






ROLEX: A Scalable RDMA-oriented Learned Key-Value Store for Disaggregated Memory Systems
Pengfei Li, Yu Hua, Pengfei Zuo, Zhangyu Chen, and Jiajie Sheng,
Huazhong University of Science and Technology
https://www.usenix.org/conference/fast23/presentation/li-pengfei
引言
如果将内存资源从计算节点分离出来,放在专门的内存节点上,然后通过高速网络连接,实现内存的动态配置和共享,那么系统将更加灵活高效。这就是ROLEX的愿景,一种基于学习索引的分离式内存系统,提供透明的内存扩展和共享,同时保证高性能、一致性和高可扩展性。ROLEX是华中科技大学的华宇教授团队发表在信息存储领域顶会USENIX FAST’23上的文章,获得会议最佳论文。
本文将带您深入了解ROLEX的研究背景、技术原理、实现细节、评估结果和研究贡献,以及作者的写作技巧。
本文将从如下方面解读ROLEX:
-
背景介绍。介绍分离式内存系统、基于RDMA的键值存储、学习索引的技术趋势和3篇开山之作,以及将学习索引引入RDMA键值存储的首篇文章XStore。
-
论文解读。1) 研究动机。概述ROLEX的生态背景、问题陈述、以及作者做这项研究的出发点和目标。2) 设计思路。我们总结ROLEX的两个主要设计特征。3) 关键技术。详细说明ROLEX的设计和实现,以及它如何优化动态负载性能、维护系统一致性和可扩展性。4) 评估分析。展示ROLEX在不同场景下的评估数据和对比分析,以及它相对于其他方法的优势。
-
论文评述。我们对本文进行原创性评述,分析论文亮点,以期激发读者讨论。
1. 背景介绍
1.1 分布式系统架构之分离式内存 (Disaggregated Memory)
内存是数据中心基础设施中重要且昂贵的资源(其成本约占服务器成本的50% [1]),深度学习和大数据分析等热门应用都高度依赖于大内存系统。内存容量的不足是数据中心的一个严重问题,因为它限制了处理器核心、虚拟机和应用程序的数量和性能。随着内存需求的增长和供应的减少,每个内核可用的内存容量将下降,导致性能损失。此外,内存也是系统成本和功耗的主要来源。与传统的CPU内存耦合架构相比,分离式内存系统将内存节点与计算节点解耦合,能够实现内存资源的高效共享和灵活扩展,在提高资源利用率的同时提供良好的可管理性和故障隔离性。
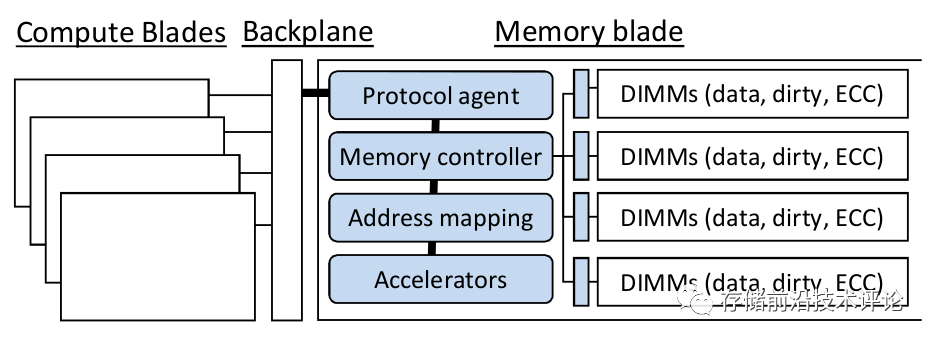
-
开山之作 1:分离式内存 (Lim et.al. ISCA'09 [2])
分离式内存 (Disaggregated Memory)的概念最早于2009年的ISCA会议上由密歇根大学,惠普和AMD的研究人员提出[2]。分离式内存系统提供了一种透明的内存扩展和共享的解决方案,将内存模块从计算节点分离出来,放在一个专门的内存刀片上,并通过高速网络连接。这样,可以实现内存资源的动态配置和共享,同时优化性能、成本和可扩展性。中国计算机学会于2022年3月25日发布了“分离式内存”专业术语审定与解释 [3]。
1.2 网络通信技术之RDMA (Remote Direct Memory Access
RDMA 是一种低延迟、高带宽的远程内存访问技术,广泛应用于包括分离式内存系统在内的分布式存储系统。RDMA支持单边和双边两种操作类型。其中,单边操作允许绕过远程主机CPU和操作系统直接访问其内存,只支持简单的读、写、原子操作;双边操作采用消息传递模式(即send和receive),支持更丰富的远程调用操作,但需要远程主机CPU介入处理。
-
开山之作 2:基于RDMA的键值存储 Pilaf (Mitchell et.al. ATC'13 [4])
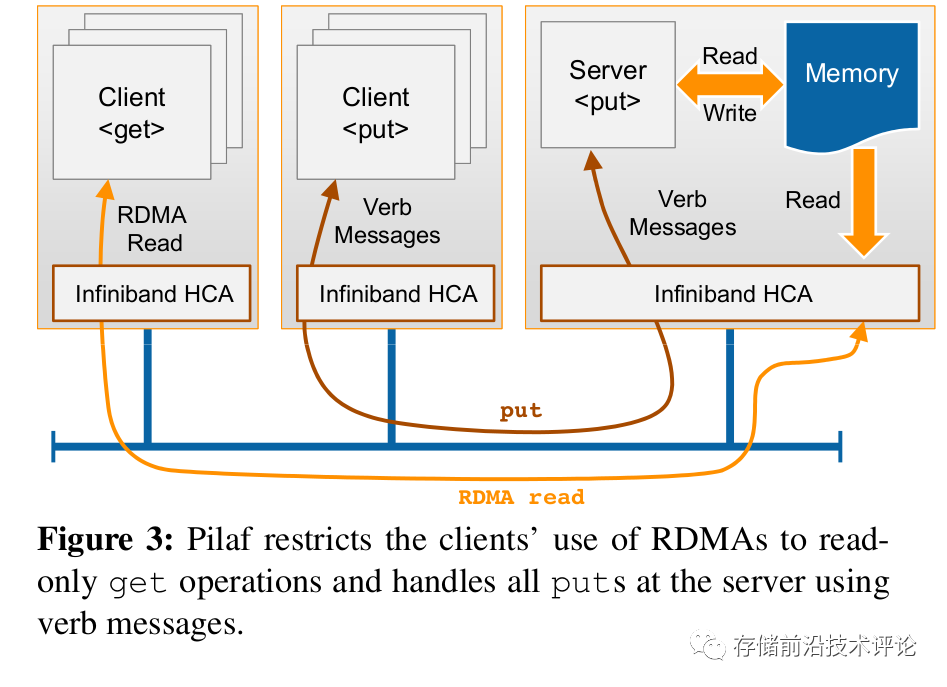
Pilaf 的动机是有效地使用RDMA来构建具有高吞吐量和低 CPU 开销的分布式内存键值存储。先前的相关工作包括使用 RDMA 来增强键值存储(例如 Memcached)的性能,将 RDMA 视为加速标准消息传递的手段。然而,Pilaf 与这些设计不同,它允许客户端完全绕过服务器的 CPU 来处理读取请求。Pilaf采用基于哈希索引和RDMA实现的无序键值存储系统,它利用两次单边RDMA read操作实现高性能读取Get(第一次获取目标数据存储地址,第二次获取目标数据),而利用双边RDMA操作处理PUT请求,由服务器端CPU处理写请求带来的哈希索引更新。Pilaf 的关键思想是将 RDMA 的使用限制为只读服务请求(获取),同时让服务器通过传统消息传递处理所有其他请求。这种方法获得了 RDMA 的大部分性能优势,同时简化了设计并避免了同步问题。
1.3 索引结构之学习索引 (Learned Index)
索引结构是高效数据访问的答案,满足不同访问需求有多种选择。例如,B-Trees适用于范围请求,哈希映射适用于单键查找,布隆过滤器用于检查记录是否存在。过去几十年来,索引已经得到广泛调整以提高内存、缓存和CPU效率。然而,这些索引仍然是通用数据结构,没有利用现实世界数据中更常见的模式。了解数据分布可以高度优化几乎任何索引结构。机器学习提供了学习数据分布规律等模式的机会,以较低的工程成本自动合成专门的索引结构,称为学习索引。
-
开山之作 3:学习索引 (Kraska et.al. SIGMOD'18 [5])
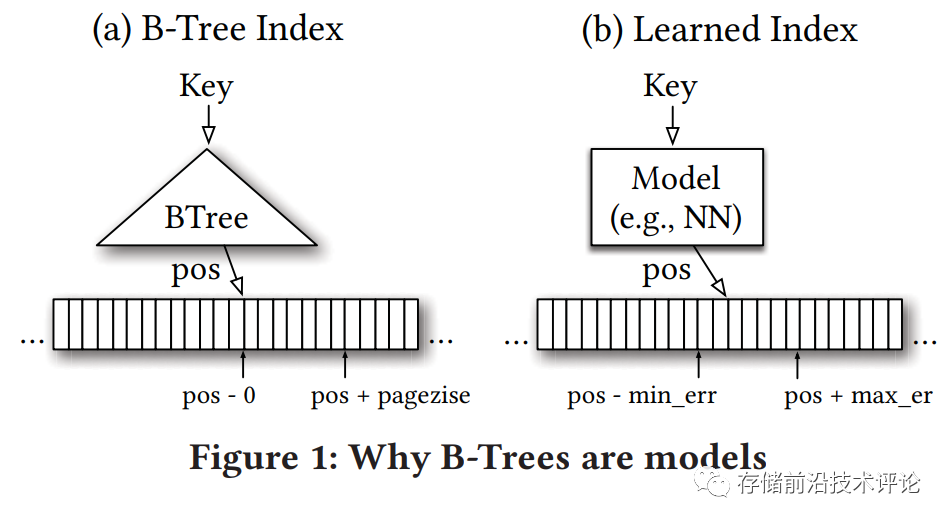
学习索引的动机是探索使用机器学习模型(包括神经网络)来提高传统索引结构的效率和性能,甚至替代它们的潜力,于2018年由MIT和谷歌的学者提出,快速成为研究热点(相关文章的引用数在笔者写作时已经达到931次)[5]。学习索引的基本思想是,利用机器学习模型拟合数据分布(键值到存储位置的映射),代替传统的索引结构(如B树、哈希、位图等)。其优点在于,能够根据数据分布和查询负载来自适应地调整索引结构,大幅降低索引空间开销和提高查询性能(相比于树结构,可将空间开销降低2-4个数量级)。这种方法有可能带来显著的好处,尤其是在下一代硬件上。在具体实践中,学习索引在处理动态负载(数据分布发生变化)、适用范围、模型调优等方面面临诸多挑战。
1.4 附网内存键值存储(Network-attached in-memory key-value stores)
附网内存键值存储是数据库、分布式文件系统、服务器无感知计算等数据中心应用的底层引擎 [6]。内存键值存储可以分为无序键值存储和有序键值存储,前者通常采用哈希索引,后者通常采用树结构、支持范围查询。附网内存键值存储主要基于RDMA协议和B树等数据结构来实现。对于树型索引,客户端利用单边RDMA Read操作访问远程服务器端数据时,需要先遍历服务器端树索引来获取目标数据位置,造成logN 次网络往返开销,效率低下并且存在内存浪费、延迟增加和错误失效等问题,学习索引被引入附网内存键值存储系统,用于快速预测静态负载中数据存储位置,使得理想情况下查询请求仅需要两次RDMA read操作。
-
RDMA键值存储 + 学习索引 (Wei et.al. OSDI'20 [6])
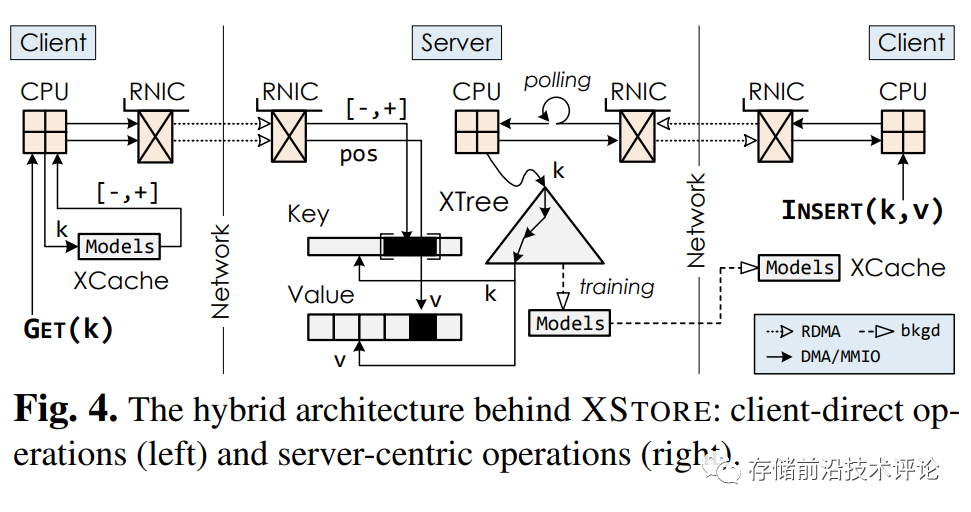
传统的基于分布式内存的有序键值系统一般采用树索引结构,当在客户端利用单边RDMA Read操作访问远程服务器端数据时,需要先遍历服务器端树索引来获取目标数据位置,造成log(N) 次网络往返开销。先前也有工作在客户端使用索引缓存来减少RDMA操作,但是使用索引缓存也只能有限的提高性能,因为会出现capacity miss,大量随机访问以及缓存失效的开销很高。为解决该问题,XStore在服务器端保持树索引结构,用于处理动态负载(插入和删除)。XStore首次在RDMA键值存储系统中引入学习索引缓存,在服务器端训练一个内存开销较小的模型作为静态索引,将其缓存在客户端本地,用于快速预测静态(读取和更新)负载中数据存储位置,使得查询请求通过两次RDMA read操作,一次读叶子节点和一次读数据操作,即可完成。具体而言,查询请求的输入是lookup key,Xmodel可以预测跟这个key对应的一个或者多个潜在叶子节点的逻辑位置,然后客户端用TT转换表将逻辑位置转换为远端的物理位置,第一次RDMA读操作根据物理位置来取这些叶子节点(每个叶子节点包含N个keys)。接下来客户端对叶子节点进行遍历,找到目标key,计算这个key对应的value的位置,然后再执行一次RDMA读操作取数据。
分离式内存系统是附网内存存储的最新架构趋势。分离式内存节点与附网内存服务器的主要区别在于分离式内存远端节点仅有比传统服务器低得多的计算能力。ROLEX论文的研究对象是分离式内存场景下基于RDMA的有序键值存储系统,而不是基于一般的高算力附网内存服务器,这是ROLEX跟XStore[6]研究上下文的主要区别。
| ROLEX是学习索引与RDMA键值存储在分离式内存系统中内存节点低算力、高能效趋势下的首次结合,支持高性能的静态和动态请求处理,具有良好的可扩展性。 |
2. ROLEX 论文解读
2.1 研究动机
分离式内存系统的一大特征在于,内存节点的计算能力弱,处理索引更新操作(如B树更新和学习索引模型重训练)性能差,而在内存节点增加更多CPU资源会降低分离式内存系统的可扩展性(计算资源与内存资源无法分开独立扩展)。受XStore工作启发,学习索引空间开销低,能够被全缓存在本地以提供高效率静态查询,但XStore在分离式内存系统中应对动态负载面临巨大挑战,包括:写密集操作效率低下、数据传输带宽过载以及不同节点之间不一致的问题。
研究动机:对于分离式内存架构,能否完全基于学习索引构建一个高效支持动态负载的有序键值存储系统?
2.2设计思路
ROLEX是首个面向分离式内存架构设计、完全基于学习索引实现的RDMA有序键值存储系统,主要有两个特征。
-
第一,内存节点存储键值数据集,完全以机器学习模型(具体采用分段线性回归模型)作为索引结构,而不是传统的树结构。
-
第二,计算节点可以通过简单高效的单边RDMA操作来处理静态和动态数据请求,而不依赖内存节点端计算能力和消耗其计算资源。
对于静态的读请求,ROLEX与XStore类似,每个计算节点在本地缓存学习索引模型用于高效定位目标数据在内存节点的存储地址,然后通过RDMA Read操作获取数据。对于动态请求,计算节点可以将数据插入/修改/删除请求通过一系列单边RDMA操作在内存节点直接完成,而不必重新训练学习索引模型。因此,ROLEX基于学习索引和单边RDMA操作实现了对静态和动态负载的高效支持,具有良好的可扩展性。ROLEX 与 XStore 的不同之处包括应用范围、动态操作效率和内存节点上的索引结构。
| XStore | ROLEX | |
| 应用范围 | 分布式服务器系统,内存节点服务器算力相对充足 | 分离式内存系统,内存节点算力严重不足 |
| 动态操作 | 需要及时训练新模型 | Insert操作与重训练解耦 |
| 内存节点索引 | 树型结构 | 学习索引 |
2.3 关键技术
-
系统架构。在分离式内存系统中,内存节点维护键值对数据的学习索引,value为8B数据或8B指针(如果数据大于8B);计算节点在本地缓存一份学习索引,多个计算节点可以并发访问一个内存节点,如下图所示。
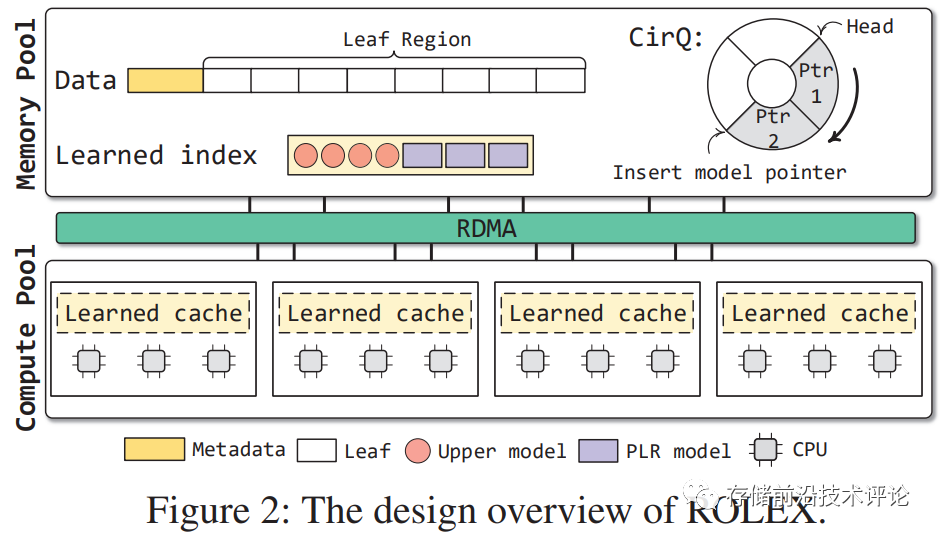
-
关键挑战。在动态负载下,数据插入和删除请求会导致学习索引更新,而实时进行重训练会导致过大的计算开销。因此,关键挑战在于,1) 需要解耦动态请求处理与索引模型重训练,支持异步重训练;2) 需要计算节点能够感知和同步内存节点端发生的索引更新(非重训练),因为不同计算节点都通过单边RDMA操作在内存节点端进行并发数据修改,导致计算节点本地缓存的索引可能是旧版本,需要解决新模型训练过程中多个计算节点并发修改相同地址数据导致的数据不一致性问题。
为解决以上挑战,ROLEX设计了精巧的数据布局和索引结构。下面从叶结点数据布局、学习索引结构、动态请求处理与索引模型重训练解耦的技术思想、以及一致性保证方法几个方面展开介绍。
-
叶子节点数据布局。将存储空间按照叶区域、叶结点的方式组织,一个叶区域对应一块RDMA注册的内存区域(最多可容纳2^48个叶结点),可通过在不同内存节点创建叶区域来实现系统容量扩展(默认最多支持2^7个叶区域);每个叶区域划分为固定大小的叶结点,每个叶结点即一个数组结构(默认包含16个条目),以有序的方式存放键值对数据。
-
学习索引结构。学习索引构建方式是多段线性回归模型,每段线性回归模型记录一段key区间范围内数据所在的多个叶结点位置,由于是有序键值存储,每个叶结点对应一段key子区间范围。由于拟合过程允许一定范围内的误差(即存储位置偏差),因此对于给定key,学习索引输出是覆盖误差范围的一个或多个叶结点(即一片存储位置区域),计算节点会将该区域数据都通过RDMA读到本地,再提取出目标数据。ROLEX的学习索引结构如下图所示。
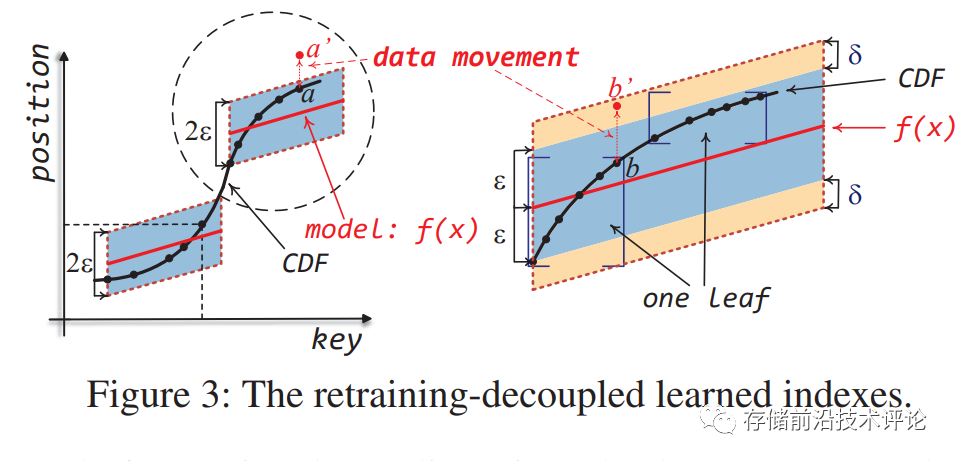
-
动态请求处理与索引模型重训练解耦。ROLEX的一个重要观察是只要未重新训练的模型能够找到所有数据,学习索引就不需要频繁的重新训练。这一观察结果提供了一个机会来绕开模型重训练的计算开销问题,使得新数据无需等待重新训练就被写入内存池。为了实现这个设计目标,ROLEX通过在预测计算中添加偏差(表示为 δ)以及对数据移动添加一些约束,只能在固定大小的叶内移动数据和同义词叶共享,来改进 OptimalPLR 算法。具体而言,允许为每个叶结点动态分配一个缓存区,用于吸收和限定对应key子区间范围内的新数据插入,论文中缓存区的实现方式是同义叶结点(synonym leaf),通过分配一个或多个同义叶结点可以实现缓存区大小的动态配置。每个叶区域内配置固定大小的缓存区域(默认支持2^8个同义叶结点),剩下为叶结点区域,在运行过程中以追加方式在缓存区内为叶结点动态分配同义叶结点。ROLEX的线性回归模型索引包含leaf table (LT)和synonym leaf table (SLT),分别记录叶结点和同义叶结点的存储位置,如下图所示。其中,每个条目包含一个后向指针,将叶结点链接到分配给它的一串同义节点,从而实现对新数据插入位置的限定和寻址;SLT中包含一个当前写入指针(slot_use),指示缓存区已经分配使用的同义节点数量。ROLEX维护一个循环队列来识别要重新训练的模型,并使用影子重定向来同时重新训练模型,而不会阻塞系统。
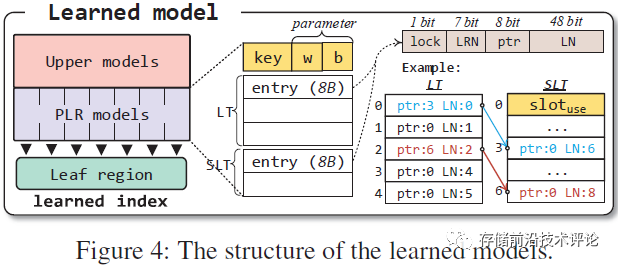
-
动态请求处理过程。当有新键值对插入时,数据会被插入对应子区间的叶结点(假设该结点有足够空闲空间),此时计算节点端缓存的索引能够正确找到该新数据,因为与它key值相匹配的叶结点会被完整读取。假如对应的叶结点没有足够空间容纳新插入数据,那么ROLEX会为该叶结点分配一个新的同义叶结点,并更新内存节点端LT和SLT索引,将它与叶结点链接,并更新SLT中的写入指针。注意到,此时计算节点端缓存的索引成为旧版本,写入指针值落后于内存节点端。计算节点每次访问内存节点时都会将本地缓存的SLT写入指针与内存节点端的值进行比对,如果不一致,说明内存节点端发生过数据插入,此时计算节点先需要读取内存节点端LT和SLT,同步到本地缓存。另外,数据删除请求处理相对插入请求处理较为简单,这里不做详细介绍。
-
一致性保证。在以上处理过程中需要解决多个计算节点在模型重训练的过程中并发修改同一数据导致的不一致性问题。ROLEX利用8B粒度的单边RDMA原子操作(compare-and-swap和fetch-and-add),结合精心设计的数据结构,实现无锁的叶结点分配、叶原子移位、以及一致的叶节点修改(应对数据修改请求),具体技术细节参见论文。
2.4 ROLEX 评估结果
实验在具有 3 个计算节点和 3 个内存节点的集群上运行,该集群配备两个 26 核 Intel Xeon Gold CPU、188GB DRAM 和一个 100Gb Mellanox ConnectX-5 IB RNIC。该研究使用具有均匀请求分布和 Zipfian 请求分布的 YCSB。他们使用 6 个默认工作负载和 4 个其他真实数据集和合成数据集评估了性能。该研究将 ROLEX 与四个最先进的分布式 KV 商店进行了比较:FG、Sherman、EMT-D 和 XStore-D。
-
如原文的图7所示,在 YCSB 中,ROLEX在静态工作负载上展示出了和 XStore-D具有类似竞争力的性能,在动态工作负载上ROLEX展示了更高的吞吐量。
-
由于通过高效的单侧 RDMA 写入来利用学习到的本地缓存,它的性能优于其他方案。
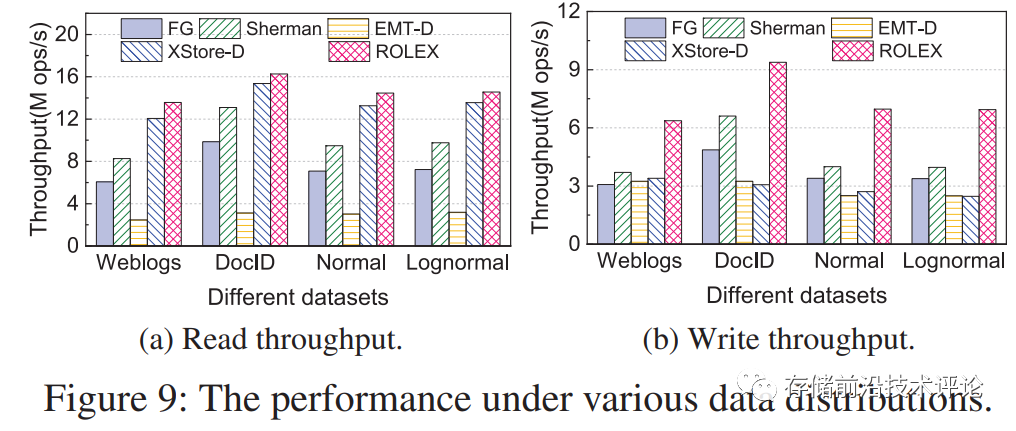
-
如原文的图9所示,对于写负载,ROLEX 由于本地缓存利用和单侧 RDMA 操作,显著提高了其他方案的性能。ROLEX读性能只是略高于XStore-D。
-
ROLEX 在处理各种数据分布时由于提高了模型精度而实现了更高的性能。ROLEX 的可扩展性性能随着计算节点上核心数量的增加而提高,因为不同的线程不会相互阻塞。
-
ROLEX利用操作解耦让计算节点能够直接将数据插入内存池, 并支持过时的模型识别新插入的数据以避免模型失效,从而降低重训练的频率。
-
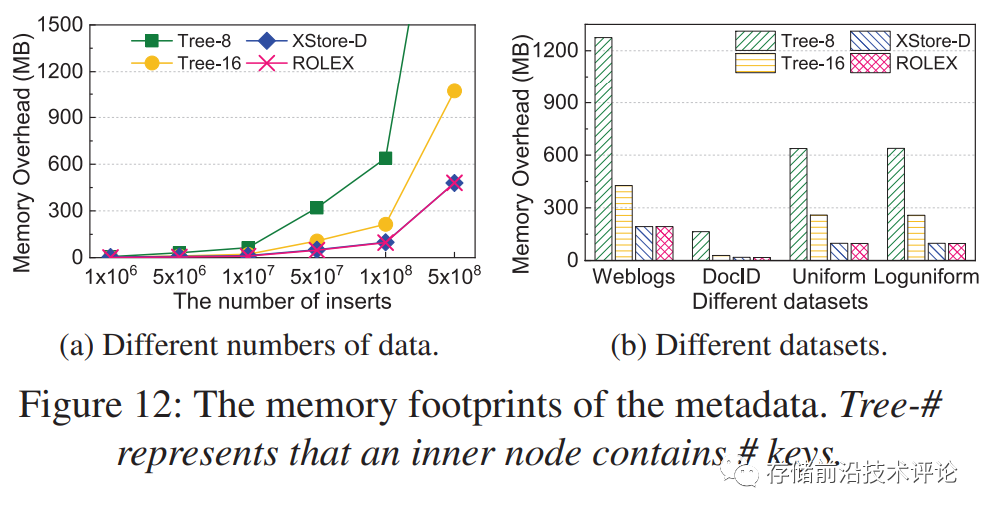
ROLEX 使用单侧索引和异步重新训练来实现高效的系统性能。与基于树的结构相比,ROLEX 的内存占用量随着数据的增加而增加的速度较慢。如原文图12所示,ROLEX的内存开销和XStore-D一样,显著低于基于树的索引结构。
3. 论文评述(存储前沿技术评论原创观点)
3.1 研究的技术壁垒
笔者认为以下三个要素是作者们写出这篇优秀文章的关键:
-
在索引、数据结构领域有十余年的深厚积淀。代表性文章可见作者个人网页。
-
对key-value存储、分布式系统、网络架构、内存节点架构技术有深入理解和直接经验。
-
在基于硬件服务器平台模拟的分离式内存场景下,对XStore进行了复现,开发ROLEX并开源了代码。
3.2 最佳论文的高点
创新性:XStore [6] 首次将学习索引使用到基于RDMA的附网内存KV存储系统,是这个领域开创性的工作。ROLEX面向内存节点算力较弱的分离式内存系统,在内存节点上用学习索引完全取代B树索引,解耦插入和重新训练操作极大优化动态负载性能。对于动态请求,计算节点可以将数据插入/修改/删除请求通过一系列单边RDMA操作在内存节点直接完成,而不必重新训练学习索引模型。尽管文章定位于分离式内存架构,更广的意义上,ROLEX是对基于RDMA的附网内存KV存储系统索引的全面优化。
重要性:这篇文章的重要性体现在多方面。第一,分离式内存应用场景具有新颖性和影响力,RDMA分布式事务、RDMA远程索引数据结构、分离式内存系统、学习索引等主题近年来顶会论文很多。第二,对标的系统XStore很先进,应对的索引问题很困难。该论文提出了一种高效索引操作的解决方案,重要性很高,因为改进索引操作对于增强这些系统的性能至关重要。第三,CXL新架构让内存池、分离式内存等技术的重要性愈发凸显。虽然ROLEX全篇未提及CXL,但是了解CXL概念的研究人员应该能意识到分离式内存技术与CXL技术趋势的关联。
设计感:ROLEX 的设计详细、全面且经过深思熟虑,它不仅解决了分离式内存系统中的挑战,而且确保了对静态和动态工作负载的有效支持。使用再训练解耦学习索引和原子远程空间分配是特别精巧的设计。
3.3 科技写作的艺术
一致性:背景和动机部分阐述当前的学习索引技术对动态工作负载不友好,主要观察是“学习索引在大规模静态工作负载(读,扫描等)上优于基于树的结构,在动态工作负载(插入操作等)下变得效率低下”。设计部分聚焦动态工作负载的优化,主要机制是“构建插入操作和重新训练解耦的学习索引,在内存节点上异步重新训练模型”。评估部分,作者明确“ROLEX 在静态工作负载上展示了具有与XStore-D类似的性能,在动态工作负载上展示了更高的吞吐量”。动态工作负载的挑战、优化、评估高度聚焦,贯穿全文。
层次性:本研究的性能评估部分具有清晰的层次性。从YCSB开始,到补充性的Weblogs、DocID、Normal和Lognormal场景,涵盖了不同的读写模式和数据分布。随后进行了扩展性评估,并对每个设计点进行了详细的breakdown评估,最后进行了开销分析。这种清晰有层次的性能评估无疑是非常有说服力的。
简洁性:作者在文章篇幅上做了取舍,突出核心内容。设计部分写了接近5页,非常扎实。评估部分有3页,虽然篇幅不长,但层次清晰且充分。而测试部分简洁,没有过多的数据堆叠,相关工作也很简短。
参考文献
[1] Decadal Plan for Semiconductors, Semiconductor Research Consortium (SRC), 2021.
[2] Lim, Kevin, et al. "Disaggregated memory for expansion and sharing in blade servers." ISCA 2009.
[3] 联手体系结构专业委员会:“分离式内存”术语发布https://www.ccf.org.cn/Media_list/gzwyh/jsjsysdwyh/2022-03-25/789826.shtml.
[4] Mitchell, Christopher, Yifeng Geng, and Jinyang Li. "Using One-Sided RDMA Reads to Build a Fast, CPU-Efficient Key-Value Store." 2013 USENIX Annual Technical Conference (USENIX ATC 13). 2013.
[5] Kraska, Tim, et al. "The case for learned index structures." Proceedings of the 2018 international conference on management of data (SIGMOD 18). 2018.
[6] Wei, Xingda, Rong Chen, and Haibo Chen. "Fast RDMA-based Ordered Key-Value Store using Remote Learned Cache." 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). 2020.

















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









