






前言
只是个人的一个简单练习,不保证代码的正确性,如有错误欢迎指出,代码结构参考其它博客以及慕课网的内容,如有侵权请私聊.
协同过滤算法
协同过滤算法主要分为两种,一种是基于用户(user)推荐的协同过滤,一种是基于物品(item)的协同过滤,基于user的协同过滤就是找到相似的用户B,然后推荐B用户喜欢的但是当前用户没有喜欢的item给当前用户.基于item的协同过滤就是找到当前用户喜欢的item相似的item,然后把这些item推荐给当前用户.
基于用户的协同过滤
计算用户的相似度
计算相似度主要有Jaccard 公式或者余弦相似度公式
Jaccard公式:
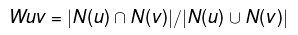
余弦相似度公式:
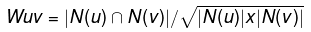
其中N(u)是用户u喜欢的物品集合,N(v)是用户v喜欢的物品集合
根据用户相似度矩阵推荐
找出相似度矩阵中与输入用户相似的前k个用户,构成一个集合S(u,k),将这些用户喜欢的item全部提取出来,去除掉输入用户喜欢的item,计算输入用户对每个item的感兴趣程度
公式为:
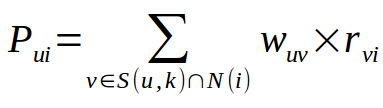
N(i)用户u没有喜欢物品i,Wuv为用户u和用户v的相似度,Rvi表示用户v对i的喜欢程度,这里默认都为1.计算出所有得分后,推荐得分最高的物品.
基于物品的协同过滤
计算物品的相似度
物品i和物品j的相似度计算公式如下:
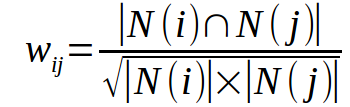
根据物品相似度矩阵推荐
计算用户u对物品j的感兴趣程度公式如下:
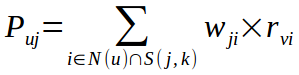
N(u)表示用户u喜欢的物品集合,S(j,k)表示物品j以及与j相似度最高的k个物品的集合,wji是物品i和物品j的相似度,rvi表示用户u对物品i的喜欢程度,这里默认为1.
数据集
这里采用了网上常用的电影数据集,主要用到rating.csv和movies.csv
下载地址
movielens数据集
rating.csv每一行数据包括[userid,itemid,rating,timestamp]
movies.csv每一行数据包括[movieId,title,genres]
读取数据集代码file_reader.py:
import os
import pandas as pd
#需要的数据有item_userlist,user_itemlist,user_list,item_list
def get_data():
data = pd.read_csv("ratings.csv")
l = len(data)
user_itemlist = {}
item_userlist = {}
user_list = []
item_list = []
#print(l)
for i in range(0,l):
i_line = data.iloc[i];#[userid,itemid,rating,timestamp]
if(float(i_line[2])<3.0 or len(i_line)<4):#rating小于3表示user对这个物品并不感兴趣
continue;
if(i_line[0] not in user_itemlist):
user_itemlist[i_line[0]]=[]
user_itemlist[i_line[0]].append(i_line[1])
if(i_line[1] not in item_userlist):
item_userlist[i_line[1]]=[]
item_userlist[i_line[1]].append(i_line[0])
if(i_line[0] not in user_list):
user_list.append(i_line[0])
if(i_line[1] not in item_list):
item_list.append(i_line[1])
return item_userlist,user_itemlist,user_list,item_list;
def get_item_info():#从movies.csv文件中抽取item的详细信息,主要得到item的title和类别
item_info = {}
data = pd.read_csv("movies.csv");
l = len(data)
for i in range(0,l):
i_line = data.iloc[i];
if len(i_line)< 3:#遇到信息不完整行,则过滤
continue
if i_line[0] not in item_info:
item_info[i_line[0]] = [i_line[1],i_line[2]]
return item_info
file_reader.py要放在ratings.csv和movies.csv同一目录下
item_userlist为以itemid为key的字典,value为一个user的list,即喜欢该itemid对应的item的user列表
user_itemlist同item_userlist,是以userid为key的字典,value为一个item的list,即userid对应的user喜欢的item列表
user_list为记录所有userid的列表
item_list为记录所有itemid的列表
基于用户的协同过滤代码
from file_reader import *
import sys
import operator
import math
def cal_user_sim(item_userlist,user_list,user_itemlist):#包括的参数有{item:userlist},即物品和与该物品关联的用户列表字典,应该还需要一个参数user:itemlist,user:itemlist是已知的
sim_map = {}
for itemid,i_user_list in item_userlist.items():
l = len(i_user_list)
for i in range(0,l):
user_i = i_user_list[i] #取出item相关的user的id
for j in range(i,l):
user_j = i_user_list[j] #itemid对应的user_i和user_j的id取出来了
#sim_map为一个二维字典,
sim_map.setdefault(user_i,{})
sim_map[user_i].setdefault(user_j,0)
sim_map[user_i][user_j]+=1
sim_map.setdefault(user_j,{})
sim_map[user_j].setdefault(user_i,0)
sim_map[user_j][user_i]+=1
user_num = len(user_list)
for i in range(0,user_num):
for j in range(0,user_num):#采用余弦相似度
user_i = user_list[i]
user_j = user_list[j]
sim_map.setdefault(user_i,{})
sim_map[user_i].setdefault(user_j,0);
tp = sim_map[user_i][user_j]
if(len(user_itemlist[user_i])!=0 and len(user_itemlist[user_j])!=0):
sim_map[user_i][user_j] /= (len(user_itemlist[user_i])*len(user_itemlist[user_j]))**0.5
return sim_map
def get_result(input_user,sim_map,k,user_itemlist):
input_user_neighbors = sim_map[input_user]
input_user_neighbors_sorted = sorted(input_user_neighbors.items(),key=operator.itemgetter(1),reverse=True)#从大到小
k = len(input_user_neighbors_sorted) if k>len(input_user_neighbors_sorted) else k
input_user_list = user_itemlist[input_user]
Pui={}
for i in range(0,k):#遍历相似度topk的用户
user_nb_i,Wuv = input_user_neighbors_sorted[i];
item_list_i = user_itemlist[user_nb_i];
l = len(item_list_i);
for j in range(0,l):#遍历topk用户的所有喜欢的item
if(item_list_i[j] not in input_user_list):#把不是输入用户喜欢的item加到wait_items中
Pui.setdefault(item_list_i[j],0);
Pui[item_list_i[j]] += sim_map[input_user][user_nb_i];#计算公式
Pui_sorted = sorted(Pui.items(),key=operator.itemgetter(1),reverse = True);
return Pui_sorted[0][0]
if __name__ == "__main__":
item_userlist,user_itemlist,user_list,item_list = get_data();
sim_map = cal_user_sim(item_userlist,user_list,user_itemlist);
item_info = get_item_info();
for i in range(1,101):
recommend = get_result(i,sim_map,5,user_itemlist);
print(i," ",item_info[recommend])
代码文件要放在和ratings.csv,movies.csv,file_reader.py相同的目录中,这里推荐了userid为[1,100]的推荐条目
部分运行结果:

基于物品的协同过滤代码
from file_reader import *
import sys
import operator
import math
#基于item的协同过滤,首先要计算item之间的相似度,计算相似度首先要统计这个item被使用的人数,然后取两个item被使用人数的交集
def cal_item_sim(item_userlist,item_list):
#for itemid,user_list in item_userlist.items():
l = len(item_list)
sim_map = {}
for i in range(0,l):
for j in range(0,l):
user_list_i = item_userlist[item_list[i]]
user_list_j = item_userlist[item_list[j]]
Ni = len(user_list_i)
Nj = len(user_list_j)
user_list_ij = [user for user in user_list_i if user in user_list_j]
lij = len(user_list_ij)
sim_map.setdefault(item_list[i],{});
sim_map.setdefault(item_list[j],{});
sim_map[item_list[i]].setdefault(item_list[j],0)
sim_map[item_list[j]].setdefault(item_list[i],0)
if(Ni!=0 and Nj!=0):
sim_map[item_list[i]][item_list[j]] = (lij)/(Ni*Nj)**0.5
#if(sim_map[item_list[i]][item_list[j]]!=0):
# print(item_list[i]," ",item_list[j]," ",sim_map[item_list[i]][item_list[j]])
#sim_map[item_list[j]][item_list[i]] = sim_map[item_list[i]][item_list[j]]
return sim_map
#首先要获取输入用户的喜欢的item的列表,可以通过user_itemlist获得,然后要遍历所有的item j,因为要计算出所有的puj,要有一个操作可以获得与j最相似的k个item,然后通过公式计算即可
def get_result(input_user,user_itemlist,item_list,sim_map,k):
input_user_itemlist = user_itemlist[input_user];#获得输入用户喜欢的item列表
input_user_l = len(input_user_itemlist)
item_l = len(item_list)
Puj = {}
for j in range(0,item_l):#遍历所有的item
j_item_list = sim_map[item_list[j]]
j_item_list_sorted = sorted(j_item_list.items(),key=operator.itemgetter(1),reverse=True)#按照相似度排序
Puj.setdefault(item_list[j],0)
k = len(j_item_list_sorted) if k>len(j_item_list_sorted) else k
for h in range (0,k):#遍历与j_item相似度前k的item
for i in range(0,input_user_l):
Puj[item_list[j]]+=sim_map[j_item_list_sorted[h][0]][input_user_itemlist[i]]#按照公式计算Puj
Puj_sorted = sorted(Puj.items(),key=operator.itemgetter(1),reverse=True)
return Puj_sorted[0][0]
if __name__ == "__main__":
item_userlist,user_itemlist,user_list,item_list = get_data();
sim_map = cal_item_sim(item_userlist,item_list
item_info = get_item_info();
for i in range(1,101):
recommend = get_result(i,user_itemlist,item_list,sim_map,5);
print(i," ",item_info[recommend])
代码文件同样要放在和ratings.csv,movies.csv,file_reader.py相同的目录中.
部分运行结果:

总结
这次只是实现了最基本的协同过滤,公式升级没有搞,在电影推荐这个案例中,与基于用户的协同过滤相比,基于物品的协同过滤复杂度更高,两种协同过滤各有各的适用场景,用其他博客中的话来说,基于用户的协同过滤更加社会化,而基于物品的协同过滤更加个性化.















 865
865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









