






写在前面
本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除!
目的

加密字段——anti_content
从下列的图片可以发现anti_content被加密了

断点
搜索大法搜索anti_content字段

可以发现只有一处,直接进去
将断点打到下图位置

进去Object(x,a)函数

进去y函数
继续按照下图打断点

再进去n.messagePackSync函数
可以发现函数被混淆了,不用慌,按照下图端点继续打


按照箭头所指的ct在控制台输出就找到加密函数入口位置

扣代码
进去ct函数发现套了ob,仔细发现可以发现该字段失效的原因就是因为时间的缘故,下图三个箭头所指的位置就是利用时间戳进行加密出来的数组。

可以仔细的对三个变化的数组进行追栈,模拟加密过程。
然后模拟完加密过程之后来到下图位置

由于这个函数是从webpack出来的,纯扣太费时间,于是利用webpack的方式导出。这个函数是在5号,除此之外还需要下图的函数
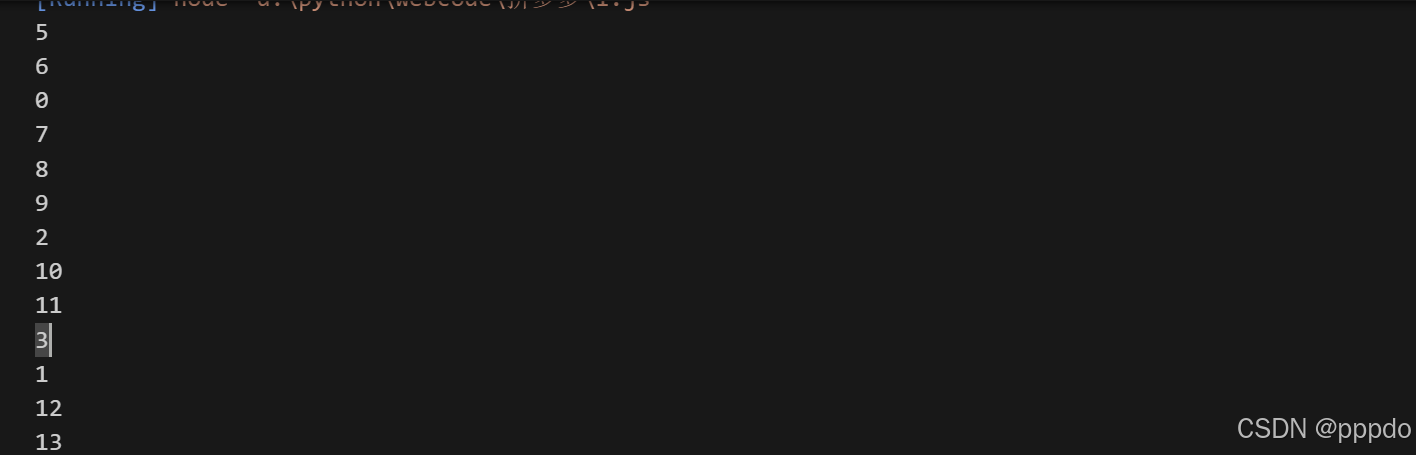
附上分发器代码
var aaa;
!function(e) {
var t = {};
function r(n) {
if (t[n])
return t[n].exports;
var o = t[n] = {
i: n,
l: !1,
exports: {}
};
console.log(n)
return e[n].call(o.exports, o, o.exports, r),
o.l = !0,
o.exports
}
aaa = r;
}({})
然后按照上图的序号找齐函数就可以运行了。如果是ob混淆可以通过控制台手动还原,也可以AST进行还原。将三个变化的加密数组加密函数找齐,webpack的函数找齐,就成功了。
效果图
anti_content加密结果如下

运行结果如下
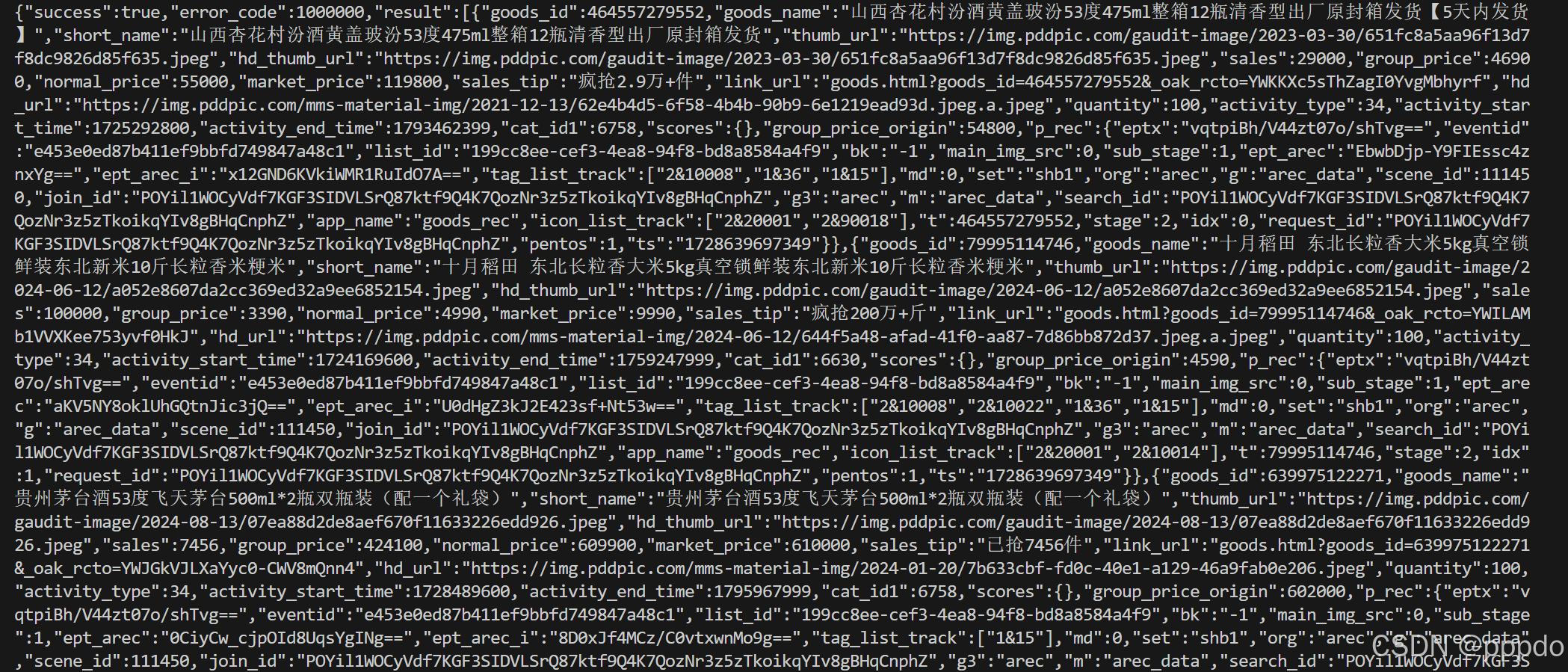
成功获取到商品列表。

















 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









