






一、GPU基本信息
1.查看cuda是否可用:torch.cuda.is_available()
>>>importtorch
>>>torch.cuda.is_available()True
2.查看gpu数量:torch.cuda.device_count()
>>>torch.cuda.device_count()
33.查看gpu名字,设备索引默认从0开始:torch.cuda.get_device_name(0)
>>>torch.cuda.get_device_name(0)
'Tesla P40'4.当前设备索引:torch.cuda.current_device()
>>>torch.cuda.current_device()
05.查看gpu的内存使用情况:nvidia-smi
每隔1s刷新一次gpu使用情况:watch -n 1 nvidia-smi
此时退出Python,直接在开发机上输入上述命令即可:
(bert) [op@algo src]$ nvidia-smi
Thu Nov 5 21:52:32 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.129 Driver Version: 410.129 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P40 Off | 00000000:03:00.0 Off | 0 |
| N/A 25C P8 11W / 250W | 0MiB / 22919MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla P40 Off | 00000000:04:00.0 Off | 0 |
| N/A 26C P8 10W / 250W | 0MiB / 22919MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla P40 Off | 00000000:84:00.0 Off | 0 |
| N/A 24C P8 9W / 250W | 0MiB / 22919MiB | 0% Default |
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
(bert) [op@algo src]$
(bert) [op@algo src]$
(bert) [op@algo src]$
(bert) [op@algo src]$ watch -n 1 nvidia-smi
### 出现上述界面,只是每1s刷新一次GPU使用情况。二、代码中,如何设定使用哪张GPU
1.单卡的时候,没有选择余地,就一张。
2.多卡的时候,分两种情况,一个是数据并行,多张卡一起工作;另一个是只在一张卡上运行,比如由4张卡[0, 1, 2, 3],我想在卡1上运行任务。
情况一:数据并行
#配置device_ids,选择你想用的卡编号。
device_ids= [0, 1, 2]
iftorch.cuda.device_count() >1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model=torch.nn.DataParallel(model, device_ids)此时的gpyu使用情况:
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 19272 C python 9009MiB |
| 1 19272 C python 5753MiB |
| 2 19272 C python 5753MiB |
| 3 19272 C python 5755MiB |
+-----------------------------------------------------------------------------+模型的结构默认就是在device_ids[0],即第一块卡上,也就解释了为什么第一块卡的显存会占用的比其他卡要更多一些。进一步说也就是当你调用nn.DataParallel的时候,只是在你的input数据是并行的,但是你的output loss却不是这样的,每次都会在第一块GPU相加计算,这就造成了第一块GPU的负载远远大于剩余其他的显卡。
情况二:一张卡上运行
类似tensorflow指定GPU的方式,使用CUDA_VISIBLE_DEVICES
1.1 直接终端中设定:
CUDA_VISIBLE_DEVICES=1 python main.py1.2 python代码中设定:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "2"使用函数 set_device
importtorch
torch.cuda.set_device(id)分布式运行训练程序的问题
8881服务器上四张卡已经有一张再跑,想要只使用1,2,3号卡
此处为多显卡训练设置
os.environ["CUDA_VISIBLE_DEVICES"] = "1,2,3"
device_ids = [1,2,3]
model = nn.DataParallel(model, device_ids) # multi-gpu training运行时报错:
RuntimeError: module must have its parameters and buffers on device cuda:1 (device_ids[0]) but found问题就出在device处,因为下面这条语句,默认将模型放在了cuda 0上,也就是我们没有使用的显卡0。于是会产生错误
device = torch.device("cuda")修改后成功
device = torch.device("cuda:1")三、结束GPU中进程释放显存
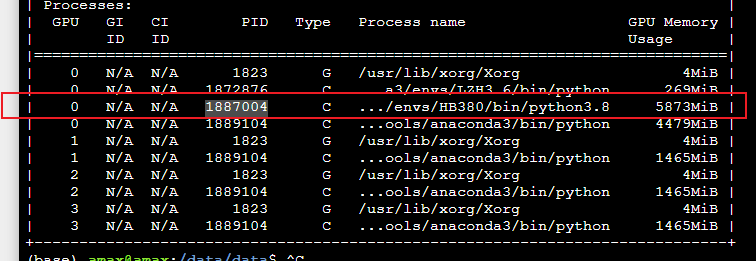
想要结束 1887004 程序进程,释放显存
终端输入 kill -9 1887004

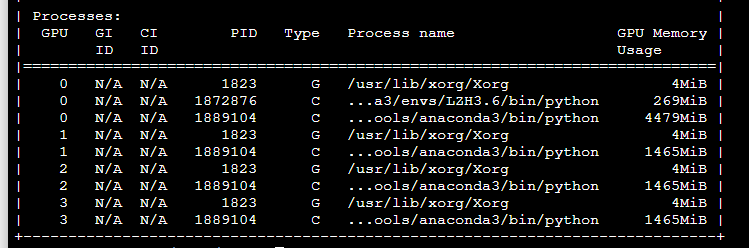
显存以释放
References
https://blog.csdn.net/pearl8899/article/details/109503803?spm=1001.2014.3001.5506















 7698
7698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









