







一、transformer
也就是encoder-decoder with attention的结构,
参考:
attentnion is all you need:https://arxiv.org/abs/1706.03762
【NLP】Transformer模型原理详解:https://zhuanlan.zhihu.com/p/44121378
详解Transformer (Attention Is All You Need):详解Transformer (Attention Is All You Need) - 知乎
个人理解:
1. 为什么用attention而不是rnn或者cnn
rnn不能并行计算,cnn卷积核只能考虑部分单元(虽然最后也能考虑全局),attention是一种巧妙的设计,将每个位置的输入转换为q,k,v,这样计算出来的输出考虑的全局的注意力,并且参数比较少,只需要学习Wq,Wk,Wv矩阵
2. decoder和encoder区别,以及decoder的解码过程
参考:举个例子讲下transformer的输入输出细节及其他 - 知乎
decoder比encoder多了一个encoder-decoder attention,
训练的时候:
decoder的输入是6层的encoder输出的K和V+decoder应该输出序列Q(mask矩阵),从而实现并行计算。
这个地方一个疑问: decoder是需要上一个序列的输入的,如何实现并行计算

为什么说训练可以并行,因为训练本质上是要计算输入*参数矩阵的输出和实际输出的error,而这个,因为实际输出是知道的,每个位置的error对应的输入序列也是确定的,所以可以并行解决
预测的时候:
decoder输入是6层的encoder输出的K和V+decoder应该输出序列的前t-1个值,非并行的多次迭代,直到预测出<eos>标签就停止
3. 传统seq2seq模型参考
seq2seq模型详解及对比(CNN,RNN,Transformer) - 微笑sun - 博客园
二、 bert源码解读
bert一般是12层网络,512的序列,每个token是768维的向量
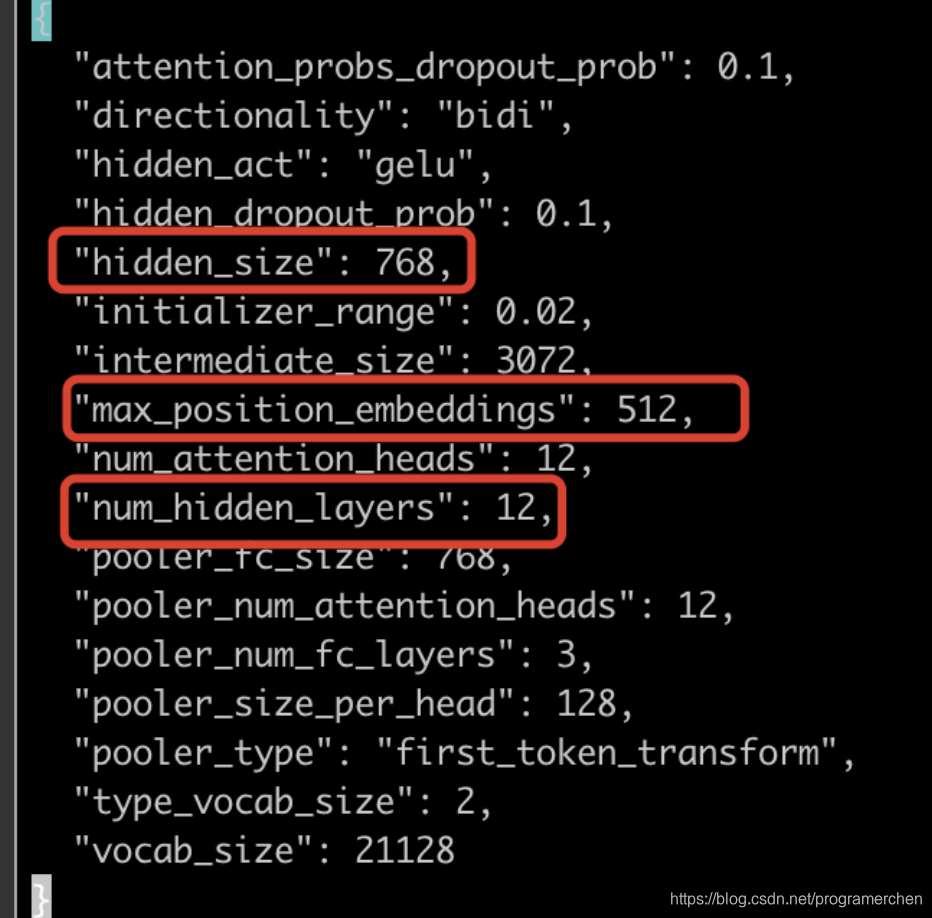
假设batch_size=16,max_seq_len=128:
输出层维度

假设labels维度是112

embeding层
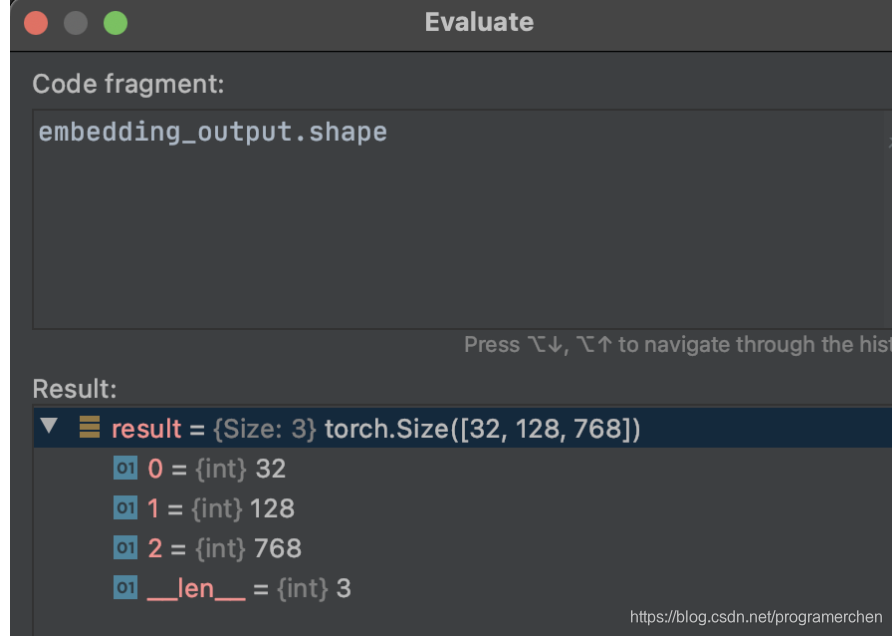
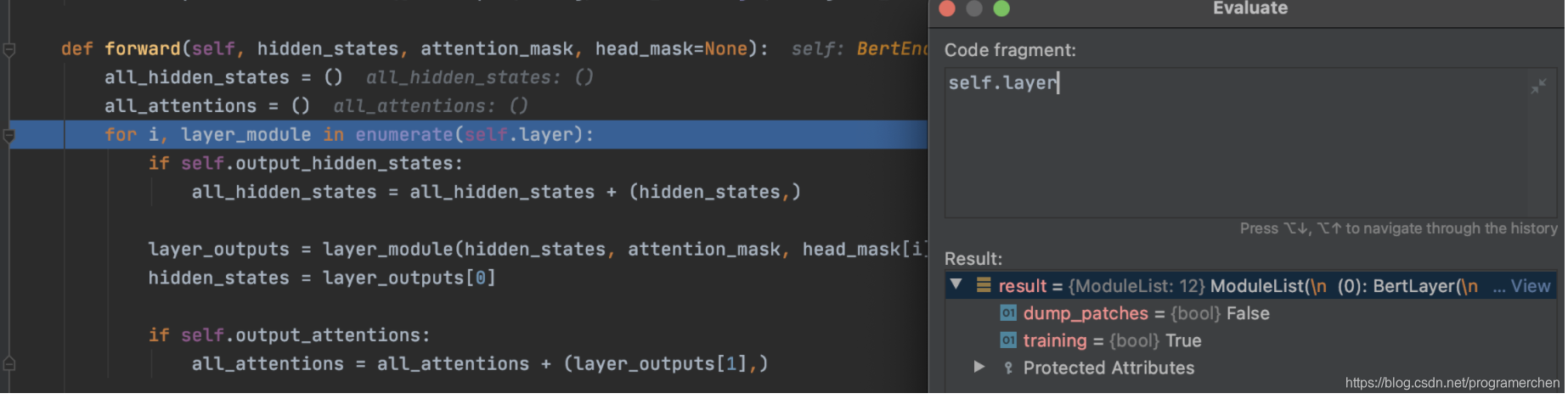
encoder12层
每层每一层的BertLayer进行的操作如下,接一个attention+intermediate+output+整合:
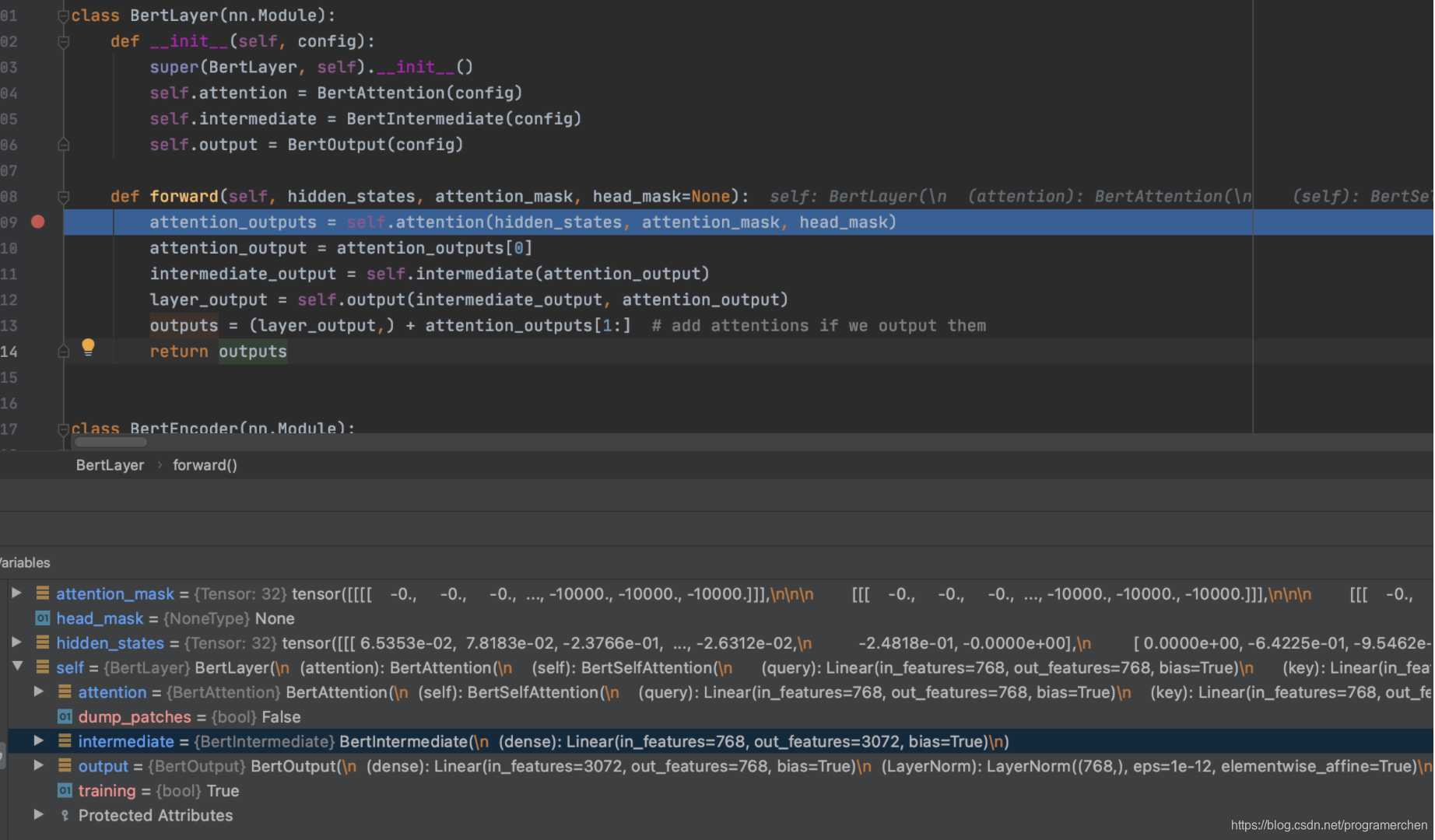
每一层输出也是128*768


















 3981
3981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









