







selenium是一个关于爬虫功能python的库,它的整体逻辑与之前的请求爬虫思路不同。selenium是模拟出一个浏览器,你通过代码操作这个浏览器从而获取一些信息,比如执行click()就相当于点击了浏览器中的某个元素,相当于是针对浏览器的鼠标键盘宏
目录
5 获取页面中某个指定的元素 find_elements()
17.1 拖拽 drag_and_drop().perform()
1 安装selenium
pip install selenium

2 连通selenium与浏览器
由于我的谷歌浏览器是最新的,没有匹配我浏览器的驱动,所以未成功。但Edge可以成功
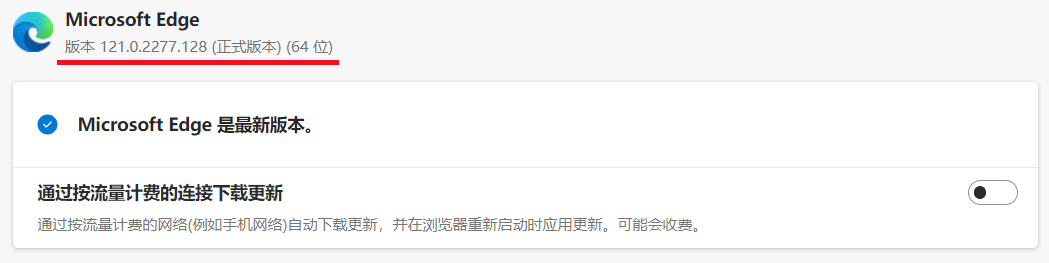
我们先查看当前谷歌浏览器的版本,找到设置


之后在这个链接中下载驱动 ChromeDriver - WebDriver for Chrome - Downloads


驱动号就是浏览器的版本号,但是最新的驱动并没有我们当前浏览器的版本。我们看一下不匹配的情况
下载解压后会得到一个exe,之后增加一个 键位geckodriver,值为驱动的exe路径 的环境变量

然后运行下面这段代码,如果你使用的驱动与浏览器不匹配就会出现这个

selenium目前只支持这四个浏览器,后面的链接是他们的驱动

谷歌浏览器不行我尝试使用Edge

运行前我没有进行任何配置,并且我的Edge是最新版本

运行代码后发现会自动弹出Edge并访问百度

我后面又换了一个机器,再次使用相同的代码发现不能直接使用Edge,我们进入提示的链接中 Unable to Locate Driver Error | Selenium

向下滚动页面下载Edge的驱动

点击后进入到 Microsoft Edge WebDriver | Microsoft Edge Developer 中


这里是要跟你的版本对应,一般来讲都是最新对最新
下载后会得到一个压缩包

解压后会得到exe

把这个exe的路径放到环境变量中,我这里说一下win11添加环境变量的方法。右键此电脑然后点击属性

点击高级系统设置
下面就和win10一样了


驱动不能与代码在同一个路径下,如果在了就会出问题



不需要重新启动就可以连通浏览器了

3 获取网页的内容 page_source



page_source是所有的html数据,可以通过xpath对html操作拿到html的部分数据
4 手动关闭浏览器 quit()
默认情况下执行代码后自动关闭,也可以使用quit()提前关闭

这样打开浏览器10s后关闭浏览器
使用quit()后就不能再使用browser的方法了,如果使用就会报错
5 获取页面中某个指定的元素 find_elements()
可以使用标签名,类名,ID这些信息来找。XPATH相对来说更方便

比如我现在想找百度首页的输入框

那么我赋值这个输入框的xpath,然后这样写
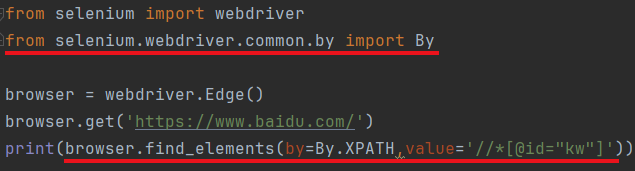
- 如果使用find_element可以找到相关的第一个元素
find_elements会返回一个列表,列表里是所有相关的元素

6 在输入框中输入内容 send_keys()

- 不加time.sleep()就直接关闭了,不好截图

7 点击指定的按钮 click()
- double_click是点两下。context_click()是右键点击。这两个用的比较少,我没有验证过
比如我想点这个按钮



8 执行js代码 execute_script
我们执行向下滚动的代码 window.scrollTo(0,document.body.scrollHeight)
- 有的网页需要向下滚动才能刷新出来一部分内容
在滚动前需要等待一会儿,要不还没加载就开始滚了,那样看不出来效果
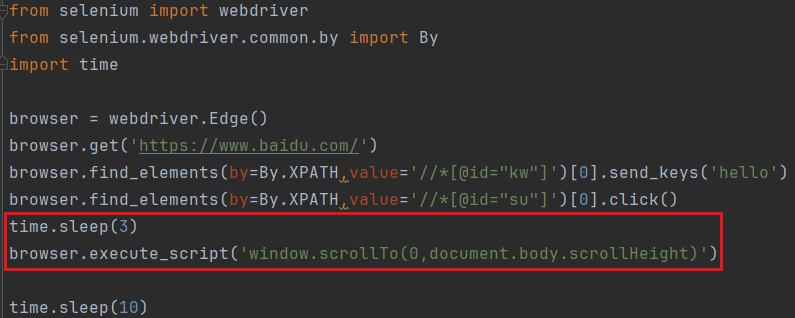
发现可以进行滚动

9 回退 back()
我现在想点击完毕后再退回百度首页

发现可以成功回退

10 前进 forward()
回退之后再回到搜索hello的页面
发现可以成功前进

11 iframe切换 switch_to.frame()
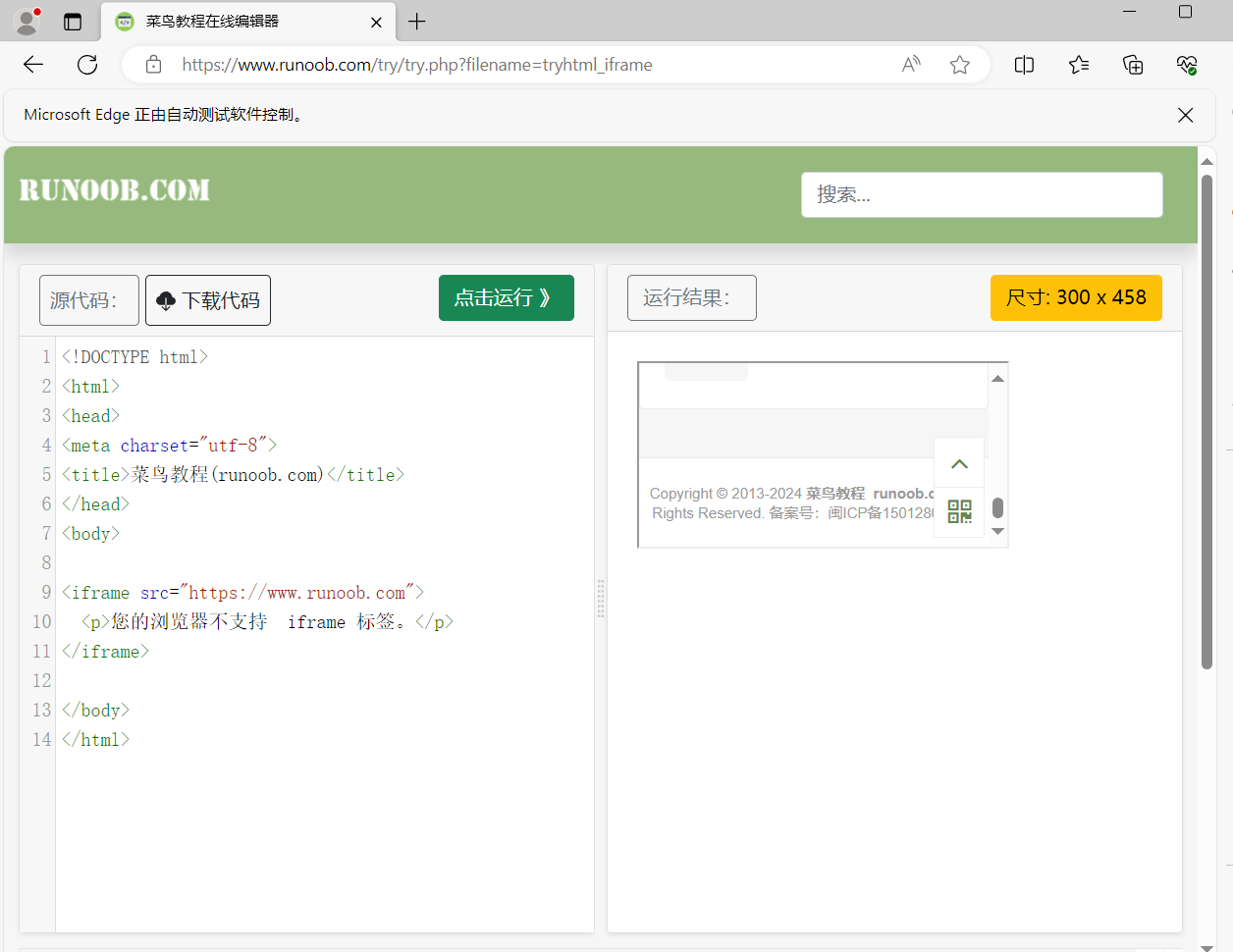
在这个网页中有iframe,我想滚动这个iframe的滚动条

我们看一下结构,这里嵌套了两层iframe

所以我们这样写代码,首先根据ID切换到第一级iframe,然后通过索引(第一级下的第0个iframe)找到第二个iframe

发现可以滚动
- 切换iframe的时间会稍微长一点
12 无可视化浏览器
- 无可视化浏览器也叫无头浏览器
- phantomJs也是selenium中做无头浏览器的一种写法
当我们只关心爬取到的数据而不需要爬取过程的时候,我们可以选择不打开浏览器
我们对options进行设置就可以在不打开浏览器的状态下执行爬取动作了

13 获取元素左上角坐标 location
比如我现在想得到这个图像的左上角坐标

获取元素后调用location属性

14 获取元素的长和宽 size
依然以这个图片为例

获取元素成功后可调用size属性

15 截图 save_screenshot()



我们这样截出来的图是局部的,因为浏览器并没有放到最大,如果想截图全部内容,我们需要在截图前最大化浏览器

这样我们就能获得全部内容了

如果获取到元素的location与size,我们就可以在整体截图的基础上进行局部截图,在进行截图前必须讲显示比例调整到100%,不然截取出来的图像位置不对


可以成功截取指定区域的图像

16 反反爬策略
试了一下没用

17 动作链 ActionChains
17.1 拖拽 drag_and_drop().perform()
在这个网站中 HTML5 拖放 - 菜鸟教程 可以把图像从左边拖到右边
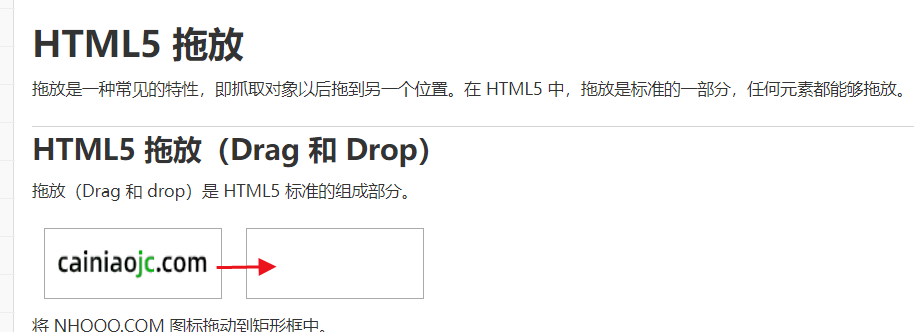

- perform()表示让动作链立即执行
- action.release()表示释放动作链,也就关闭动作链
发现可以从左边拖到右边

17.2 点击后长按然后拖拽然后松开鼠标
我现在想拖拽这个灰色的方块

click_and_hold()是按下去并保持按下去的状态。move_by_offset()是根据像素移动,第一个参数是要移动的x轴像素,第二个参数是要移动的y轴像素

发现可以连续移动5次

17.3 根据指定元素将鼠标移动到相对位置然后点击
进入 图片点选验证码_图片验证码_验证码接口_在线体验_网易易盾 后点击嵌入式,然后点击验证码的图像(0,0)点之后点击图像的(50,50)点

element就是验证码图像的元素。move_to_element_with_offset()是移动到元素的相对位置。click()是点击

发现可以成功点击
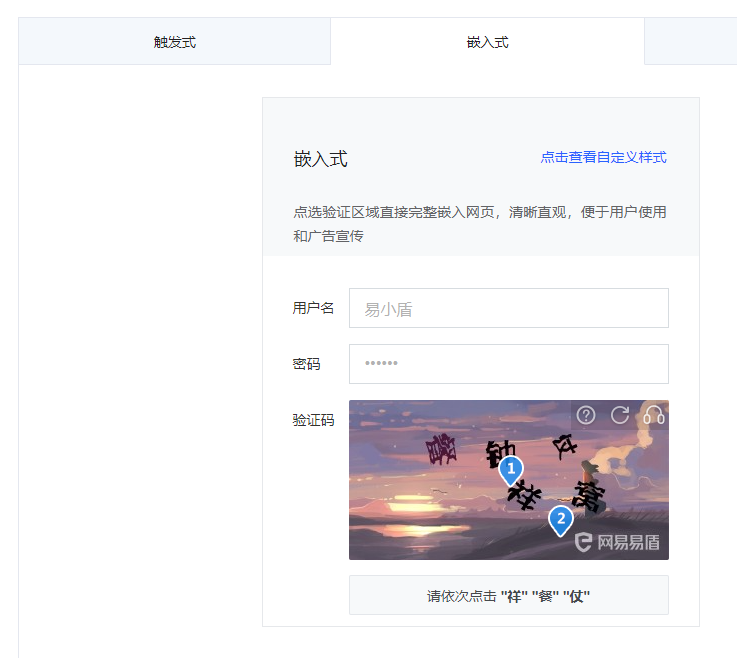
- (0,0)点是元素的中点,后面的偏置也是根据重点来说的















 943
943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











