







说明:测试flink-cep的性能,采用控制变量法,测试环境 为4个节点, 一主三从,从节点参考图1 。图2是测试过程中机器性能观测,flink1是主节点,flink2是从节点之一,
通过观测,数据在5G以上 CPU利用率在90%左右,几乎能充分利用,那内存不用说 也是充分利用,网络IO 在高峰时达到6Mb/s ,平均在1Mb/s.
1.其中在Flink Stream上控制的变量为:
restartAttempt:尝试恢复的次数
checkpoint:多长对数据做一次checkpoint
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(restartAttempt, 10000));
env.enableCheckpointing(Checkpoint);
env.setParallelism(6);
2.在CEP 上主要控制within(...)算子,表示数据在这个时间范围外丢弃。为什么在下面的第一阶段测试中within设置20秒?如图0,在数据量小(小于1G)的情况下,
经过测试within从1s到20s中,20秒能保证job能完成。这里有个矛盾,后续有机会讨论。
在之前做过一些小的数据量的测试(参考图0),数据都能处理完,这次数据量设置在10G,runtime表示job提交后数据被成功处理了多长时间。。。然后job failed。
第一阶段测试:(MAC 版的有道云笔记做图很不方便,还坑我丢了好几次数据,准备要换掉。win版真心不错)
| 数据量(G) | within(s) | restartAttempt | checkpoint(ms) | runtime(s) | 说明 |
| 10 | 20 | 1 | 50 | 0 | job failed |
| 10 | 20 | 1 | 80 | 0 | yjob failed |
| 10 | 20 | 1 | 100 | 0 | job failed |
| 10 | 20 | 1 | 150 | 76 | job failed |
| 10 | 20 | 1 | 500 | 3 | job failed |
| 10 | 20 | 1 | 1000 | 450,。。。 | 在刷新了linux的cache后,释放掉内存,重新提交,发现runtime 450s,算是不错, 之后重新运行多次 runtime都在100s内 |
| 数据量(G) | within(s) | restartAttempt | checkpoint(ms) | runtime(s) | 说明 |
| 10 | 20 | 1 | 5000 | 141, 6,99,66 | Could not restore checkpointed state to operators and functions |
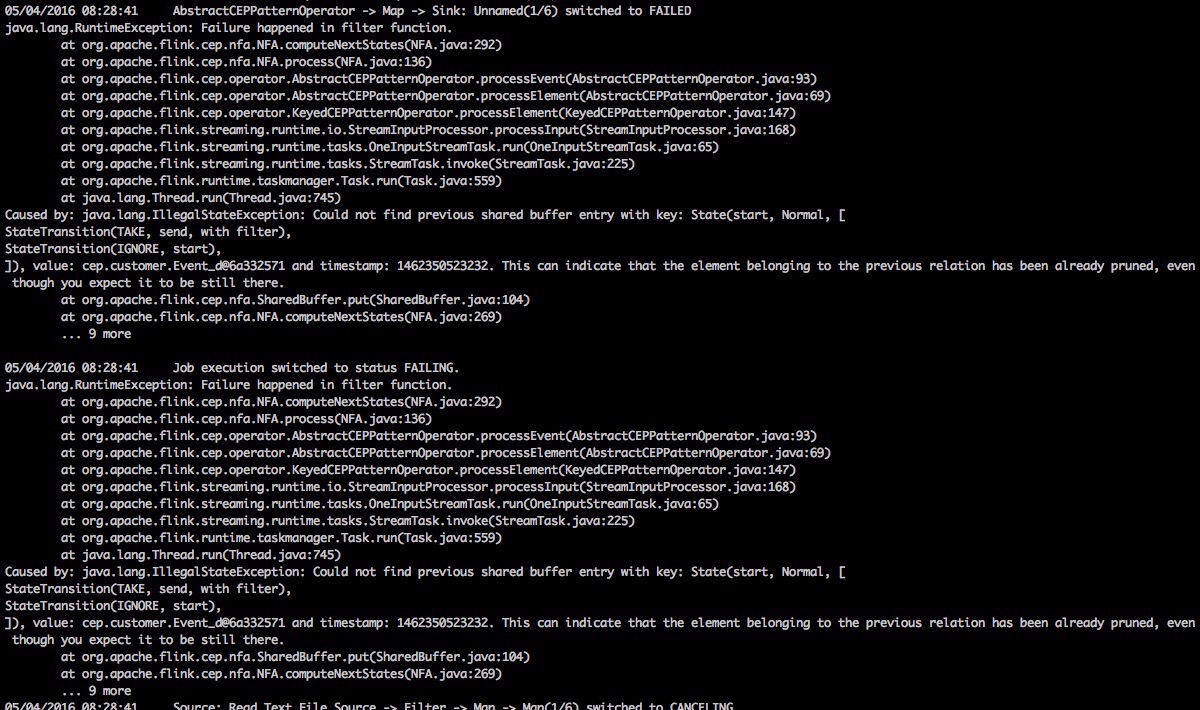
| 10 | 20 | 3 | 1000 | 709,100,171 | 很奇怪,启动几次job失败,报错看图3,重启集群后 , 正常运行700s后保存退出,报错看图4,之后重新运行3次都在 |
| 10 | 20 | 4 | 1000 | 161,33,233,102 | job failed |
| 10 | 20 | 6 | 1000 | 303,22,7,155 | job failed |
| 10 | 20 | 3 | 5s | 200,720,49,640 | job failed |
| 10 | 20 | 4 | 5s | 421,622,104,512 | job failed |
| 10 | 20 | 6 | 5s | 524,253,318,736 | job failed |
| 说明:runtime 一列中 (141, 6,99,66)表示 job提交4次 和对应的处理结果,第一次跑141s,第二次跑了6s,以此类推。 |
小结:
1,restartAttempt =1 && checkpoint <1000ms : job根本运行不了
2,restartAttempt=6s checkpoint =5s ,堪称“完美”
3,在这样的集群环境下,runtime=500s 大概就是处理了2G左右的数据
第二阶段测试:restartAttempt=6s checkpoint =5s ,改变within的大小
| 数据量(G) | within(s) | restartAttempt | checkpoint(ms) | runtime(s) | 说明 |
| 10 | 1 | 6 | 5s | 54,72,66,73,452 | 4次都是同个报错,关于这个问题,我在StackOverflow提问过,
|
| 10 | 5 | 6 | 5s | 66,464,519,429 | job failed |
| 10 | 15 | 6 | 5s | 471,311,560,74,258 | job failed |
| 10 | 20 | 6 | 5s | 25,86,144,102 | job failed |
| 10 | 25 | 6 | 5s | 54,294,24,17,47 | job failed |
| 10 | 30 | 6 | 5s | 62,14,134,78 | job failed |
| 10 | 35 | 6 | 5s | 45,133,232,22 | job failed |
小结:
1,很明显 当within提高5s,执行时长一下提高了
2, 理想状态是20s左右
总结:Flink-CEP是4月6新增的特性,第一次迭代才一个月,存在很多Bug,相信后续的版本一定会完善的。
图0:
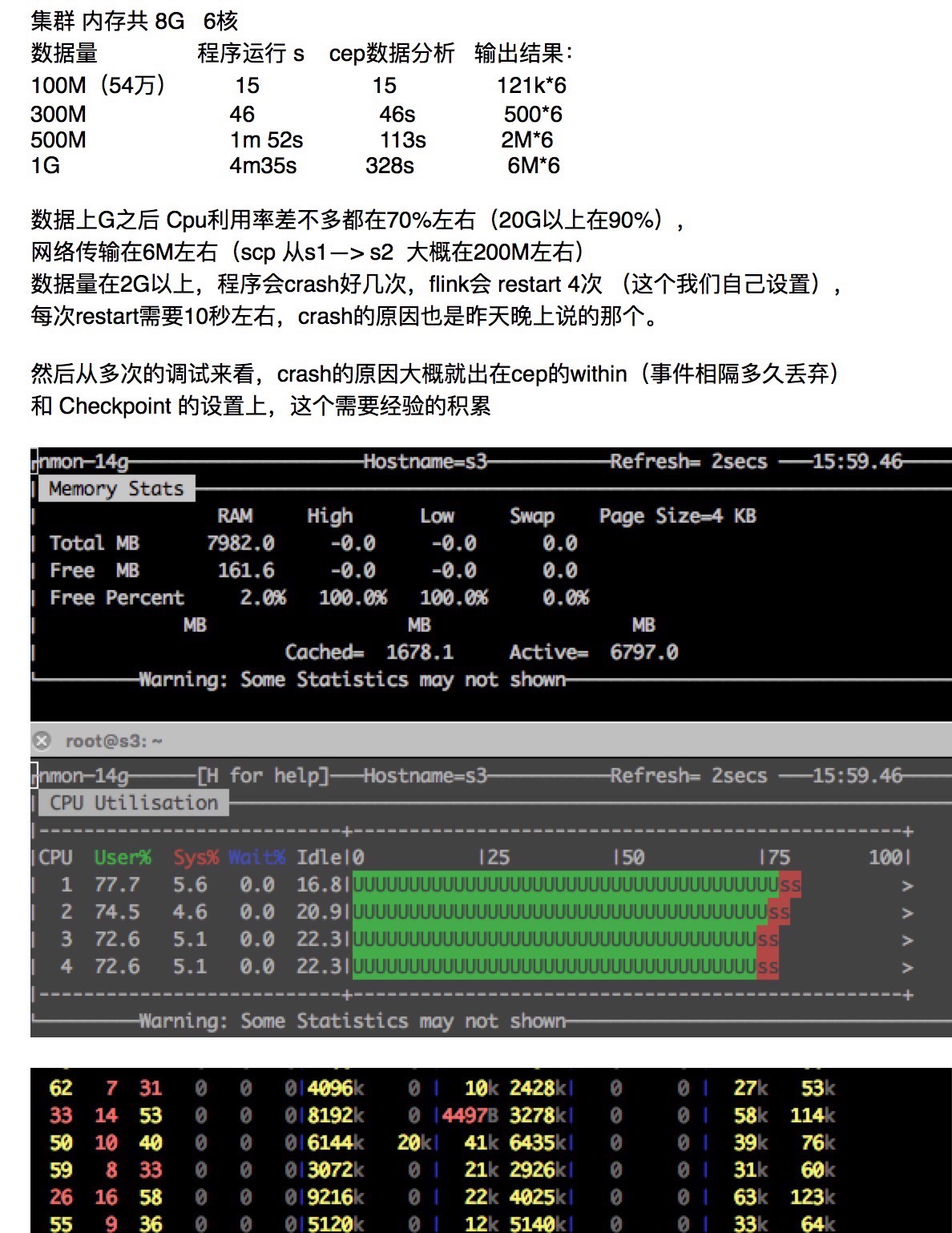
图1
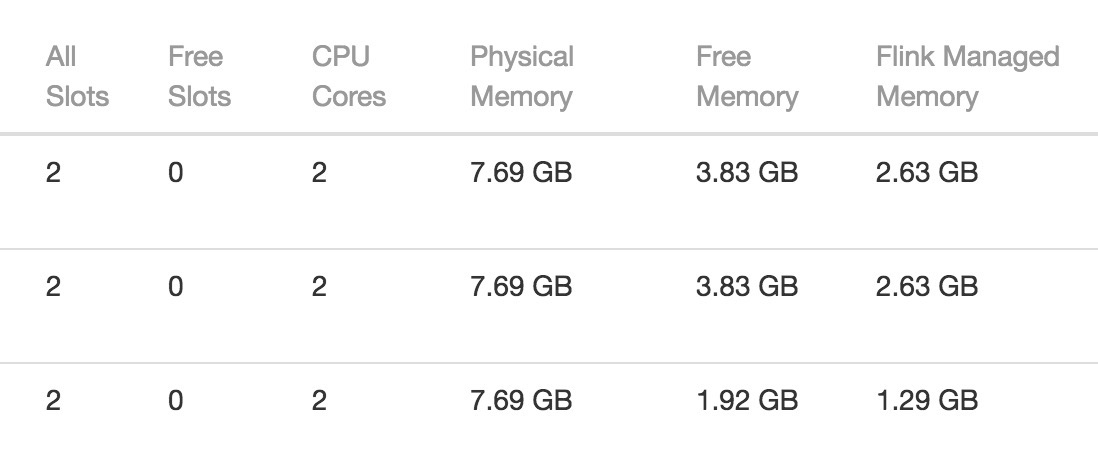
图2
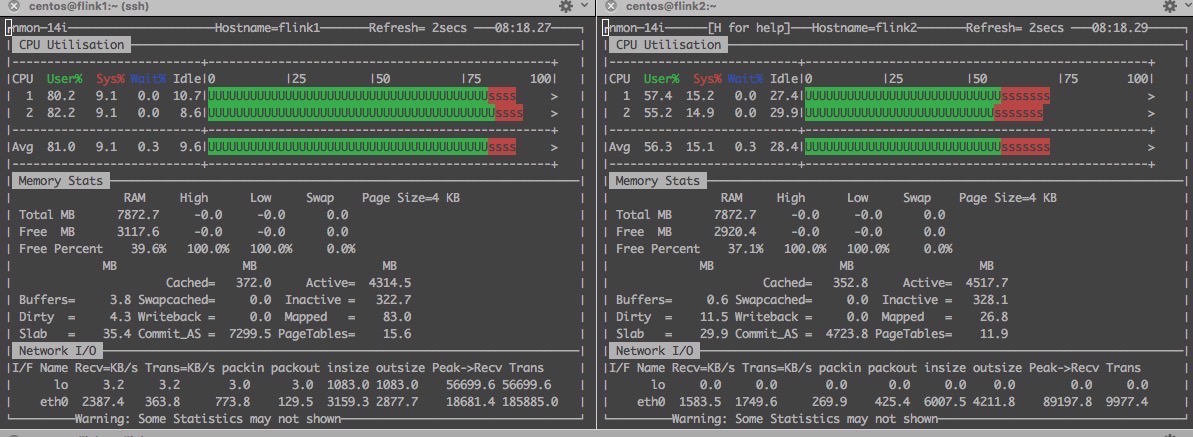
图3:
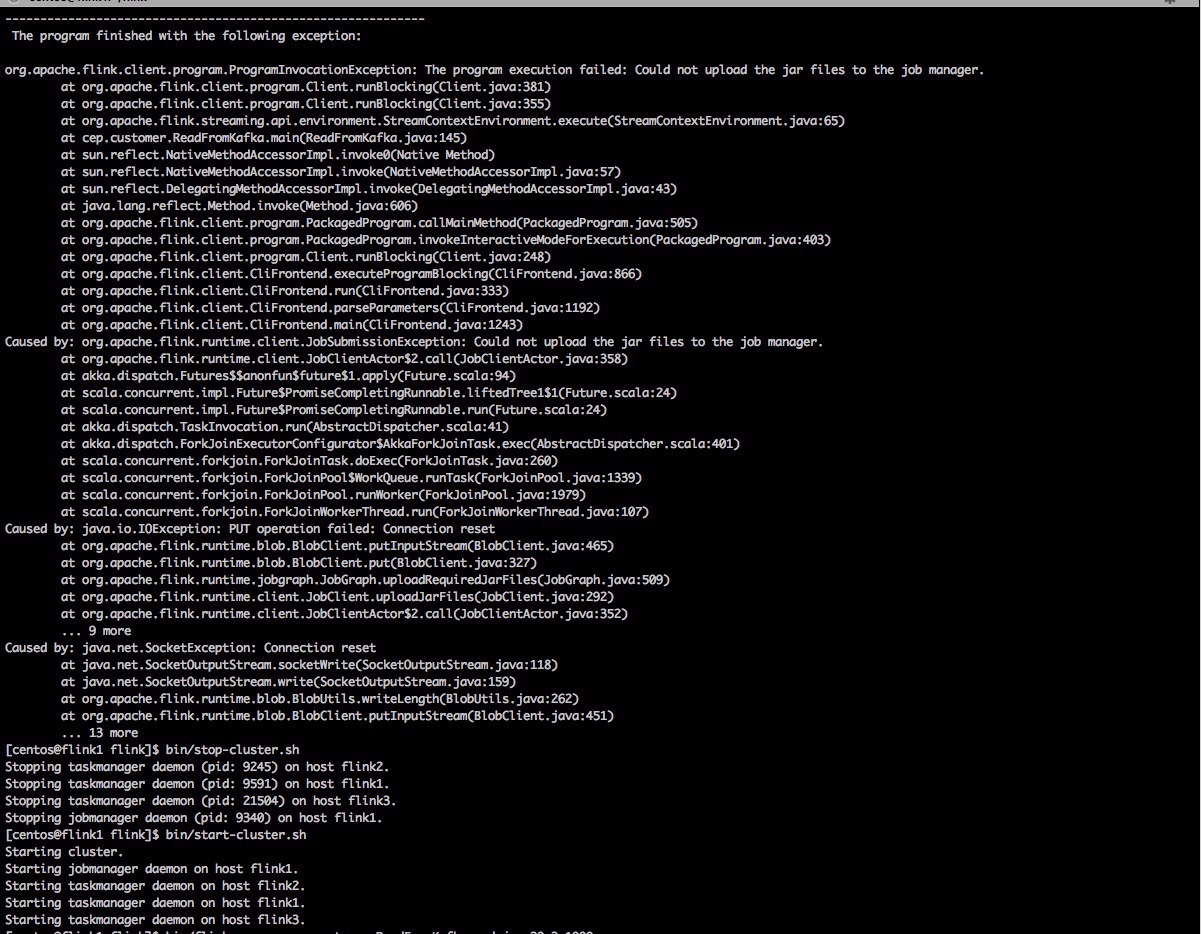
图4:
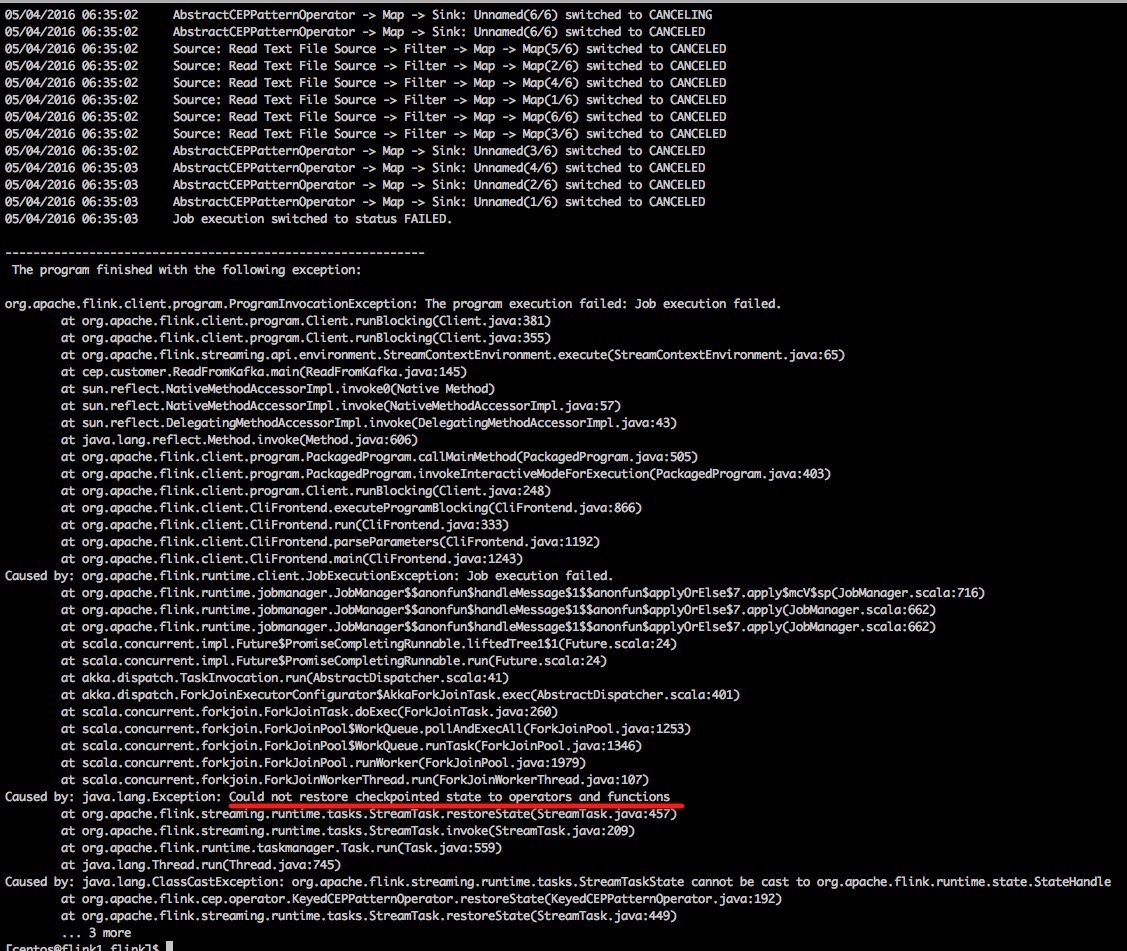
图5:















 246
246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









