







1. 与哈希函数有关的结构
哈希函数和哈希表
1.1 哈希函数的特征:
- 哈希函数:输入域无穷,输出域有限,
MD5 返回值 0~ 2 64 − 1 2^{64}-1 264−1,返回值长度为16的字符串
sha1 返回值 128 - 相同的输入参数一定会返回相同的输出值,哈希函数没有任何的随机成分。
- 不同的输入也有可能导致相同的输出 (哈希碰撞)
- 具有均匀性和离散性
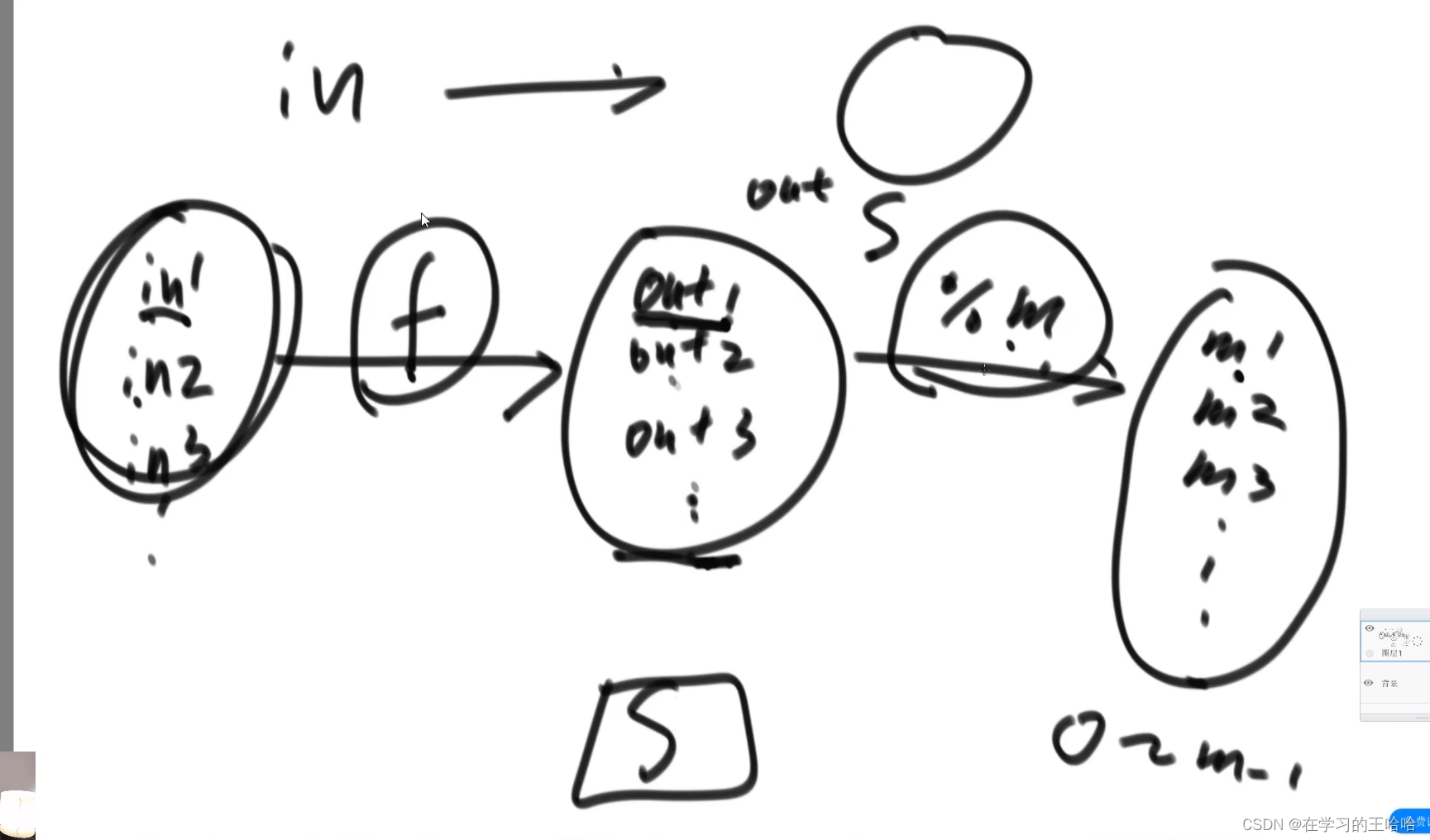
1.1 出现次数最多的数是哪个
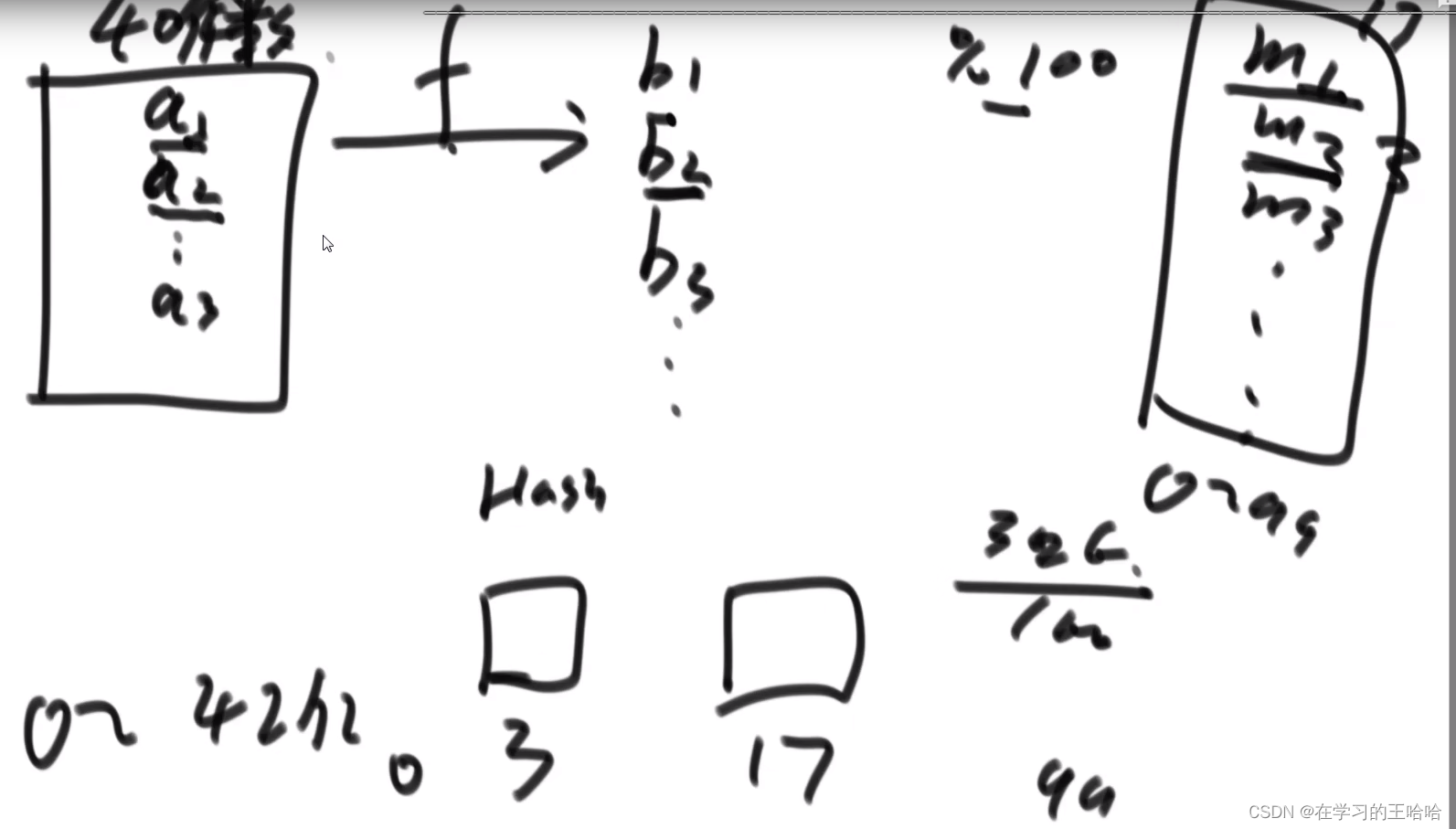
有40亿个无符号整数, 其范围为:0~ 2 32 − 1 2^{32}-1 232−1,0 ~ 42亿,在1G内存中计算出现次数最多的数是哪个?
int:4字节,
value:4字节
哈希表至少需要8字节,
40亿 * 8 字节 需要320亿字节,也就是32G空间
同样的数就是一条数据。
我们就可以使用哈希函数,针对40亿个无符号整数调哈希函数,然后100去余。放到对应的文件中,然后针对文件中的数放入各自的哈希表中,32G/100,
利用了哈希函数在种类上均分了,小文件放在了硬盘上,使用完一个文件就释放了
1.2 哈希表的具体实现
增删改查都是o(1)的
链地址法
字符串经过哈希函数,然后进行模运算
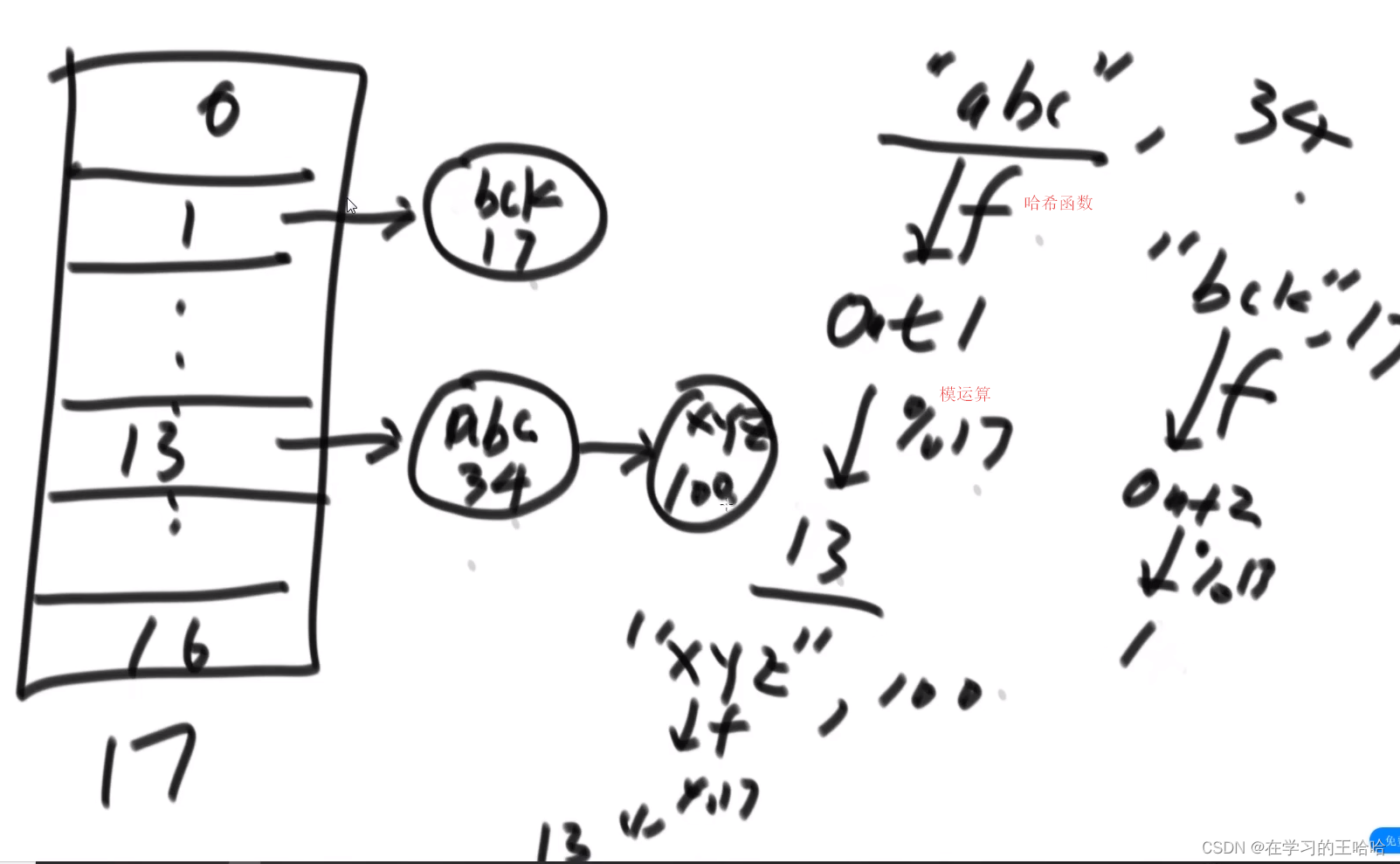
怎么加进去的就怎么找。
由于哈希函数的均匀性,所有链表长度都是均匀增长的。
链表长度一旦超过6,就扩容。
模17增加为模34。
如果加入了N个字符串,经历了 logN次(最差情况,长度超过2就扩容)的扩容。总的代价是 O(N * logN)
离线扩容技术:不占用户的在线时间,jvm中进行扩容。
1.3 设计RandomPool结构

准备两张hash表,一张str->index , 另一张index->str。

package class01;
import java.util.HashMap;
public class Code02_RandomPool {
public static class Pool<K> {
private HashMap<K, Integer> keyIndexMap;
private HashMap<Integer, K> indexKeyMap;
private int size;
public Pool() {
this.keyIndexMap = new HashMap<K, Integer>();
this.indexKeyMap = new HashMap<Integer, K>();
this.size = 0;
}
public void insert(K key) {
if (!this.keyIndexMap.containsKey(key)) {
this.keyIndexMap.put(key, this.size);
this.indexKeyMap.put(this.size++, key);
}
}
public void delete(K key) {
if (this.keyIndexMap.containsKey(key)) {
int deleteIndex = this.keyIndexMap.get(key);
int lastIndex = --this.size;
K lastKey = this.indexKeyMap.get(lastIndex);
this.keyIndexMap.put(lastKey, deleteIndex);
this.indexKeyMap.put(deleteIndex, lastKey);
this.keyIndexMap.remove(key);
this.indexKeyMap.remove(lastIndex);
}
}
public K getRandom() {
if (this.size == 0) {
return null;
}
int randomIndex = (int) (Math.random() * this.size); // 0 ~ size -1
return this.indexKeyMap.get(randomIndex);
}
}
public static void main(String[] args) {
Pool<String> pool = new Pool<String>();
pool.insert("zuo");
pool.insert("cheng");
pool.insert("yun");
System.out.println(pool.getRandom());
System.out.println(pool.getRandom());
System.out.println(pool.getRandom());
System.out.println(pool.getRandom());
System.out.println(pool.getRandom());
System.out.println(pool.getRandom());
}
}
1.4 布隆过滤器
100亿url黑名单,每个url 64字节,目的:方便查询,不支持删。
布隆过滤器:只有加入和查询,接受一定程度的失误率(允许错杀,不会放过)。
1.4.1 位图bitmap
4 bytes = 32bit
package com.wanghaha.algorithm;
public class Day6_30_44BitMap {
public static void main(String[] args) {
int[] arr = new int[10]; // 32 * bit * 10 -> 320 bits
// arr[0] int 0 ~ 31
// arr[1] int 32 ~ 63
// arr[2] int 64 ~ 95
int i = 178; //想取得178个bit的状态
int numIndex = 178 / 32;
int bitIndex = 178 % 32; // int中的第几位
int s = (( arr[numIndex] >> (bitIndex)) & 1);
// 请把178位的状态 改成1;
arr[numIndex] = arr[numIndex] | ( 1<< (bitIndex));
// 请把178位的状态改成 0
i = 178;
arr[numIndex] = arr[numIndex] & (~(1 << bitIndex));
// 请把178位的状态拿出来
i = 178;
int bit = (arr[i / 32] >> (i%32)) & 1;
}
}
1.4.2 布隆过滤器的实现
就是一个大的位图,m个bit
u1 通过哈希函数f1 然后模m 将对应的位图上的格子置位1。
经过k个哈希函数,对应的格子置为1。
然后u2, u3等,一直到 第100亿个u。
最后布隆过滤器版本的黑名单做好了。
然后查url,经过k个哈希函数,只有全是1的时候,该url就在黑名单里。
需要条件: n样本量,p失误率
单样本大小无关。
确定空间(向上取整):
m = − ( n ∗ l n P ) ( I n 2 ) 2 m=-\dfrac{(n*lnP)}{(In2)^2 } m=−(In2)2(n∗lnP)
算出哈希函数个数(向上取整):
k = l n 2 ∗ m n ≈ 0.7 ∗ m n k=ln2*\dfrac{m}{n}\thickapprox 0.7*\dfrac{m}{n} k=ln2∗nm≈0.7∗nm
实际的失误率
P 真 = ( 1 − e − (
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1495
1495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









