由于Clucene对中文的支持很不给力,所以我决定用Xapian,Xapian里的所有东西都是用UTF-8来保存的.
关于Xapian是什么,怎么安装这位兄台讲得不错 http://hi.baidu.com/xapian/blog/item/0229701d87f4708386d6b699.html,我就不复制了。
xapian-bindings我装的是Perl语言接口。
Perl模块Search::Xapian下载下来后手动安装,注意第一步应该指定 XAPIAN_CONFIG:
$ perl Makefile.PL XAPIAN_CONFIG=/opt/bin/xapian-config
Xapian让我崩溃了一整天,编译官网上给我QuickStart程序时可以找到头文件<xapian.h>,但总是说Xapian命名空间中的各种方法都是Undefined reference to xxx,我在/usr/local/lib下确实有xapian的那几个库文件,而且 /usr/local/lib也加到了 /etc/ld.so.conf中。
解决方法,编译时指定lib库:
orisun@zcypc:~$ g++ -o asd -L/usr/local/lib -l xapian a.cc
或者g++ a.cc -o a -lxapian
orisun@zcypc:~$ ./asd
usage: ./asd <path to database> <document data> <document terms>
orisun@zcypc:~$ ./asd info en xapian open
先来了解一下Xapian中的基本概念。
Xapian支持的搜索功能
Xapian允许开发人员轻易地添加高级索引和搜索功能。
它在支持概率论检索模型的同时也支持布尔型操作查询集。
概率性搜索排名--重要的词语会比不那么重要的词语得到更多的权重,因此与权重高的词语关联的Documents会排到结果列表的更前面。
相关度反馈--通过给予一个或多个Documents,Xapian可以显示最相关的Terms以便扩展一个Query,及显示最相关的Documents。
词组和邻近搜索--用户可以搜索一个精确短语或指定数组的词组。
全方位的布尔型搜索器,例如 ("stock NOT market",etc)。
支持提取搜索关键字的词干,例如当搜索“football”的时候,当Documents中含有"footballs"或"footballer"的时候也被认作符合。词干提取器支持很多西文,但很遗憾不支持中文。
支持通配符查询,例如“xap*”。
支持别名查询,打个比方,C++++会自动转为CPlusPlus,C#则自动转为CSharp。
Xapian支持拼写纠正,例如xapain会被纠正为xapian,当然这必须基于词组已经被索引了。
Xapian的存储系统
Xapian现在的版本默认是使用flint作为存储系统,flint是以块的形式来存储,默认每块是8K,理论上每一个文件最大可以达到2048GB。Xapian的Terms和Documents都是使用B-树来存储的,具有增删改查比较方便迅速的特点,缺点则是如果索引被删除后的空间不能重复利用,为了提高性能,通常要经常重建索引。
Xapian的性能
在5亿个网页共1.5TB大小的文件中,搜索只需要小于一秒就完事了。
准确率和召回度
准确率也称为精度,举个例子,一个数据库有500个文档,其中有50个文档符合定义的问题。系统检索到75个文档,但是只有45个符合定义的问题。
召回率R=45/50=90%
精度P=45/75=60%
因此在召回率与准确率中,Web搜索引擎会更倾向于后者,因为终端用户最想得到的他们要想得到的数据,而不是一堆似是而非的数据。但是,对于一个传统的图书信息检索系统,情况会大不相同。
性能
常见的存储方式是将索引和数据(即文章内容)分开存放,以各种树(红黑树、AVL树或B*树)来存储方式问题其实还不大。不过千万别以为IR系统一切都比关系数据库要好,IR系统的其中一个弱点是插入、修改和删除都相对缓慢,因为是中间要经过多层的工序处理,所以IR系统的首要任务是检索,其次才是存储。
在Xapian里,布尔型风格的查询都可以在检索得出documents集合结果后,然后使用概率性的排序。
Xapian默认的排序模式称为BM25Weight,这是一种将词频和document等元素出现的频率通过一个固定的公式得出排序权重的模式,权重越高则相关度越高,如果不想使用BM25Weight作为排序模式,可以使用BoolWeight,BoolWeight模式里的各种元素的权重都为0。
布尔型检索和概率性检索有两种组合的方式:
先用布尔型检索得到所有documents中的某个子集,然后在这个子集中再使用概率性检索。 先进行概率性检索,然后使用布尔型检索过滤查询结果。
如果database里的terms已经添加了前缀,那么可以使用QueryParser的add_prefix方法来设置前缀map。例如QueryParser.add_prefix("subject", "S")这样便将subject映射到S,如果某个term的值为“S标题”,那么可以使用“subject:标题”这样的表达式来检索结果。这时大家可能会记起Google也支持这种语法,例如在Google的搜索栏里输入“Site:www.wlstock.com股票”时,只会检索出www.wlstock.com里的关于股票的网页,这功能其实亦实现了Lucene的Field功能。
Database的存储结构
Xapian的database是所有用于检索的信息表的集合。
必须的表:
+posting_list_table保存了被每一个term索引的document,实际上保存的应该是document在database中的Id,此Id是唯一的。
+record_table保存了每一个document所关联的data,data不能通过query检索,只能通过document来获取。
+ term_list_table 保存了索引每个document的所有的term。
可选的表:
+ position_list_table 保存了每一个Term出现在每一个document中的位置。
+value_table保存了每一个document的values,values是用作保存、排序或其它作用的。
+ spelling_table 保存了拼写纠正的数据。
+ synonym_table 保存术语的字典,例如NBA、C#或C++等。
如果某个特定的term索引了某个特定的document,那么称之为posting。简单来说,一个posting-list可以被认为是一个由document-ids组成的集合,而term-list则是一个字符串组成的集合。在某些IR系统的内部是使用数字来表示term的,因此在这些系统中,term-list则是数字组成的集合,而Xapian则不是这样,它使用原汁原味的term,而使用前缀来压缩存储空间。
Terms不一定是要是document中出现的词语,通常它们会被转换为小写,而且往往它们被词干提取算法处理过。
Values是附加在document上一种元数据,每一个document可以有多个values,这些values通过不同的数字来标识。
词汇表
BM25:优化的概率权重模型。
Quartz:Xapian 1.0以前的数据库格式。
Flint:Xapian 1.0.x的数据库格式。
Chert:Xapian 1.2.x的数据库格式。
Brass:Xapian 1.4以后Brass将取代Chert。
Edit-distance:编辑距离,一个单词变成另一个单词需要改动的字符数。用来推断拼写错误。
ESet (Expand Set):扩展集。是一个terms的排序列表,评价文档的相关程度。
MSet (Match Set):匹配集。按照Document的相关程度排序的列表。
RSet (Relevance Set):相关集。已由用户标记的相关文档。
Normalised-document-length(ndl):规约文档长度。文档长度指它含有的terms的数目。所有文档的平均长度的ndl记为1。
Recall:把文档检索的工作分摊下去。
Stop-word:在索引和检索时被忽略的词,它们太过常见,或没什么实际意义。比如:the,a,to,的。
Term-Prefix:按照惯例,terms都有一个大写字母的前缀,来表示它来自文档的某一个域或表示其他类型的信息。
Within-document frequency (wdf):term在document中出现的次数。
Within-document positions (wdp):term在document中出现的位置。
Within-query-frequency(wqf):term在query中出现的次数。这个统计量在BM25-weighing-scheme中被使用。
UTF-8:一种针对Unicode的可变长度字符编码(定长码),也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。UTF-8用1到6个字节编码UNICODE字符。如果UNICODE字符由2个字节表示,则编码成UTF-8很可能需要3个字节,而如果UNICODE字符由4个字节表示,则编码成UTF-8可能需要6个字节。用4个或6个字节去编码一个UNICODE字符可能太多了,但很少会遇到那样的UNICODE字符。
在了解了Xapian的相关原理后我们给出一个C++ Xapian API的编程实例:
int main(int argc, char **argv) |
cout << "usage: " << argv[0] << " <path to database> <search terms>" << endl; |
Xapian::Database db(argv[1]); |
Xapian::Enquire enquire(db); |
enquire.set_cutoff(90,0.2); |
BM25Weight bm1(1.0,0.0,1.0,0.5,0.3); |
enquire.set_weighting_scheme(bm1); |
Xapian::Query query(Xapian::Query::OP_AND, argv + 2, argv + argc); |
cout << "Performing query `" << query.get_description() << "'" << endl; |
string stop[8]={"的","了","呵","吧","就","你","我","他"}; |
SimpleStopper *ss=new SimpleStopper; |
qparser.set_database(db); |
enquire.set_query(query); |
Xapian::MSet matches = enquire.get_mset(0, 10); |
cout << matches.size() << " results found" << endl; |
for (Xapian::MSetIterator i = matches.begin();i != matches.end(); ++i) { |
Xapian::Document doc = i.get_document(); |
cout << "Document ID " << *i << "\nPercent " <<i.get_percent() << "%\n" << doc.get_data() << "\n" << endl; |
} catch(const Xapian::Error &error) { |
cout << "Exception: " << error.get_msg() << endl; |
运行此程序的前提是我已经用Omega建好了一个索引数据库。

Perl编程实例:
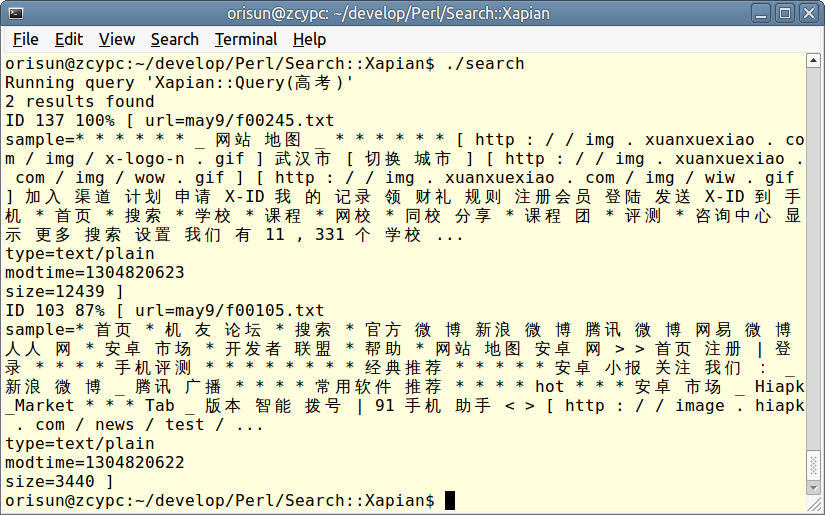
my $db = Search::Xapian::Database->new("/home/orisun/master/db1"); |
my $enq = $db->enquire("高考"); |
printf "Running query '%s'\n", $enq->get_query()->get_description(); |
my @matches = $enq->matches(0, 10); |
print scalar(@matches) . " results found\n"; |
foreach my $match ( @matches ) { |
my $doc = $match->get_document(); |
printf "ID %d %d%% [ %s ]\n", $match->get_docid(), $match->get_percent(), $doc->get_data(); |






















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









