






高斯混合模型介绍
高斯混合模型(Gaussian Mixture Model)通常简称GMM,是一种业界广泛使用的聚类算法,该方法使用了高斯分布作为参数模型,并使用了**期望最大(Expectation Maximization,简称EM)**算法进行训练。
混合高斯背景建模是基于像素样本统计信息的背景表示方法。
对于视频图像中的每一个像素点,其值在序列图像中的变化可看作是不断产生像素值的随机过程,可以用高斯分布来模拟像素值的变化规律。由于混合高斯模型理论上可以拟合任何一种分布,所以用GMM建模效果较好。
图像的每一个像素点按不同权值的多个高斯分布的叠加来建模,各个高斯分布的权值和分布参数随时间更新。
GMM的参数包括:高斯混合系数、均值、方差
毕设项目演示地址: 链接
毕业项目设计代做项目方向涵盖:
目标检测、语义分割、深度估计、超分辨率、3D目标检测、CNN、GAN、目标跟踪、自动驾驶、人群密度估计、PyTorch、人脸、车道线检测、去雾 、全景分割、行人检测、文本检测、OCR、6D姿态估计、 边缘检测、场景文本检测、视频实例分割、3D点云、模型压缩、人脸对齐、超分辨、去噪、强化学习、行为识别、OpenCV、场景文本识别、去雨、机器学习
背景提取流程
与标准的GMM聚类过程有所区别:聚类参考《机器学习\29_k-means和GMM的区别与联系.md》
-
为图像中的每个像素点,初始化一个高斯混合模型的参数。K个高斯模型,各有三个参数:高斯混合系数 w w w、均值 μ \mu μ、方差 σ 2 \sigma^2 σ2。
-
计算新像素值 X t X_t Xt是否属于第 k k k个高斯分布(属于即视为匹配成功,可存在多组匹配成功)。判断方法:其与高斯模型的均值偏差在 2.5 σ 2.5\sigma 2.5σ内。
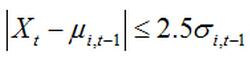
-
如果存在匹配成功的高斯分布,那么该像素值就属于背景,否则为前景。
-
更新高斯混合系数 w w w,其中 α \alpha α为学习率。对于匹配的模式 M k , t = 1 , M_k,t=1, Mk,t=1,否则 M k , t = 0 M_k,t=0 Mk,t=0。
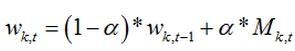
上面公式的含义:对于匹配成功的高斯分布,加大其系数,因为该分布更能反映背景像素分布;对于匹配失败的高斯分布,减少其系数,说明该高斯分布已经不能准确表达背景信息了。
更新以后需要重新对 w w w归一化,确保混合高斯分布的最大值为1
-
未匹配成功的高斯模型不做更新,匹配成功的高斯模型根据 X t X_t Xt更新参数 μ \mu μ和 σ 2 \sigma^2 σ2。
E 步: 固定 μ 和 σ ,计算属于每一类的概率 ρ = w k , t ∗ η ( X t ∣ μ k , σ k ) M 步: 固定 ρ ,更新 μ 和 σ μ t = ( 1 − ρ ) ∗ μ t − 1 + ρ ∗ X t σ t 2 = ( 1 − ρ ) ∗ σ t − 1 2 + ρ ∗ ( X t − μ t ) T ( X t − μ t ) \begin{aligned} E步:&固定\mu和\sigma,计算属于每一类的概率\\ \rho&=w_{k,t}*\eta\left(X_{t} \mid \mu_{k}, \sigma_{k}\right) \\ M步:&固定\rho,更新\mu和\sigma\\ \mu_{t}&=(1-\rho) * \mu_{t-1}+\rho^{*} X_{t} \\ \sigma_{t}^{2}&=(1-\rho)^{*} \sigma_{t-1}^{2}+\rho^{*}\left(X_{t}-\mu_{t}\right)^{T}\left(X_{t}-\mu_{t}\right) \end{aligned} E步:ρM步:μtσt2固定μ和σ,计算属于每一类的概率=wk,t∗η(Xt∣μk,σk)固定ρ,更新μ和σ=(1−ρ)∗μt−1+ρ∗Xt=(1−ρ)∗σt−12+ρ∗(Xt−μt)T(Xt−μt)
ρ \rho ρ为当前数据属于某个高斯分布的概率,利用该概率进行滑动平均更新均值和方差。 -
如果不存在匹配成功的高斯模型,即该点为前景,就直接去除 w w w最小的高斯模型,然后添加一个新的高斯模型,其均值为 X t X_t Xt,标准差初始化为较大的值,高斯混合系数 w w w初始化为较小的值。
此时高斯模型的总数是不变的。
-
各模式根据 w / σ 2 w/{\sigma ^2} w/σ2按降序排列,权重大、标准差小的模式排列在前。
-
选前B个模式作为背景,B满足下式,参数T表示背景所占的比例:
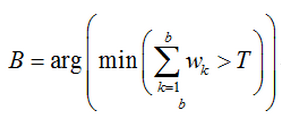
7、8的主要目的是:防止刚加入的前景立刻作为背景模板,这样下一帧的该位置会立马变成背景,前景检测就不稳定了;该步骤保证了当新加入的高斯模型在更新了一次次数后才加入背景模板,保证了背景的稳定性,同时也具有背景适应环境变化的特点
与GMM聚类的区别在于:
- 聚类需要利用所有的样本更新。背景提取需要一个样本更新。
- 聚类需要计算每个样本属于每个高斯分布的概率。背景提取只需要判断新的点属于哪个高斯分布即可。
- 聚类不需要学习率来更新高斯混合系数。背景提取需要学习率单独更新混合系数。
- 聚类利用所有的样本更新每一个高斯分布。背景提取只用新样本更新匹配成功的高斯模型。
- 聚类不会剔除高斯模型,只会不断更新每一个高斯模型。背景提取会逐步剔除混合系数最小的分布,然后生成新的高斯模型加入GMM,正因如此,GMM可以适应缓慢的光线变化。


















 561
561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











