







G10: Enabling An Efficient Unified GPU Memory and Storage
Architecture with Smart Tensor Migrations
Haoyang Zhang, Yirui Eric Zhou, Yuqi Xue, Yiqi Liu, and Jian Huang
University of Illinois Urbana-Champaign (UIUC)
https://arxiv.org/abs/2310.09443
引言
一年前,OpenAI ChatGPT 横空出世,开启 AI 大模型时代,如今国内更是“百模大战”打得如火如荼。相信不少朋友都看过下图:大模型尺寸以每两年 410 倍的速度疯狂增长,而 GPU 处理器作为 AI 算力基础,其内存容量增长速度只有每两年 2 倍。GPU 内存容量严重制约了可训练的模型规模和算力提升速度,成为了阻碍 AI 技术发展与落地的重要瓶颈,这称之为 GPU 内存墙问题。
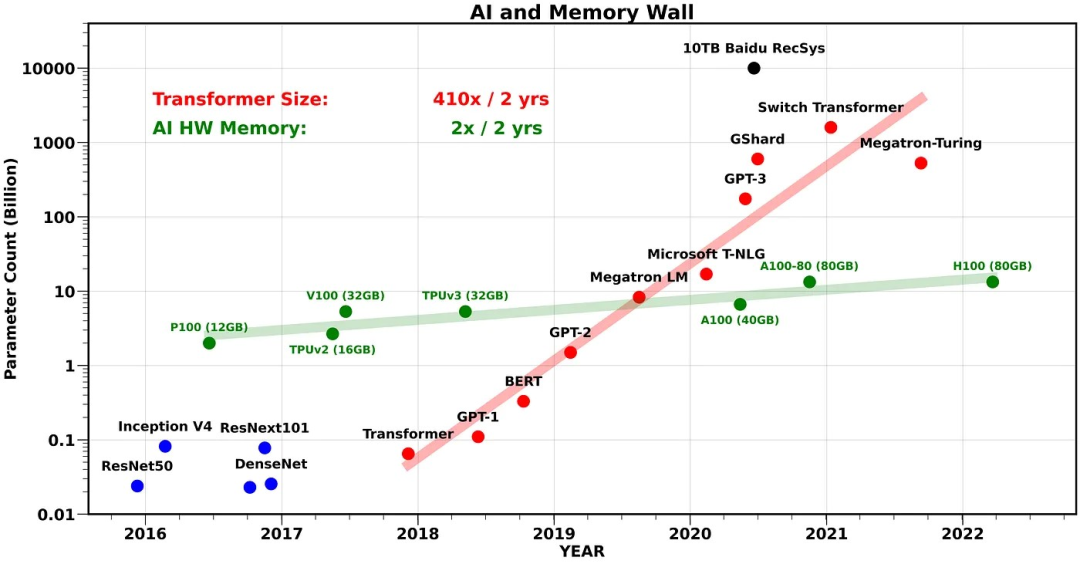
图:Transformer 模型尺寸增长速度 >> GPU/TPU 处理器内存容量增长速度
(source: https://medium.com/riselab/ai-and-memory-wall-2cb4265cb0b8)
构建 GPU 集群虽然能够提供聚合的大内存,但也带来成本高昂、GPU 间“通信墙”、可靠性保障和资源调度复杂等问题。注意到,当前高端 GPU 的内存容量一般为几十上百 GB,其增长受限于 DRAM 技术扩展瓶颈、芯片面积和功耗限制等因素。相比而言,外部存储设备 SSD 的容量可达多个 TB,且容易扩展。
如果能够凿壁借光,借助外部 SSD 存储来扩展 GPU 内存,那么就能打破内存容量壁,以低成本实现超大模型训练。然而,这带来一个关键问题:SSD 访问带宽和延迟比 GPU 内存慢 2-3 个数量级,慢速 SSD 访问将导致难以接受的计算性能,浪费宝贵的 GPU 时间。
最新的 MICRO 2023 论文 G10 正是在这个方向上做出了一次有趣的探索,它构建了一个基于 SSD 存储的 GPU 统一内存架构,并着力于深度神经网络 DNN 训练场景,解决慢速 SSD 内存带来的性能问题。
本文将从如下方面解读 G10。
-
背景介绍。介绍 DNN 训练过程和 GPU 统一内存架构,并总结 GPU 内存墙问题的现有解决方案。
-
论文解读。1) 研究动机:说明在 DNN 训练场景下,利用 SSD 扩展 GPU 内存是可行的;2) 设计思路:描述如何在不同内存设备间自动迁移张量(一维及多维向量的统称)数据、以及GPU 统一内存架构实现;3) 实验结果:展示 G10 的性能表现。
-
论文评述。我们对论文进行原创性评述。该论文以娴熟的写作技巧勾勒出了一个美好愿景,但其内核稍显薄弱。
1. 背景介绍
1.1. DNN 训练过程
深度神经网络 DNN (deep nueral network) 是一种包含输入层、多个隐藏层、以及输出层的神经网络模型,具有表达能力强(能为复杂非线性系统建模)、擅长处理大规模数据、适应性和可扩展性强等优点,是计算机视觉、语音识别、及自然语言处理、推荐系统、医疗诊断等诸多 AI 应用的基础。
DNN 训练过程主要包括:(1)初始化网络参数;(2)前向传播,即数据从输入层经过隐藏层逐层传递到输出层,产生预测结果;(3)将预测结果与真实标签进行比较,计算损失函数;(4)反向传播,即根据损失函数的值计算梯度值,从输出层到输入层反向传递,更新网络中的参数;(5)重复前向和反向传播直到达到停止训练的条件。如下图所示。
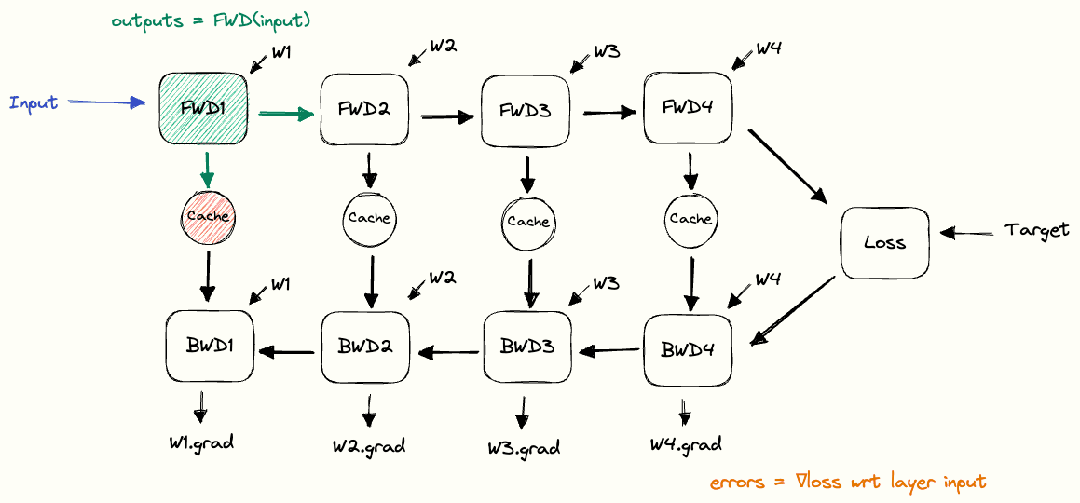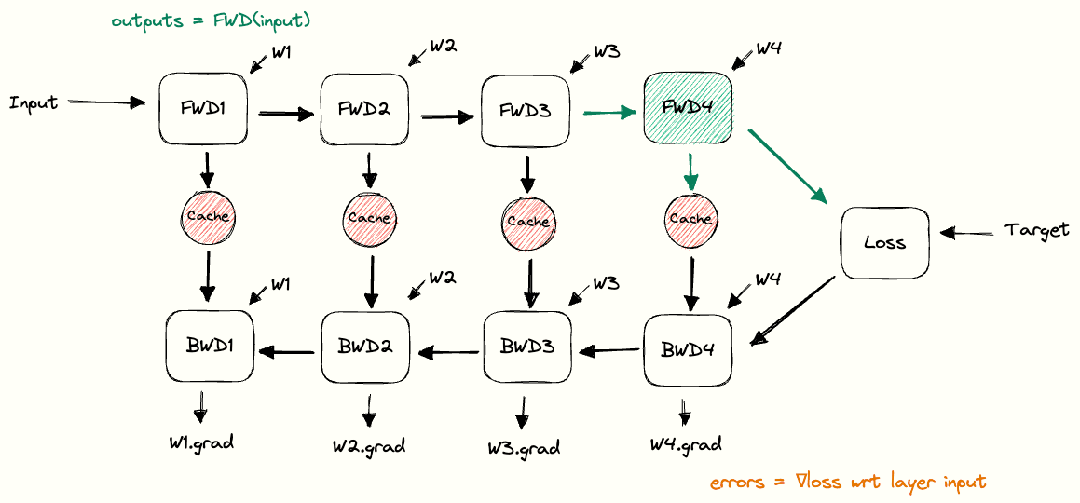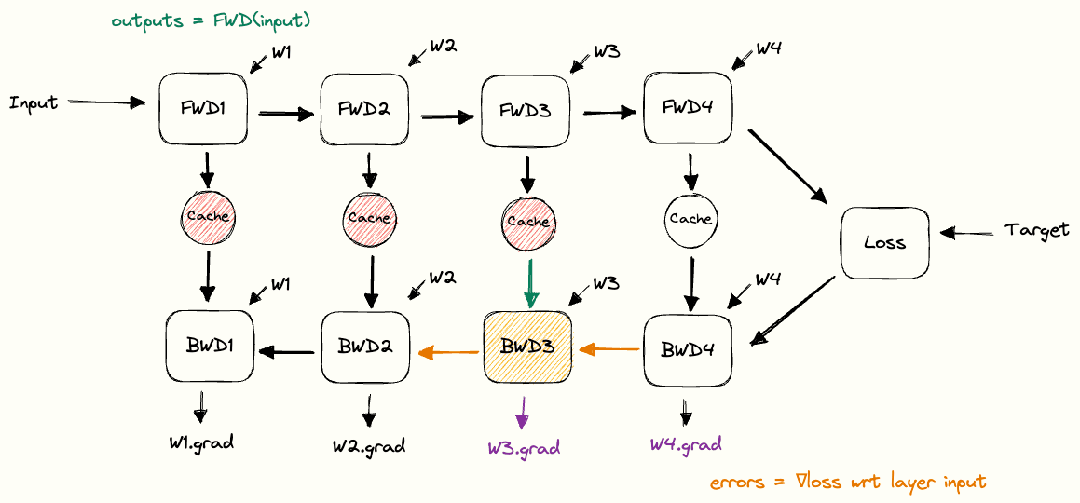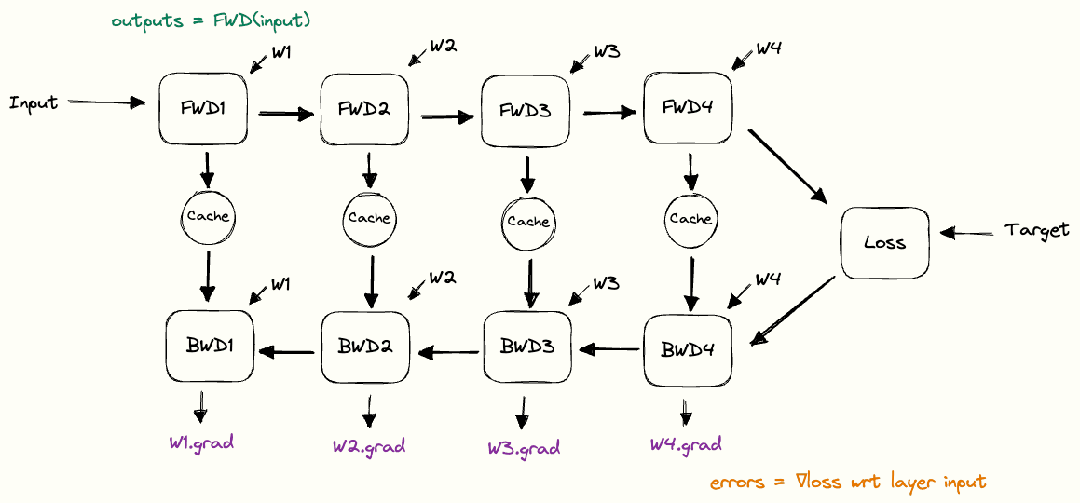
图:DNN 训练过程
(source: https://siboehm.com/articles/22/data-parallel-training)
1.2. GPU 统一内存架构
NVIDIA 于 2013 年在 CUDA 6.0 引入统一内存编程模型,能够在系统内不同处理器(如 CPU 和 GPU)的物理内存上创建一个统一编址的虚拟内存空间,由不同处理器直接访问,如下图所示。
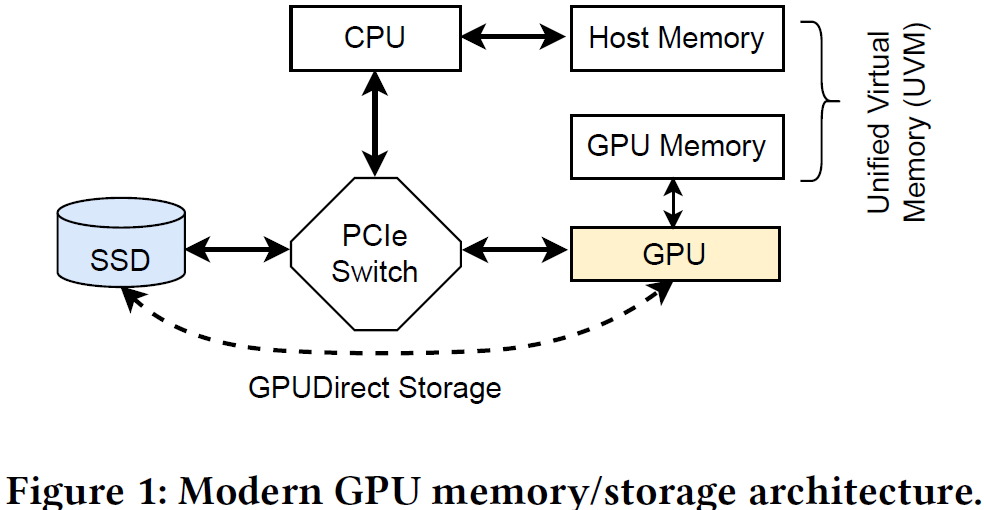
处理器访问统一内存空间中数据时,如果该数据位于另一个处理器的物理内存中,系统会透明地自动将其迁移到本地物理内存(依赖于处理器内存管理单元 MMU 和缺页异常/中断处理程序),而不需要程序员显式实现内存拷贝操作。因此,统一内存架构能够扩展 GPU 内存空间,简化 GPU 编程,而数据搬移依然存在。
另外,NVIDIA 于 2019 年引入 GPUDirect Storage 技术,允许在 GPU 内存和外部存储设备之间进行直接 DMA 数据传输,而不用经过 CPU 内存转运,以减少数据传输延迟和 CPU 开销。注意到,以上数据传输操作仍需 CPU 介入进行触发,最新的 BaM (ASPLOS’23) 工作进一步消除了 CPU 介入,允许 GPU 直接发起数据传输。
1.3. GPU 内存墙问题
大模型的高速发展与广泛应用使得 GPU 内存墙问题日益严重,针对该问题,业界提出了一系列解决方案 ,下表对它们的思路进行了简单总结,对具体设计感兴趣的读者可以自行查阅相关论文和资料。
本文所解读的 G10 属于内存交换方法,这一类方法面临共同的设计选择和技术挑战。第一,在系统架构方面,选择什么外部内存来扩展 GPU 内存,常见的包括 CPU 内存和 NVMe SSD。第二,在设计策略方面,选择什么数据卸载到外部内存,以及如何提前将所需数据从外部内存预取到 GPU 内存,避免阻塞 GPU 计算。
DNN 训练是这类方法的主要目标场景,它们(包括 G10)均观察和利用到一个重要特性:在 DNN 训练过程中,数据访问模式具有可循规律和可预测性。这使得在可接受的性能损失约束下,数据卸载和预取成为可能。

2. 论文解读
2.1. 研究动机
利用外部 SSD 存储来扩展 GPU 内存面临的关键问题是,能否、以及如何避免慢速 SSD 内存访问带来过大的性能损失。为回答该问题,论文面向 DNN 训练场景,研究了运行时内存使用情况和数据访问模式。实验平台为 NVIDIA A100 GPU。
作者分别定义活跃张量(张量是 DNN 模型的基本数据类型)和非活跃周期为给定时间内被 GPU 核心程序(kernel)访问到的张量、张量两次访问之间的间隔时间。以下是三个重要发现。
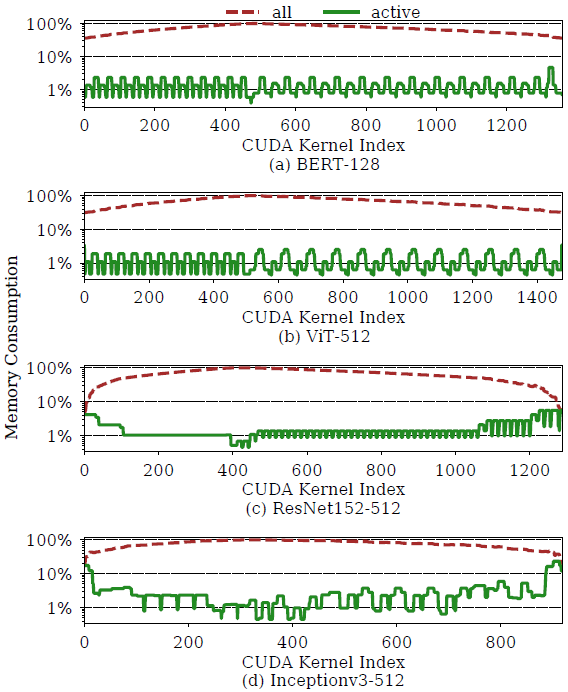
| 发现一:运行时只需保留很小一部分张量在内存即可完成 GPU 计算,其余大部分张量可以卸载到外部内存,待需要使用时再提前预取到 GPU 内存。 |
具体而言,对于大多数 DNN 模型,训练过程中活跃的张量只占很小一部分(少于 10%、平均 1%),如下图所示。其中主要原因在于,DNN 训练的前向传播和后向传播过程都是层层推进,每一层网络的当前计算只涉及相关的激活张量、权重张量、以及相应的梯度张量。
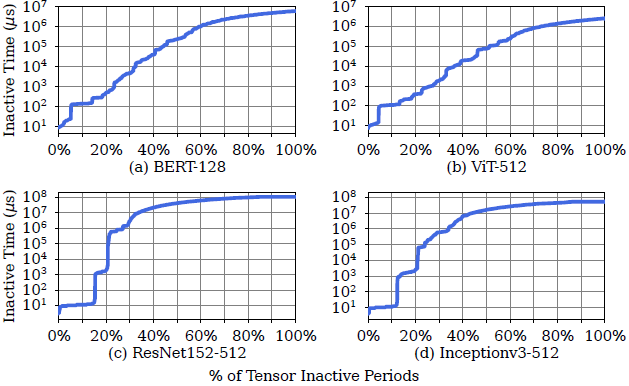
| 发现二:存在大量张量,它们的非活跃周期持续较长时间,使得它们能够被安全地卸载到慢速的外部 SSD 中。 |
非活跃周期较长的原因在于,在典型的 DNN 网络结构(不考虑 branch、join、loop)中,一个张量只会在前向传播和后向传播过程中分别被访问一次,其中间隔时间较长。
例如,CNN 模型中超过 60% 的非活跃周期超过 10^7 微秒,Transformer 模型中约有 50% 的非活跃周期大于 10^5 微秒。相比而言,SSD 访问延迟一般为几十微秒,若触发闪存写入或擦除操作,则上升到几百上千微秒。
| 发现三:卸载不同的非活跃张量带来的 GPU 内存收益、数据迁移开销显著不同;另外,运行时 GPU 内存消耗存在波动(见发现一的图)。在选择张量进行内存卸载时,需要最大化内存效率。 |
其中,不活跃张量的大小分布、不活跃周期时长分布都具有较大跨度。例如,在 Inceptionv3-512 模型中,前者从 10KB 到 2.7GB,后者从 10 微秒到 100 秒)。
2.2. 设计思路
G10 面向 DNN 训练提出了一种融合 CPU 内存和外部 SSD 存储的 GPU 统一内存架构,并以透明的方式实现数据在内存之间的迁移。如下图所示,G10 主要包含张量活跃度分析器、张量迁移调度器、统一内存子系统三个关键模块。
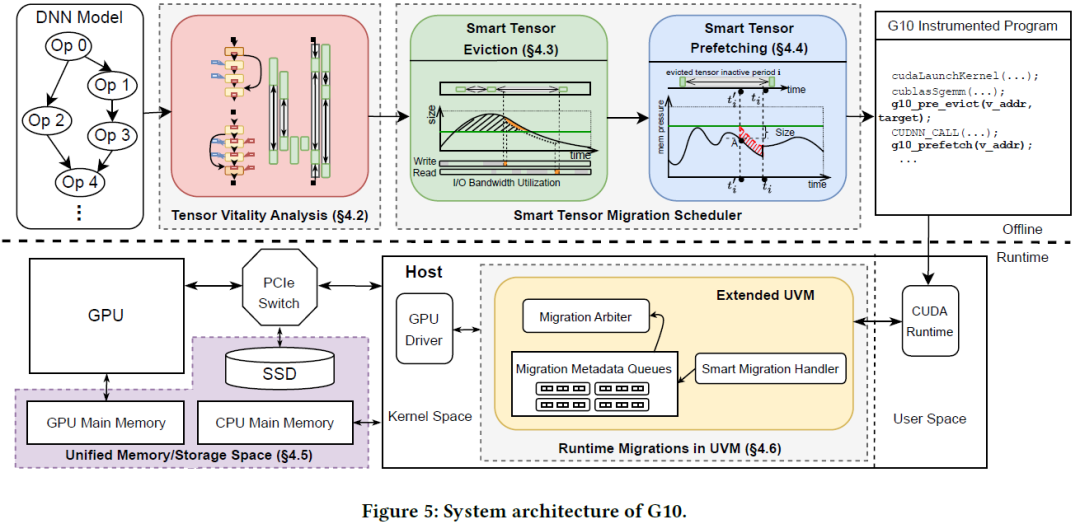
(1)张量活跃度分析器
由于 DNN 程序具有可预测的执行时间和数据流模式,G10 提出在程序编译阶段做离线分析,根据 GPU 核心程序的执行时间来估算张量的不活跃周期。
(2)张量迁移调度器
根据编译阶段获得的张量不活跃周期信息,离线确定程序运行时需要卸载和预取的张量、以及卸载和预取的具体时机,实现全局最优调度。然后,利用编译器在 GPU 程序中对应的位置插入张量卸载和预取指令,实现运行时自动执行。
选择收益与开销比最大的张量进行卸载:收益为卸载张量后节省的 GPU 内存,张量越大、可卸载的非活跃周期越长,收益越大;开销为张量的卸载和预取延迟。如下图所示,灰色区域表示张量的非活跃周期,蓝色③展示的是卸载张量 X 节省的 GPU 内存,蓝色①和②分别展示的是卸载和预取延迟。

卸载目的地:包括 CPU 内存或 SSD,G10 总是优先卸载张量到 SSD(因为其容量大),当 SSD 带宽满载时才选择 CPU 内存。
预取时机:对于已卸载的张量,其预取时机需要保证不会引起 GPU 计算等待,因此能够根据其非活跃周期结束时间点推导出最迟预取时间。G10 采用一种简单策略,将卸载的张量根据最迟预取时间(即紧急程度)排序,只要 GPU 内存出现空闲空间,就选择最紧急的张量执行预取。
卸载和预取代码插入:根据以上策略确认目标张量、及卸载和预取时机之后,即可利用编译器向 GPU 程序的对应位置插入张量卸载和预取代码。如下图所示,蓝色表示插入代码,例如第 3 行是提前预取 tensor23,为第 13 行的计算做准备,该计算完成后即卸载 tensor23(第 15 行)。

(3) 统一内存子系统
G10 融合 GPU 内存、CPU 内存、以及 SSD 构建统一的虚拟内存空间,使得 GPU 能够通过虚拟内存地址访问到三个设备的物理内存空间,并在运行时实现目标张量在内存之间的自动迁移。
具体而言,GPU 内存管理单元 MMU 维护一张页表,实现虚拟内存地址到多个设备物理内存地址的转换。当目标数据不在 GPU 内存时,GPU MMU 通过缺页异常机制隐式地将目标数据取到本地内存,此时会导致 GPU 计算等待。注意到,GPU 程序中已经显式插入张量预取指令,一般情况下不会触发缺页异常。
另外,G10 进一步将 SSD 内部的逻辑地址到闪存地址的转换层融合到 GPU 内存页表,并允许 SSD 控制器直接更新该页表(如发生垃圾回收数据迁移时)。
2.3. 实验结果
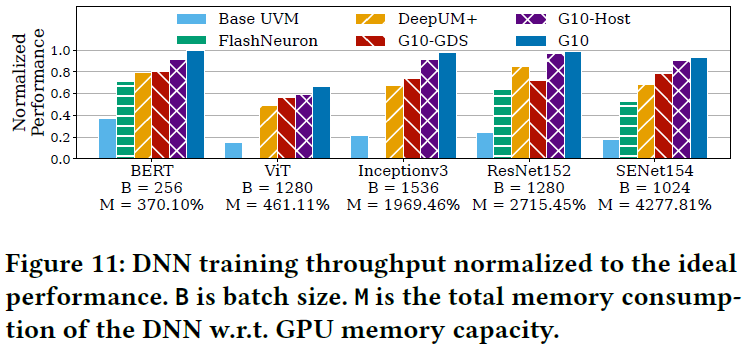
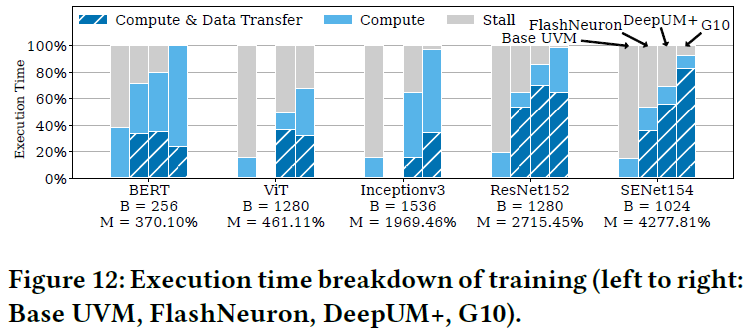
作者基于仿真平台 UVMSmart 和 GPGPU-Sim 实现 G10 的 GPU 统一内存架构,利用 SSDsim 仿真平台模拟 SSD 访问延迟。与现有的内存交换方法 DeepUM (ASPLOS'23)、FlashNeuron (FAST'21) 相比,主要的实验结果总结如下。
G10 能够(1)将 DNN 大模型(尺寸超出 GPU 内存)训练速度最多加快 1.75 倍,有效减少 GPU 计算等待时间,如下图所示;(2)支持采用更大的 batch size 进行训练;(3)在几乎不造成训练性能损失的情况下,节省主机 CPU 内存。
3. 论文评述
写论文如同讲故事,故事主题需要有趣且给人启发,情节叙述需要逻辑清晰且完整,内容细节需要丰厚饱满。笔者认为,该论文在选题上讲了一个“好”故事,在写作上讲“好”了一个故事,但设计实现略显薄弱。
3.1. 讲了一个“好”故事
GPU 内存墙是一个当前在 AI 领域和计算机系统(架构)领域受到广泛关注的热点问题,在此背景下,G10 提出一种融合外部 SSD 存储的 GPU 统一内存架构。从选题和概念上,这是一个美好的愿景,立马就能勾起读者的好奇心和兴趣。
在看到标题的那一眼,一系列问题和设想就不禁涌入脑海,让人想要深入了解其中的具体内容。例如,它是如何实现统一架构的;如何能够避免慢速 SSD 内存访问导致 GPU 计算性能急剧下降;有了大容量 SSD 内存加持,是不是就能够彻底打破 GPU 内存容量墙,让我们以低成本服务器、少量甚至单个 GPU 就能训练大模型。
在进一步阅读文章内容后,发现 G10 利用 DNN 负载中可预测的张量访问模式、以及编译器和虚拟内存机制,实现了 GPU 内存与 SSD 之间自动、透明的数据迁移。这也勾勒出了一个令人向往的愿景。
无疑,G10 讲了一个能够快速吸引论文评委和读者的“好”故事。
3.2. 讲“好”了一个故事
不止是选择了一个好主题,G10 的故事呈现(论文写作)技巧也是娴熟的。全文结构和写作逻辑清晰紧凑,读起来不费劲,且外表精致。
例如,在第一章,针对慢速 SSD 内存访问带来的性能问题,作者提出一种设计思路,即利用 DNN 训练过程中可预测的张量访问模式,智能选择张量在 GPU 内存与 SSD 之间进行交换。在论文第三章,作者通过直观和切题的实验观察,包括活跃张量的比例、非活跃周期时长分布等,对上述设计思路、以及后续第四章的具体策略设计进行了直接有力的支撑。
在内容提炼和图文表达上,作者也有独到之处。在描述面临的技术挑战和提出的策略设计时,作者都从较高层次对问题内涵和设计考量进行了提炼。
例如,在第 4.3 小节介绍张量卸载设计时,提炼出了三大挑战,需要综合考量 GPU 内存收益、外部内存的诸多特征、以及运行时可用带宽和卸载时机等因素,营造出设计难度大、设计方案合理坚实(solid design)的印象。另外,第 4 章设计图的呈现值得学习,它们生动准确地呈现出了 G10 的设计思想和具体策略。
3.3. 故事内核稍显薄弱
虽然 G10 论文通过娴熟的写作技巧呈现出了有趣的、有洞察力和启发意义的学术观点与设计思想,但它的设计、实现、及实验难说扎实。
第一,在仔细读过论文内容后,不难发现 G10 提出的诸多策略设计在精致的包装下其实都较为简朴(详见本文第 2.2 小节的介绍),缺少令人印象深刻的点。
第二,从系统研究的角度看,部分设计与实现细节不够饱满。例如,论文没有说明该如何将张量卸载和预取操作映射到 GPU 计算单元,与当前的 GPU 计算并行执行;没有具体说明该如何保证 GPU 统一内存的一致性(尤其是在 SSD 控制器也能更新 GPU MMU 内存页表的情况下);也没有讨论 SSD 垃圾回收操作带来的影响(会给数据访问带来多个毫秒的延迟)。
另外,对于将 SSD 内地址映射表融合到 GPU MMU 内存页表的设计,其必要性阐述似乎不够明确。反而,该设计会带来 GPU 内存一致性问题,并需要定制实现 SSD 设备,因此有过度设计之嫌。
第三,论文的设计实现与实验评估是基于仿真平台,虽然能够验证其设计思想,但实验结果的说服力会有所欠缺,也可能会缺少一些对真实系统实现中面临挑战和存在开销的洞察。
结语
在 AI 技术和应用高速发展的当下,GPU 内存墙成为计算机系统亟需解决的难题。G10 为我们勾画出融合 SSD 存储的 GPU 统一大内存这一美好愿景,无疑令人感到兴奋和受启发。美中不足之处在于,它的内核支撑稍显薄弱。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









