






| Pond: CXL-Based Memory Pooling Systems for Cloud Platforms Huaicheng Li, Daniel S. Berger, Lisa Hsu, Daniel Ernst, Pantea Zardoshti, Stanko Novakovic, Monish Shah, Samir Rajadnya, Scott Lee, Ishwar Agarwal, Mark D. Hill, Marcus Fontoura, and Ricardo Bianchini. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2023. |
引言
从1995年互联网时代拉开序幕,到2007年移动互联网时代兴起,到2011年跨入云计算与大数据时代,再到如今人工智能和万物互联时代已经揭开帷幕。数字化时代的发展振奋人心,这离不开底层基础设施——计算机系统技术的支撑。
为提高计算性能,计算机系统(注:主流的冯·诺伊曼架构)采用多级存储层次结构,其基本思想是将频繁访问的数据尽可能放到靠近处理器的内存,尽可能避免在计算过程中访问速度慢的外部存储。
近十年来计算机处理器核心数量和计算速度飞快增加,而由于DRAM技术瓶颈、处理器芯片面积和主板DIMM插槽受限等因素,内存容量和速度的增长速度已大幅落后。与此同时,机器学习大模型和大数据分析等现代应用的工作集规模呈现爆发式增长。
在此趋势下,受限的内存容量和速度导致计算机系统面临日益严重的计算性能瓶颈,即内存墙问题(该术语最初意指内存速度问题,后外延也包括内存容量挑战)。密歇根大学的研究显示,当有一半工作集无法放入内存时,应用性能会下降8到25倍[1]。
不仅如此,数据中心还面临内存成本高昂的问题。Meta和微软云公司的统计数据显示,内存成本分别高达其服务器总成本的40%和50%[2]。
如何以经济高效的方式突破内存墙问题,构建大内存计算机系统,是业界长期以来不断探索的方向。CXL(Compute Express Link)是英特尔于2019年提出的一种新型的设备互联技术标准,被认为是解决以上问题的变革性技术,会对数据中心基础架构产生深远影响。
目前,主流半导体芯片厂商(涵盖CPU、GPU、内存、存储和网络设备制造商)和各大云服务提供商都在积极拥抱CXL技术浪潮,学术界相关研究工作数量也正在迅猛增长。
本期为大家带来Pond论文深度解读,它基于CXL技术构建了第一个兼具高性能和低成本的公有云内存池系统。该工作堪称学术界与工业界合作的典范,由弗吉尼亚理工大学Huaicheng Li(FEMU SSD模拟器的作者)和微软云Azure团队(包括Mark D. Hill)共同完成,获得了计算机体系结构顶级会议ASPLOS’23杰出论文奖。该论文在短短7个月内已获得超过70次引用。
本文主要内容概括如下:
-
技术背景介绍:概述CXL协议内容,说明在公有云数据中心中进行内存池化的必要性、及面临的关键挑战,
-
Pond论文解读:(1) 研究动机,总结作者对大量微软云生产环境负载的分析观察与启示;(2)方案设计,介绍Pond的设计目标、核心思路与技术实现;(3) 实验评估,展示论文的评估方法和实验数据。
-
论文亮点评述:从多个维度评析论文亮点。
1. 技术背景介绍
CXL技术。Compute Express Link,意为计算快速链接,是一种全新的设备互联技术标准。CXL构建在PCIe(5.0及以后版本)接口之上,采用其物理层标准和生态系统,关键特征在于,支持主机处理器以缓存一致的内存访问语义(Cache-coherent Load/Store)与外围设备进行通信。CXL不仅支持内存子系统的容量和带宽扩展,而且可用于异构处理器及外围设备之间互联,实现计算资源和内存资源解耦及池化。
具体而言,CXL包含CXL.io、CXL.memory、CXL.cache三种子协议,它们的特点和应用如下表所示。为深入理解CXL技术的先进性,将CXL.memory和CXL.cache分别与NVMe协议的 CMB (Controller Memory Buffer)和HMB (Host Memory Buffer) 特性进行对比。

公有云内存池化。公有云的一个典型业务场景是以较低的硬件成本为客户提供高性能的虚拟机服务。内存子系统对于实现该目标至关重要,因为其成本高昂,且对系统性能有关键性影响。
然而,客户虚拟机包含CPU和内存等多维资源且具有多样化配置需求,它们在服务器集群上的分布调度是复杂的多约束背包问题,因此,很难在服务器上实现与虚拟机需求完全契合的CPU和内存资源分配。这导致一个称之为内存搁浅(memory stranding)的问题,即一台服务器上CPU核心已经全部租给虚拟机使用,但存在部分未分配的内存容量。从云服务提供商的角度看就是CPU售尽了,内存没售尽。
解决内存搁浅问题的有效手段是构建分离式共享内存池,为服务器和处理器按需动态分配内存,而不是以计算和内存资源紧耦合的方式在每个服务器中预先配置足量内存。
尽管访问远程服务器内存的思想在三十年前就已经出现,但是直到最近几年,高速网络技术的发展才使得分离式内存设计从梦想照进现实。一系列研究工作基于RDMA网络,通过应用透明的虚拟内存管理或虚拟文件系统、或应用自定义的方法实现分离式内存系统[3]。然而,由于网络延迟和软件开销,这些内存系统的访问延迟仍然在微秒级。
如今,CXL技术的出现进一步将远程内存访问延迟缩短至170到250纳秒,接近本地内存访问延迟(80-140纳秒)。
2. Pond论文解读
2.1 研究动机
作者针对公有云场景,围绕两个基本问题展开探索:(1) 服务器内存空间的利用率如何?(2) 分离式CXL内存的访问延迟高于本地内存,在严格的虚拟机性能约束下,采用CXL进行内存扩展是否能够满足性能要求?
针对第一点,作者通过分析覆盖微软云100个服务器集群和75天时长的生产环境数据集,观察到:(1) 在CPU资源利用率高的集群中,未分配搁浅内存的比例可高达25%,如下图所示;(2) 对于已分配给虚拟机的内存,在50百分位下虚拟机内存有50%未被使用(untouched)。
因此,存在严重的内存容量浪费问题。考虑到内存成本占服务器总成本的50%,这会导致巨大的资源浪费和成本损失。
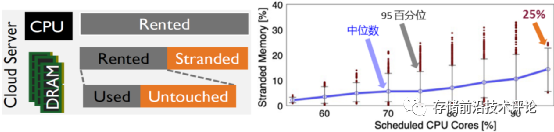
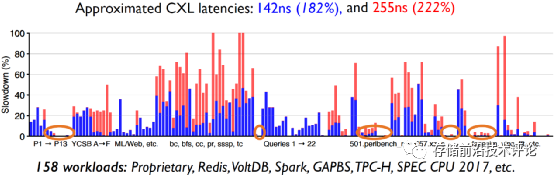
针对第二点,虽然当前没有真实的CXL设备和系统平台,但作者采用模拟的方法(具体细节参照本文2.3小节)基于真实服务器对158个应用负载进行了评估,分析它们在CXL内存相比于在本地内存中运行时产生的性能损失。
如下图所示,实验结果表明:(1) 25%左右的负载只产生了小于1%的性能损失;(2) 60%左右的负载遭受了大于5%的性能损失,一定比例(21% ~ 37%)的负载性能损失超过25%。因此,部分虚拟机对内存延迟不敏感,可完全分配CXL内存,而对于内存延迟敏感的虚拟机,可考虑配置本地和CXL混合内存,避免违反公有云性能约束要求。
| 基于以上观察,能否基于CXL技术构建一个同时满足公有云高性能约束和低硬件成本的内存池系统? |
2.2 Pond设计
(1) 设计方案概述
Pond内存池系统有以下四个设计目标。
-
低成本:通过减少搁浅内存和提高内存空间利用率来降低服务器内存成本。
-
高性能:一方面,在采用访问速度相对较慢的外部CXL内存后,虚拟机的性能应该接近于运行在NUMA节点本地内存;另一方面,对CXL内存池的管理和访问应该保持低开销。
-
硬件兼容性:虚拟化硬件加速(如SR-IOV)要求在虚拟机启动时预先分配所需全部内存,而不是动态按需分配内存(以支持内存超额分配)。
-
软件兼容性:以对虚拟机透明的方式实现CXL内存的分配和使用、以及对虚拟机性能的监测。
为实现以上目标,Pond的系统架构如下图所示,解决思路概述如下。
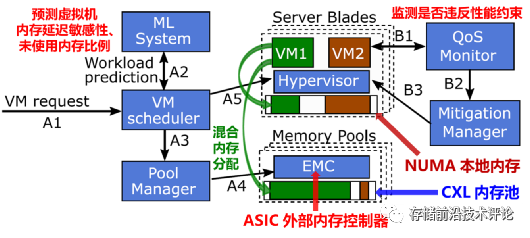
-
设计智能的混合内存分配策略,在满足虚拟机性能约束的同时减少服务器内存搁浅。首先,定义虚拟机性能目标作为条件约束,例如,相比于分配本地内存,98%的虚拟机性能损失不超过5%。
然后,事先预测虚拟机的内存延迟敏感性、未使用内存比例(预测方法见后文介绍),在虚拟机启动时为其完成内存分配。对于不敏感的虚拟机,为其全部分配外部CXL内存;对于敏感的虚拟机,根据预测的内存使用比例分配NUMA节点本地内存,为不使用部分分配外部CXL内存。
-
以对虚拟机透明高效的方式完成系统实现。首先,在内存池架构方面,为多个CPU sockets配置一个共享的外部CXL内存池,并基于ASIC实现具有多个CXL端口的外部内存控制器(EMC, external memory controller),负责CPU与CXL内存之间的通信。
其次,为了让虚拟机以透明的方式使用CXL内存,通过hypervisor将分配的外部CXL内存以zero-CPU-core virtual NUMA (zNUMA)的方式暴露给虚拟机,后者的操作系统会优先分配和使用本地内存,尽可能少使用zNUMA内存,避免性能损失。
另外,智能内存分配策略需要收集虚拟机特征和监测虚拟机性能,通过利用CPU性能监控单元和修改hypervisor来实现透明的数据收集和性能监测。
(2) 关键技术介绍
进一步展开介绍两项值得关注的设计:如何配置CXL内存池大小、如何预测虚拟机的内存延迟敏感性和内存使用比例。
-
CXL内存池大小配置。假设每N个CPU sockets连接一个外部CXL内存池。通过分析芯片连接拓扑结构发现,当N不大于16时,CPU能够直接与EMC相连,而大于16时需要在关键路径上加入CXL交换机(增加端口),这会显著增加内存池访问延迟和硬件成本,如下图所示。
而且,通过分析微软云虚拟机负载发现,当增大N时,共享内存池在减少搁浅内存方面的收益存在边际递减现象(见论文图3)。因此,作者建议将N设置为8或16。
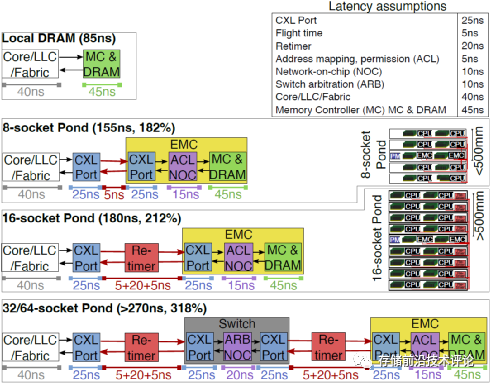
-
虚拟机预测方法。内存延迟敏感性的定义是,如果一个虚拟机运行于外部CXL内存上相比于运行于本地内存上的性能损失超过某个阈值,那么该虚拟机为内存延迟敏感型。
Pond采用基于决策树的监督学习方法构建虚拟机内存延迟敏感性的预测模型,训练输入的特征为虚拟机运行时CPU性能检测计数器采集的相关指标,标签为性能损失值(通过离线测试获得)。Pond会持续收集虚拟机运行特征,定期重训练预测模型。
虚拟机未使用内存比例的预测依据是,来自于同一个客户的虚拟机很有可能具有类似的行为特征。其预测同样采用监督学习模型,训练输入的特征为虚拟机元数据(如客户ID、虚拟机类型、及位置),标签为虚拟机在生命周期内未使用内存比例的统计最小值。
另外,Pond会监测使用CXL内存的虚拟机,如果对它们的未使用内存比例的预测过高,需要判断它们是否存在过高的性能损失;如果存在,需要执行虚拟机迁移操作来重配置其内存分配。
2.3 实验评估
由于没有真实的CXL内存设备和系统平台,作者通过模拟的方法构建了系统测试平台,即在具有两个CPU sockets的服务器上只使用一个socket运行虚拟机,而将另一个socket的CPU cores禁用,模拟为CXL内存池。在所测试的英特尔和AMD服务器中,CXL内存访问延迟(或者说跨socket内存访问延迟)分别是本地内存访问延迟的182%和222%。
作者针对Pond的多个设计点和总体有效性展开了全面且层层深入的评估,并总结出10个具体结论和启示。具体而言,包括以下六个方面:①基于zNUMA的CXL内存使用方式的有效性、②过高预测虚拟机未使用内存比例的危害性、③虚拟机内存延迟敏感性预测模型的准确性、④虚拟机未使用内存比例预测模型的准确性、⑤两个模型结合后的有效性、⑥总体上减少内存搁浅的收益。
本文选择其中三个结论进行介绍,对其它结论感兴趣的读者推荐阅读原论文
-
生产场景下zNUMA有效性验证:当对虚拟机未使用内存比例预测准确(应用负载工作集存放于本地内存)时,zNUMA节点内存访问流量几乎为零,将untouched memory放到外部CXL内存不会引起虚拟机性能下降。
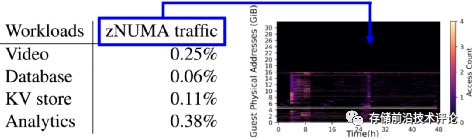
-
生产场景下虚拟机未使用内存比例的预测准确性评估:在所有的虚拟机未使用内存中,Pond能够识别出其中的25%,产生过高预测的虚拟机只占4%。
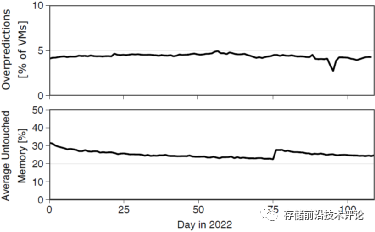
-
总体上减少内存搁浅的收益分析:当为8-16个CPU sockets配置共享内存池时,Pond能够减少7% ~ 9% 的总体内存容量需求。
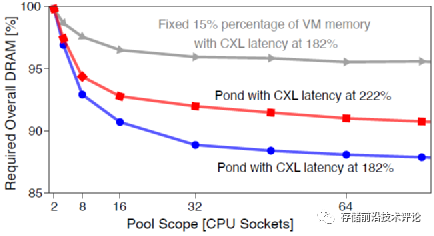
3. 论文亮点评述
笔者认为,该论文有以下三大亮点。
-
前瞻性研究:CXL技术自2019年出镜以来受到业界广泛关注和热议,下图展示了谷歌学术上CXL搜索结果的数量在近五年快速攀升。虽然业界笃信CXL技术会给数据中心发展带来变革,引领我们进入大内存时代,但是对于应当如何部署CXL内存、它具有哪些潜力、以及具有多大潜力都还处于雾里看花的初级阶段,尤其是可用的CXL 2.0内存产品预计2024年才会发布上市。
Pond论文精准识别出CXL技术的一个杀手级应用场景——在公有云平台构建兼具高性能和低成本的内存池系统,并给出一套实际可行的技术方案,通过严谨的实验评估和翔实的数据分析证明该方案有潜力将内存总成本降低7%。这极具前瞻性。
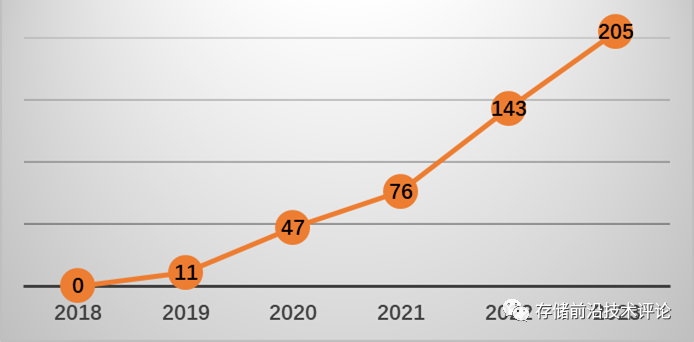
(图:谷歌学术按年份搜索“Compute express link”的结果数量)
-
数据资源与分析能力:除了论文的“首个兼具高性能和低成本的CXL内存池系统”高端定位之外,当看到“微软云100个服务器集群和75天时长的生产环境数据集”、“158个负载”这些数据描述时,就能体会到这个研究工作的厚重分量,就能明白这是一篇无法被拒绝的顶级论文。
作者也无愧于这个数据金矿,展现出卓越的数据分析能力,从诸多维度挖掘提炼出富有洞察力的观察和启示。笔者鼓励感兴趣的读者去阅读原文,细细品味其中精妙之处。
-
研究技巧与专业功底:尽管当前没有真实可用的CXL内存设备和系统平台,但是作者通过精妙的研究技巧与扎实的专业功底完成了设计论证与实验评估。例如,在4.1章节CXL内存池硬件设计中,作者通过严谨的理论分析论证了ASIC外部内存控制器的设计、以及应该如何配置内存池大小;在实验评估中,利用现有多CPU sockets服务器模拟实现CXL内存池。
从这个角度看,正好体现出学术研究的前瞻探索性和灵活性,也能给研究者一些启示——即使没有可用的硬件平台,也能做出好的研究。
结语
Pond论文叙事宏大,是一部史诗般的作品。它全面深入地展示了一个新颖的系统,让我们一目了然,但是却无法复制,因为它不是一个点,而是数据中心CXL共享内存池这么大一个面。要完成这项研究,不仅需要出类拔萃的科研能力,包括学术视野、系统架构、实验设计、数据分析、以及工程管理等,还需要具备非凡的影响力,能够调动庞大的工业界资源进行支撑。
笔者不禁在想,像Pond这样的论文还有谁能够写出来?脑子里第一个想到的是Jeff Dean。ASPLOS 2023还有一篇CXL内存相关的优秀文章TPP,但是它的立意和叙事气势被Pond盖过了。
参考文献
[1] Juncheng Gu, Youngmoon Lee, Yiwen Zhang, Mosharaf Chowdhury, and Kang G. Shin. 2017. Efficient memory disaggregation with INFINISWAP. In Proceedings of the 14th USENIX Conference on Networked Systems Design and Implementation (NSDI), 2017.
[2] Huaicheng Li, Daniel S. Berger, Lisa Hsu, Daniel Ernst, Pantea Zardoshti, Stanko Novakovic, Monish Shah, Samir Rajadnya, Scott Lee, Ishwar Agarwal, Mark D. Hill, Marcus Fontoura, and Ricardo Bianchini. 2023. Pond: CXL-Based Memory Pooling Systems for Cloud Platforms. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2023.
[3] Hasan Al Maruf and Mosharaf Chowdhury. 2023. Memory Disaggregation: Advances and Open Challenges. ACM SIGOPS Operating Systems Review, Volume 57, Issue 1, June 2023.















 816
816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









