1.混淆矩阵

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mCQO5e8U-1648050818829)(attachment:image.png)]](https://i-blog.csdnimg.cn/blog_migrate/fcd55fdf505989b9d893cb7ffdbbe168.png)
2. 导入数据
from sklearn.datasets import load_iris
iris = load_iris()
两分法拆分数据
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size = 0.3,random_state=666)
构建决策树模型
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier()
dt.fit(x_train,y_train)
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False,
random_state=None, splitter='best')
dt.predict(x_test)
array([1, 2, 1, 2, 0, 1, 1, 2, 1, 1, 1, 0, 0, 0, 2, 1, 0, 2, 2, 2, 1, 0,
2, 0, 1, 1, 0, 1, 2, 2, 0, 0, 1, 2, 1, 1, 2, 2, 0, 1, 2, 2, 1, 1,
0])
from sklearn.metrics import classification_report
print(classification_report(y_test,dt.predict(x_test)))
precision recall f1-score support
0 1.00 1.00 1.00 12
1 1.00 1.00 1.00 18
2 1.00 1.00 1.00 15
accuracy 1.00 45
macro avg 1.00 1.00 1.00 45
weighted avg 1.00 1.00 1.00 45
输出训练集上的混淆矩阵
from sklearn.metrics import confusion_matrix
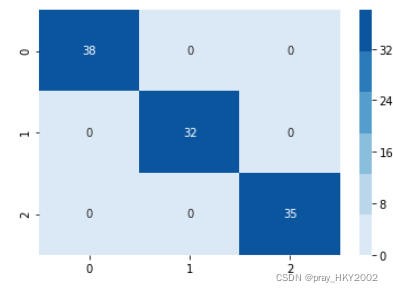
cm = confusion_matrix(y_train,dt.predict(x_train))
cm
array([[38, 0, 0],
[ 0, 32, 0],
[ 0, 0, 35]], dtype=int64)
confusion_matrix(y_train,dt.predict(x_train),labels=[2,1,0])
array([[35, 0, 0],
[ 0, 32, 0],
[ 0, 0, 38]], dtype=int64)
用热力图展示混淆矩阵
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
sns.heatmap(cm,cmap=sns.color_palette("Blues"),annot=True)
<matplotlib.axes._subplots.AxesSubplot at 0x147887cb710>
分类结果汇总

from sklearn.metrics import classification_report
a = classification_report(y_train,
dt.predict(x_train),
digits=3,
labels=[2,1,0],
target_names=['第2类','第1类','第0类'],
output_dict=False)
print(a)
precision recall f1-score support
第2类 1.000 1.000 1.000 35
第1类 1.000 1.000 1.000 32
第0类 1.000 1.000 1.000 38
accuracy 1.000 105
macro avg 1.000 1.000 1.000 105
weighted avg 1.000 1.000 1.000 105
3. ROC曲线

from sklearn.metrics import roc_curve
import numpy as np
y_true = np.array([1,1,0,1,1,0,0,0,1,0])
y_score = np.array([0.9,0.8,0.7,0.6,0.55,\
0.54,0.53,0.51,0.50,0.40])
fpr,tpr,thresholds = roc_curve(y_true,y_score)
print(fpr,tpr,thresholds,sep='\n')
[0. 0. 0. 0.2 0.2 0.8 0.8 1. ]
[0. 0.2 0.4 0.4 0.8 0.8 1. 1. ]
[1.9 0.9 0.8 0.7 0.55 0.51 0.5 0.4 ]
fpr1,tpr1,thresholds1 = roc_curve(y_true,
y_score,
drop_intermediate = False)
print(fpr1,tpr1,thresholds1,sep='\n')
[0. 0. 0. 0.2 0.2 0.2 0.4 0.6 0.8 0.8 1. ]
[0. 0.2 0.4 0.4 0.6 0.8 0.8 0.8 0.8 1. 1. ]
[1.9 0.9 0.8 0.7 0.6 0.55 0.54 0.53 0.51 0.5 0.4 ]
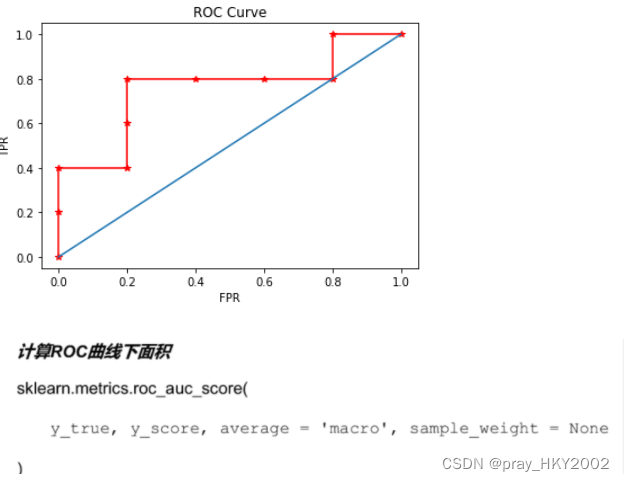
plt.plot(fpr1,tpr1,'r*-')
plt.plot([0,1],[0,1])
plt.xlabel("FPR")
plt.ylabel("TPR")
plt.title("ROC Curve")
Text(0.5, 1.0, 'ROC Curve')
from sklearn.metrics import roc_auc_score
roc_auc_score(y_true,y_score)
0.76
4.召回率与精度


import numpy as np
from sklearn.metrics import precision_recall_curve
y_true = np.array([0,0,0,0,0,1,1,1,1,1])
y_scores = np.array([0.1,0.2,0.25,0.4,0.6,0.2,0.45,0.6,0.75,0.8])
precision ,recall,thresholds = precision_recall_curve(y_true,y_scores)
len(precision),len(recall),len(thresholds)
(8, 8, 7)
thresholds
array([0.2 , 0.25, 0.4 , 0.45, 0.6 , 0.75, 0.8 ])
precision
array([0.55555556, 0.57142857, 0.66666667, 0.8 , 0.75 ,
1. , 1. , 1. ])
recall
array([1. , 0.8, 0.8, 0.8, 0.6, 0.4, 0.2, 0. ])
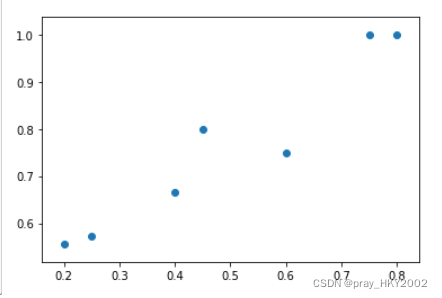
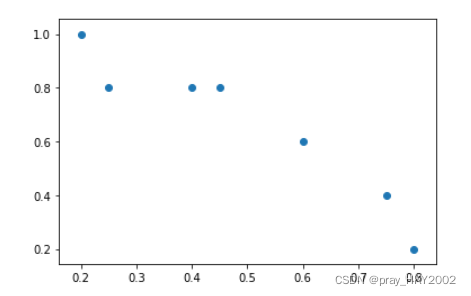
plt.scatter(thresholds,precision[:-1])
<matplotlib.collections.PathCollection at 0x14788aadd68>
plt.scatter(thresholds,recall[:-1])
<matplotlib.collections.PathCollection at 0x14788b0ce10>
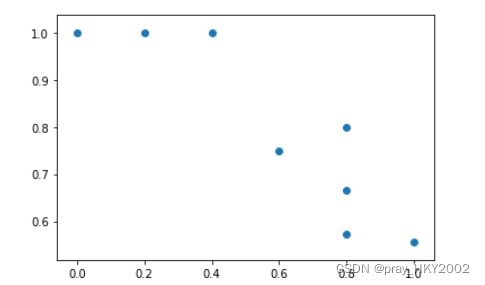
plt.scatter(recall,precision)
<matplotlib.collections.PathCollection at 0x14788b78160>
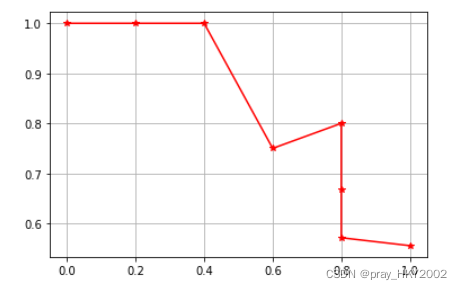
plt.plot(recall,precision,'r-*')
plt.grid()
from sklearn.preprocessing import binarize
y = binarize(iris.target.reshape(-1,1))

from sklearn.metrics import average_precision_score
average_precision = average_precision_score(y_true,y_scores)
average_precision
0.8211111111111111
5.F1分数

from sklearn.metrics import f1_score
from sklearn.neural_network import MLPClassifier
mlp = MLPClassifier()
mlp.fit(iris.data,iris.target)
MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(100,), learning_rate='constant',
learning_rate_init=0.001, max_iter=200, momentum=0.9,
n_iter_no_change=10, nesterovs_momentum=True, power_t=0.5,
random_state=None, shuffle=True, solver='adam', tol=0.0001,
validation_fraction=0.1, verbose=False, warm_start=False)
f1_score(iris.target,mlp.predict(iris.data),average='micro')
0.98
f1_score(iris.target,mlp.predict(iris.data),average='macro')
0.9799819837854069
f1_score(iris.target,mlp.predict(iris.data),average='weighted')
0.9799819837854068






















 537
537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









