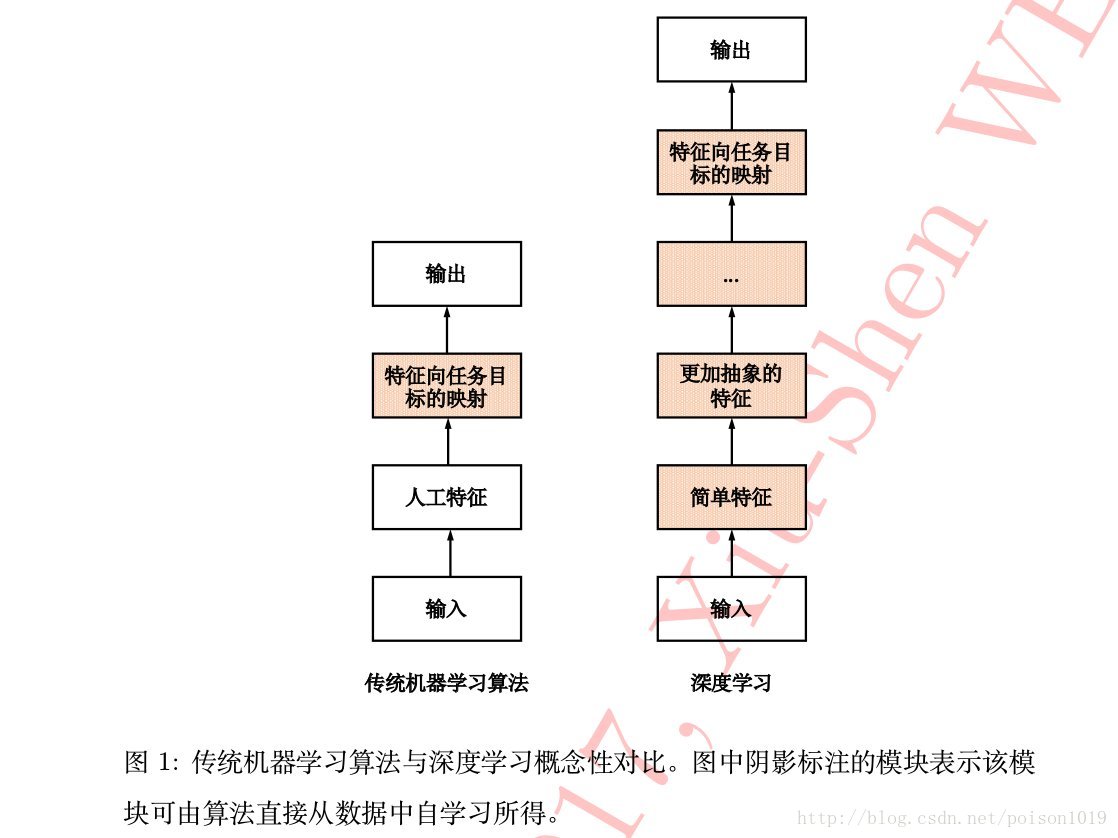
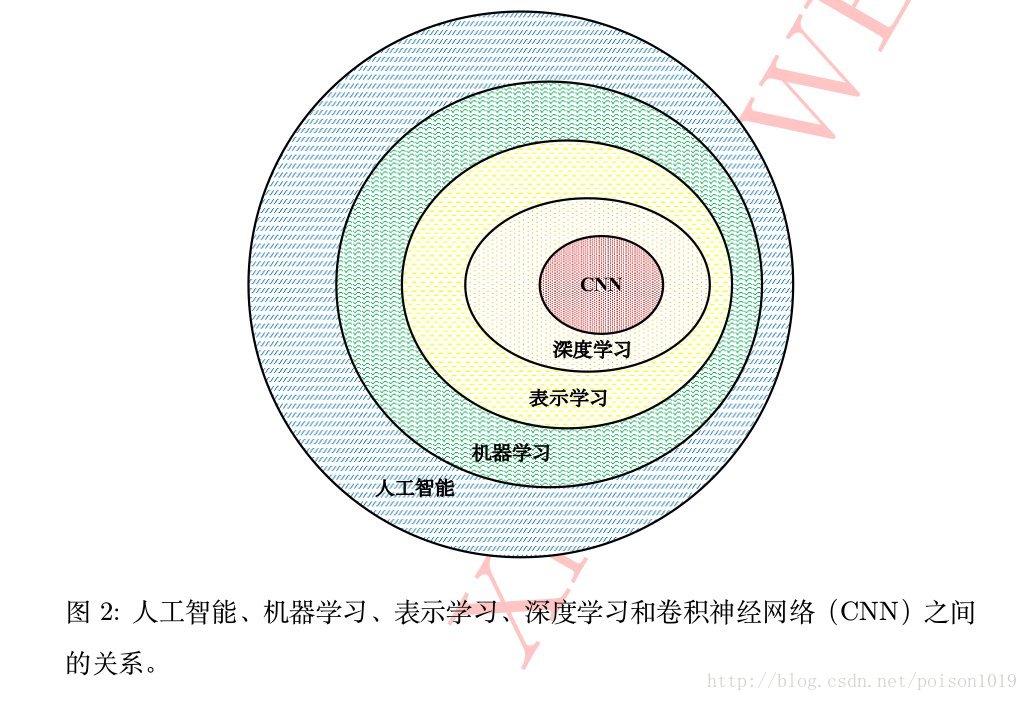
深度学习中的一类代表算法是神经网络算法,包括深度置信网络(deep belief network)、递归神经网络(recurrent neural network)和卷积神经网络(convolution neural network)等等。特别是卷积神经网络,目前在计算机视觉、自然语言处理、医学图像处理等领域“一枝独秀”,它也是本书将侧重介绍的一类深度学习算法。有关人工智能、机器学习、表示学习和深度学习等概念间的关系可由下图中的韦恩图表示。
深度学习的前世今生
虽说阿尔法狗一鸣惊人,但它背后的深度学习却是由来已久。相对今日之繁荣,它一路而来的发展不能说一帆风顺,甚至有些跌宕起伏。追根溯源,深度学习的思维范式实际上是人工神经网络(artificial neural networks),从古溯今,该类算法的发展经历了三次高潮和两次衰落。
第一次高潮是二十世纪四十至六十年代当时广为人知的控制论(cybernetics)。当时的控制论是受神经科学启发的一类简单的线性模型,其研究内容是给定一组输入信号 x 1 , x 2 , … , x n 去拟合一个输出信号 y,所学模型便是最简单的线性加权:f (x, ω) = x 1 ω 1 + · · · + x n ω n 。显然,如此简单的线性模型令其应用领域极为受限,最为著名的是:它不能处理“异或”问题(XOR function)。因此,人工智能之父 Marvin Minsky曾在当时撰文批判神经网络存在的两点关键问题:首先,单层神经网络无法处理“异或”问题;其次,当时的计算机缺乏足够的计算能力满足大型神经网络长时间的运行需求。Minsky对神经网络的批判将其研究在60年代末带入“寒冬”,人工智能产生了很多不同的研究方向,可唯独神经网络好像逐渐被人淡忘。
直到80年代,David Rumelhar和Geoffery E.Hinton 等人提出了反向传播(back propagation)算法,解决了两层神经网络所需要的复杂计算量问题,同时克服了Minsky说过神经网络无法解决异或问题,自此神经网络“重获生机”,迎来了第二次高潮,即二十世纪八十至九十年代的连接主义(connectionism)。不过好景不长,受限于当时数据获取的瓶颈,神经网络只能在中小规模数据上训练,因此过拟合(overfitting)极大困扰着神经网络型算法。同时,神经网络算法的不可解释性令它俨然成为一个“黑盒”,训练模型好比撞运气般,有人无奈的讽刺说它根本不是“科学”(science)而是一种“艺术”(art)。另外加上当
时硬件性能不足而带来的巨大计算代价使人们对神经网络望而却步,相反,如支持向量机(support vector machine)等数学优美且可解释性强的机器学习算法逐渐变成历史舞台上的“主角”。短短十年,神经网络再次跌入“谷底”。甚至当时在一段时间内只要和神经网络沾边的学术论文几乎都会收到类似这样的评审意见:“The biggest issue with this paper is that it relies on neural networks(这篇论文最大的问题,就是它使用了神经网络。)”
但可贵的是,尽管当时许多人抛弃神经网络转行做了其他方向,但如Geoffery E.Hinton和 Yann LeCun等人仍“笔耕不辍”在神经网络领域默默耕耘,可谓“卧薪尝胆”。在随后的30 年,随着软件算法和硬件性能的不断优化,直到2006年,Geoffery E.Hinton等在Science上发表文章提出:一种称为“深度置信网络”的神经网络模型可通过逐层预训练(greedy layer-wise pretraining)的方式有效完成模型训练过程。很快,更多的实验结果证实了这一发现,更重要的是除了证明神经网络训练的可行性外,实验结果还表明神经网络模型的预测能力相比其他传统机器学习算法可谓“鹤立鸡群”。Hinton发表在Science上的这篇文章无疑为神经网络类算法带来了一片曙光。接着,被冠以“深度学习”名称的神经网络终于可以大展拳脚,首先于2011年在语音识别领域大放异彩,其后便是在2012年计算机视觉“圣杯”ImageNet竞赛上强势夺冠,再来于2013年被MIT科技纵览(MIT Technology Review)评为年度十大科技突破之首……这就是第三次高潮,也就是大家都比较熟悉的深度学习时代。其实,深度学习中的“deep”一部分是为了强调当下人们已经可以训练和掌握相比之前神经网络层数多得多的网络模型。不过也有人说深度学习无非是“新瓶装旧酒”,而笔者更愿意将其比作“鸟枪换炮”。正因为有效数据的急剧扩增、高性能计算硬件的实现以及训练方法的大幅完善,三者作用最终促成了神经网络的第三次“复兴”。
细细想来,其实第三次神经网络的鼎盛与前两次大有不同,这次深度学习的火热不仅体现在学术研究领域的繁荣,它更引发相关技术产生了巨大的现实影响力和商业价值——人工智能不再是一张“空头支票”。尽管目前阶段的人工智能还没有达到科幻作品中的强人工智能水平,但当下的系统质量和性能已经足以让机器在特定任务中完胜人类,也足以产生巨大的产业生产力。深度学习作为当前人工智能热潮的技术核心,哪怕研究高潮过段时间会有所回落,但仍不会像前两次衰落一样被人彻底遗忘。它的伟大意义在于,它就像一个人工智能时代人类不可或缺的工具,真正让研究者或工程师摆脱了复杂的特征工程,从而可以专注于解决更加宏观的关键问题;它又像一门人工智能时代人类必需的语言,掌握了它就可以用之与机器“交流”完成之前无法企及的现实智能任务。因此许多著名的大型科技公司,如微软、百度、腾讯和阿里巴巴等纷纷第一时间成立了自己聚焦深度学习的人工智能研究院或研究机构。相信随着人工智能大产业的发展,慢慢的,人类重复性的工作可被机器替代,从而提升社会运转效率,把人们从枯燥的劳动中解放出来参与到其他更富创新的活动中去。
有人说“人工智能是不懂美的”,即便阿尔法狗在围棋上赢了人类,但它根本无法体会“落子知心路”给人带来的微妙感受。不过转念一想,如果真有这样一位可随时与你“手谈”的朋友,怎能不算是件乐事?我们应该庆幸可以目睹并且亲身经历、甚至参与这次人工智能的革命浪潮,相信今后一定还会有更多像阿尔法狗一样的奇迹发生。此时,我们登高望远,极目远眺;此时,我们指点江山,挥斥方裘。正是此刻站在浪潮之巅,因此我们兴奋不已、彻夜难眠。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









