










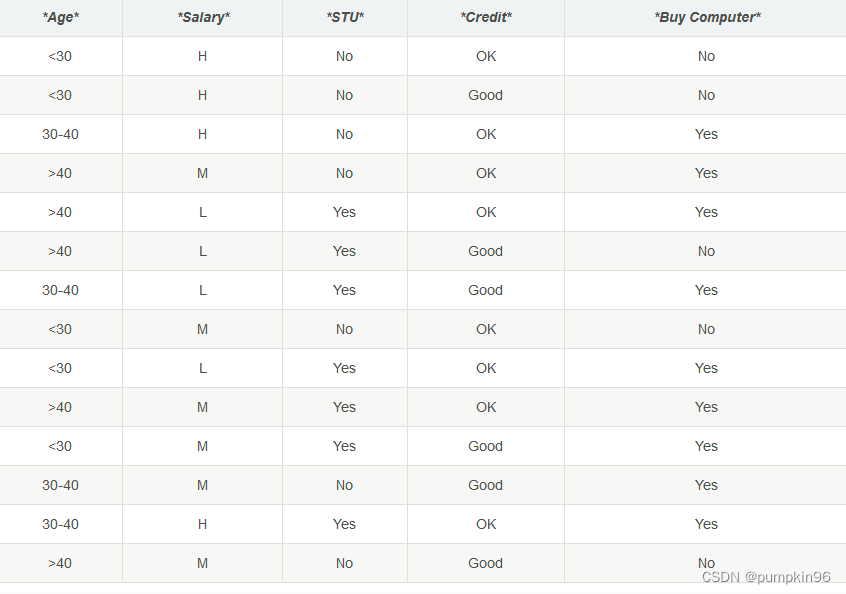
题目:数据集如下图所示,根据我们对决策树的理解,设计一棵决策树,并输入{Age:36,Salary:H,STU:No,Credit:OK} 测试数据,是否与预期结果一致?@注意,不允许直接调用Sklearn提供的决策树方法
-
决策树算法思想
1.使用信息增益选择最佳属性以拆分数据集。
2.使该属性成为决策节点,并将数据集分成较小的子集。
3.通过对每个子节点递归地重复此过程来开始树的构建,直到其中一个条件匹配:- 所有元组都属于相同的属性值。
- 没有更多的剩余属性。
- 没有更多实例了。
数据整理为csv格式
Age,Salary,STU,Credit,BuyComputer
<30,H,No,OK,No
<30,H,No,Good,No
30-40,H,No,OK,Yes
>40,M,No,OK,Yes
>40,L,Yes,OK,Yes
>40,L,Yes,Good,No
30-40,L,Yes,Good,Yes
<30,M,No,OK,No
<30,L,Yes,OK,Yes
>40,M,Yes,OK,Yes
<30,M,Yes,Good,Yes
30-40,M,No,Good,Yes
30-40,H,Yes,OK,Yes
>40,M,No,Good,No
编码实现
from math import log
import pandas as pd
# 计算信息熵
def Ent(dataset):
n = len(dataset)
label_counts = {}
for item in dataset:
label_current = item[-1]
if label_current not in label_counts.keys():
label_counts[label_current] = 0
label_counts[label_current] += 1
ent = 0.0
for key in label_counts:
prob = label_counts[key]/n
ent -= prob * log(prob,2)
return ent
#按照权重计算各分支的信息熵
def sum_weight(grouped,total_len):
weight = len(grouped)/total_len
#print(grouped.iloc[:,-1])
return weight * Ent(grouped.iloc[:,-1])
#根据公式计算信息增益
def Gain(column, data):
lenth = len(data)
ent_sum = data.groupby(column).apply(lambda x:sum_weight(x,lenth)).sum()
ent_D = Ent(data.iloc[:,-1])
return ent_D - ent_sum
# 计算获取最大的信息增益的feature,输入data是一个dataframe,返回是一个字符串
def get_max_gain(data):
max_gain = 0
cols = data.columns[:-1]
for col in cols:
gain = Gain(col,data)
if gain > max_gain:
max_gain = gain
max_label = col
return max_label
#获取data中最多的类别作为节点分类,输入一个series,返回一个索引值,为字符串
def get_most_label(label_list):
return label_list.value_counts().idxmax()
# 创建决策树,传入的是一个dataframe,最后一列为label
def TreeGenerate(data):
feature = data.columns[:-1]
label_list = data.iloc[:, -1]
#如果样本全属于同一类别C,将此节点标记为C类叶节点
if len(pd.unique(label_list)) == 1:
return label_list.values[0]
#如果待划分的属性集A为空,或者样本在属性A上取值相同,则把该节点作为叶节点,并标记为样本数最多的分类
elif len(feature)==0 or len(data.loc[:,feature].drop_duplicates())==1:
return get_most_label(label_list)
#从A中选择最优划分属性
best_attr = get_max_gain(data)
tree = {best_attr: {}}
#对于最优划分属性的每个属性值,生成一个分支
for attr,gb_data in data.groupby(by=best_attr):
print(gb_data)
if len(gb_data) == 0:
tree[best_attr][attr] = get_most_label(label_list)
else:
#在data中去掉已划分的属性
new_data = gb_data.drop(best_attr,axis=1)
#递归构造决策树
tree[best_attr][attr] = TreeGenerate(new_data)
return tree
#使用递归函数进行分类
def tree_predict(tree, data):
feature = list(tree.keys())[0]
label = data[feature]
next_tree = tree[feature][label]
if type(next_tree) == str:
return next_tree
else:
return tree_predict(next_tree, data)
data = pd.read_csv('computer.csv')
#得到经过训练后的决策树
mytree = TreeGenerate(data)
print(mytree)
test_data = {'Age':'30-40','Salary':'H','STU':'No','Credit':'OK'}
predict = tree_predict(mytree,test_data)
print(predict)
实验运行结果
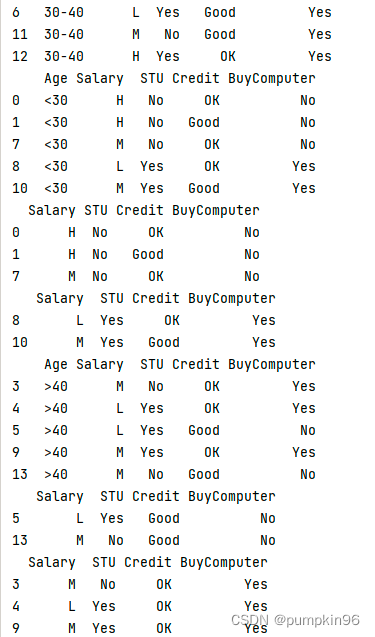
测试结果:

Yes















 6593
6593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









