






>- **🍨 本文为[🔗365天深度学习训练营](https://mp.weixin.qq.com/s/0dvHCaOoFnW8SCp3JpzKxg) 中的学习记录博客**
>- **🍖 原作者:[K同学啊](https://mtyjkh.blog.csdn.net/)**
1. 导入数据
import os, PIL, pathlib
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import models, layers, preprocessing
data_dir = "/Volumes/T7 Shield/code/weather_photos/"
data_dir = pathlib.Path(data_dir)#导入了相关lib和本次需要的dataset
2. 查看数据
image_count = len(list(data_dir.glob("*/*.jpg")))
print(image_count)
roses = list(data_dir.glob("sunrise/*.jpg"))
PIL.Image.open(str(roses[0]))
#out[1]: 1125 (图片总数)
#out[2]: 第一张图片
3. 数据预处理
加载数据:
image_height = 180
image_width = 180
batch_size = 32
train_ds = preprocessing.image_dataset_from_directory(
data_dir,
validation_split = 0.2,
subset = "training",
seed = 42,
image_size = (image_height, image_width),
batch_size = batch_size
)
val_ds = preprocessing.image_dataset_from_directory(
data_dir,
validation_split = 0.2,
subset = "validation",
seed = 42,
image_size = (image_height, image_width),
batch_size = batch_size
)#out[3]:
Found 1125 files belonging to 4 classes.
Using 900 files for training.
Found 1125 files belonging to 4 classes.
Using 225 files for validation.
数据可视化:
class_names = train_ds.class_names
print(class_names)
plt.figure(figsize = (20,10))
for images, labels in train_ds.take(1):
for i in range(20):
plt.subplot(5, 10, i+1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break#out[4]: (32, 180, 180, 3)
(32,)
#和一张图

数据集prefetch:
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size = AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size = AUTOTUNE)4. 搭建模型然后summary一下
classes_num = 4
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape = (image_height, image_width, 3)),
layers.Conv2D(16, (3, 3), activation = "relu", input_shape = (image_height, image_width, 3)),
layers.AveragePooling2D((2,2)),
layers.Conv2D(32, (3, 3), activation = "relu"),
layers.AveragePooling2D((2,2)),
layers.Conv2D(64, (3, 3), activation = "relu"),
layers.Dropout(0.3),
layers.Flatten(),
layers.Dense(128, activation = "relu"),
layers.Dense(classes_num)
])
model.summary()#out[5]:Model: "sequential"
________________________________________________
Layer (type) Output Shape Param #
==============================================
rescaling (Rescaling) (None, 180, 180, 3) 0
conv2d (Conv2D) (None, 178, 178, 16) 448
average_pooling2d (AverageP (None, 89, 89, 16) 0
ooling2D)
conv2d_1 (Conv2D) (None, 87, 87, 32) 4640
average_pooling2d_1 (Averag (None, 43, 43, 32) 0
ePooling2D)
conv2d_2 (Conv2D) (None, 41, 41, 64) 18496
dropout (Dropout) (None, 41, 41, 64) 0
flatten (Flatten) (None, 107584) 0
dense (Dense) (None, 128) 13770880
dense_1 (Dense) (None, 4) 516
==============================================
Total params: 13,794,980
Trainable params: 13,794,980
Non-trainable params: 0
________________________________________________
5. 编译和训练模型:
opt = keras.optimizers.legacy.Adam(learning_rate = 0.001)
model.compile(
optimizer = opt,
loss = keras.losses.SparseCategoricalCrossentropy(from_logits = True),
metrics = ["accuracy"]
)
epoch = 10
history = model.fit(
train_ds,
validation_data = val_ds,
epochs = epoch
)#out[6]:
Epoch 1/10
29/29 [==============================] - 7s 184ms/step - loss: 1.1090 - accuracy: 0.5800 - val_loss: 0.6656 - val_accuracy: 0.7200
Epoch 2/10
29/29 [==============================] - 5s 169ms/step - loss: 0.5341 - accuracy: 0.8044 - val_loss: 0.5162 - val_accuracy: 0.8400
Epoch 3/10
29/29 [==============================] - 5s 171ms/step - loss: 0.4334 - accuracy: 0.8256 - val_loss: 0.4499 - val_accuracy: 0.8356
Epoch 4/10
29/29 [==============================] - 5s 168ms/step - loss: 0.3435 - accuracy: 0.8767 - val_loss: 0.4158 - val_accuracy: 0.8356
Epoch 5/10
29/29 [==============================] - 5s 168ms/step - loss: 0.3020 - accuracy: 0.8722 - val_loss: 0.3915 - val_accuracy: 0.8622
Epoch 6/10
29/29 [==============================] - 5s 164ms/step - loss: 0.2420 - accuracy: 0.9022 - val_loss: 0.4223 - val_accuracy: 0.8622
Epoch 7/10
29/29 [==============================] - 5s 165ms/step - loss: 0.1917 - accuracy: 0.9311 - val_loss: 0.3256 - val_accuracy: 0.8978
Epoch 8/10
29/29 [==============================] - 5s 165ms/step - loss: 0.1495 - accuracy: 0.9500 - val_loss: 0.3683 - val_accuracy: 0.8844
Epoch 9/10
29/29 [==============================] - 5s 165ms/step - loss: 0.1163 - accuracy: 0.9678 - val_loss: 0.4332 - val_accuracy: 0.8578
Epoch 10/10
29/29 [==============================] - 5s 165ms/step - loss: 0.0860 - accuracy: 0.9678 - val_loss: 0.3672 - val_accuracy: 0.8933
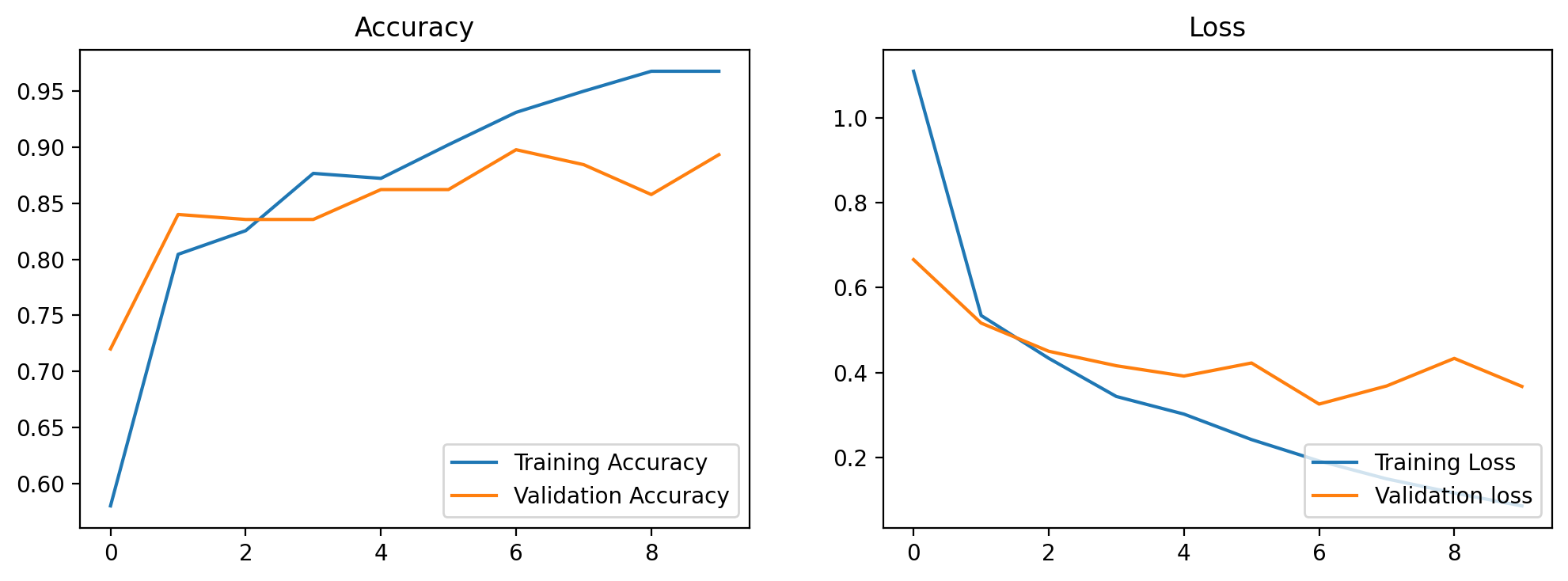
6. 模型评估:
acc = history.history["accuracy"]
valacc = history.history["val_accuracy"]
loss = history.history["loss"]
valloss = history.history["val_loss"]
epoch_range = range(epoch)
plt.figure(figsize = (12, 4))
plt.subplot(1, 2, 1)
plt.plot(epoch_range, acc, label = "Training Accuracy")
plt.plot(epoch_range, valacc, label = "Validation Accuracy")
plt.legend(loc = "lower right")
plt.title("Accuracy")
plt.subplot(1, 2, 2)
plt.plot(epoch_range, loss, label = "Training Loss")
plt.plot(epoch_range, valloss, label = "Validation loss")
plt.legend(loc = "lower right")
plt.title("Loss")
plt.show()
#out[7]:
7. 总结
这次加入了Dropout和数据预处理的部分内容,并且把归一化加在了模型中。而且与之前不同的是把learning rate指定了数值,但是调了两下发现都不如0.001好hhhhh。这次包括refetch和image dataset from directory了解了很多数据预处理的内容,而且一边做一边回顾了之前学过的学习率相关的知识,收获不少。















 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









